With recent enhancements to PowerScale healthchecks and CELOG events, it was discovered that an often more than desirable quantity of alerts were being sent to customers and Dell support. Many of these alerts were relatively benign, and sometimes consumed a non-trivial amount of system and human resources. As such, an overly chatty monitoring system can run the risk of noise fatigue, and the potential to miss a critical alert.
Included in the OneFS 9.9 payload is a new ‘superfluous alert suppression’ feature. The goal of this new functionality is to reduce the transmission of unnecessary alerts to both cluster administrators and Dell support. To this end, two new event categories are introduced in OneFS 9.9:
| Category | ID | Description |
| DELL_SUPPORT | 9900000000 | Only events in DELL_SUPPORT will be sent to Dell support. |
| SYSTEM_ADMIN | 9800000000 | Events in SYSTEM_ADMIN will be sent to the cluster admin by default |
With these new event categories and CELOG enhancements, any ‘informational’ (non-critical) events will no longer trigger an alert by default. As such, only warning, critical, and emergency events that include ‘DELL_SUPPORT’ will now be sent to Dell. Similarly, just warning, critical, and emergency events in ‘SYSTEM_ADMIN’ will be sent to the cluster admin by default.
Under the hood, OneFS superfluous alert suppression leverages the existing CELOG reporting mechanism to filter out alerts generation by providing stricter alerting rules.
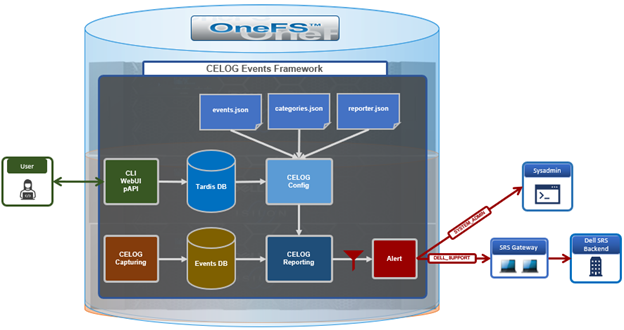
Architecturally, CELOG captures events and stores them in its event database. From here, the reporting service parses the inbound events and fires alerts as needed to the cluster administrator and/or Dell support. CELOG uses Tardis for its configuration management, and changes are received from the user interface and forwarded to the Tardis configuration service and database by the platform API handlers. Additionally, CELOG uses a series of JSON config files to store its event, category, reporting, and alerting rules.
When a new event is captured, the reporting module matches the event with the reporting rules and sends out an alert if the condition is met. In OneFS 9.9, the CELOG workflow is not materially changed. Rather, filtering is applied by applying more stringent reporting rules, resulting in the transmission of fewer but more important alerts.
The newly introduced ‘Dell Support’ (ID: 99000000000) and ‘System Admin’ (ID: 9800000000) categories and their associated IDs are described in the ‘/etc/celog/categories.json’ file as follows:
"9800000000": {
"id": "9800000000",
"id_name": "SYSTEM_ADMIN",
"name": "System Admin events"
},
"9900000000": {
"id": "9900000000",
"id_name": "DELL_SUPPORT",
"name": "Dell Support events"
},
Similarly, the event configurations in the /etc/celog/events.json config file now contain both ‘dell_support_category’ and ‘system_admin_category’ boolean parameters for each event type, which can be set to either ‘true’ or ‘false’:
"100010001": {
"attachments": [
"dfvar",
"largevarfiles",
"largelogs"
],
"category": "100000000",
"frequency": "10s",
"id": "100010001",
"id_name": "SYS_DISK_VARFULL",
"name": "The /var partition is near capacity (>{val:.1f}% used)",
"type": "node",
"dell_support_category": true,
"system_admin_category": true
},
The reporter file, /etc/celog/celog.reporter.json, also sees updated predefined alerting rules in OneFS 9.9. Specifically, the ‘categories’ field is no longer set to ‘all’. Instead, the category ID is specified. Also, a new ‘severities’ field now specifies the criticality level – ‘warning’, ‘critical’, and ‘emergency’. For example below, only events with ‘warning’ and above will be sent to the defined call-home channel, in this case ID 9000000000, indicating Dell support:
"SupportAssist New": {
"condition": "NEW",
"channel_ids": [3],
"name": "SupportAssist New",
"eventgroup_ids": [],
"categories": ["9900000000"],
"severities" : ["warning", "critical", "emergency"],
"limit": 0,
"interval": 0,
"transient": 0
},
When creating new custom alert rules in OneFS 9.9, the category and severity alerting fields will automatically default to ‘SYSTEM_ADMIN’ and ‘warning’, ‘critical’, and ‘emergency’. For example from the CLI:
# isi event alerts create <name> \ <condition> \ <channel> \ --category SYSTEM_ADMIN \ --severity=warning,critical,emergency
Similarly via the WebUI under Cluster management >Events and alerts > Alert management > Create alert rule:
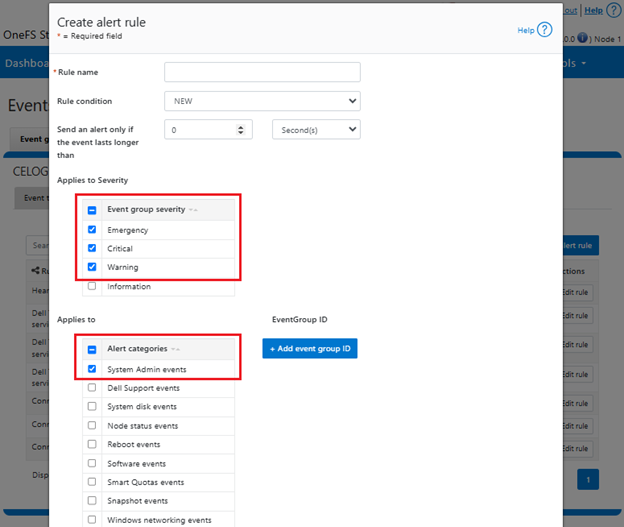
By applying these changes to the configuration and alerting rules, and without modifying the CELOG infrastructure at all, this new functionality can significantly reduce the quantity, while increasing the quality and relevance, of OneFS alerts that both customers and support receive.
Alert and event definitions and rules can be viewed per category from the CLI as follows, which can be useful for investigative and troubleshooting purposes:
# isi event alerts view "SupportAssist New" Name: Dell Technologies connectivity services New Eventgroup: - Category: 9900000000 Sev: ECW Channel: Dell Technologies connectivity services Condition: NEW
Note that the ‘severity’ (Sev) field contains the value ‘ECW’, which translates to emergency, critical, and warning.
Also, the event types that are included in each category can be easily viewed from the CLI. For example, the event types associated with the SYSTEM_ADMIN category:
# isi event types list --category=9800000000
ID Name Category Description
100010001 SYS_DISK_VARFULL 100000000 The /var partition is near capacity (>{val:.1f}% used)
100010002 SYS_DISK_VARCRASHFULL 100000000 The /var/crash partition is near capacity ({val:.1f}% used)
100010003 SYS_DISK_ROOTFULL 100000000 The /(root) partition is near capacity ({val:.1f}% used)
100010005 SYS_DISK_SASPHYTOPO 100000000 A SAS PHY topology problem or change was detected on {chas}, location {location}
100010006 SYS_DISK_SASPHYERRLOG 100000000 A drive's error log counter indicates there may be a problem on {chas}, location {location}
100010007 SYS_DISK_SASPHYBER 100000000 The SAS link connected to {chas} {exp} PHY {phy} has exceeded the maximum Bit Error Rate (BER)
And similarly for the DELL_SUPPORT category:
# isi event types list --category=9900000000
ID Name Category Description
100010001 SYS_DISK_VARFULL 100000000 The /var partition is near capacity (>{val:.1f}% used)
100010002 SYS_DISK_VARCRASHFULL 100000000 The /var/crash partition is near capacity ({val:.1f}% used)
100010003 SYS_DISK_ROOTFULL 100000000 The /(root) partition is near capacity ({val:.1f}% used)
100010006 SYS_DISK_SASPHYERRLOG 100000000 A drive's error log counter indicates there may be a problem on {chas}, location {location}
100010007 SYS_DISK_SASPHYBER 100000000 The SAS link connected to {chas} {exp} PHY {phy} has exceeded the maximum Bit Error Rate
(BER)
100010008 SYS_DISK_SASPHYDISABLED 100000000 The SAS link connected to {chas} {exp} PHY {phy} has been disabled for exceeding the maximum Bit Error Rate (BER)
While the automatic superfluous alert suppression functionality described above is new in OneFS 9.9, manual alert suppression has been available since OneFS 9.4:
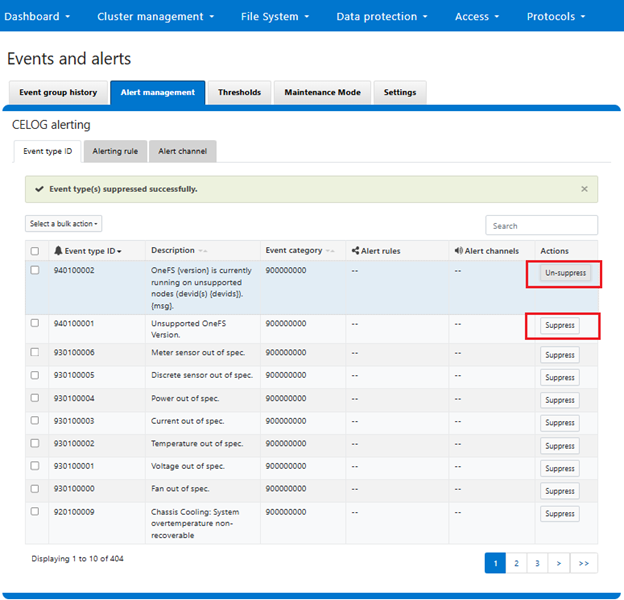
Here, filtering logic in the CELOG framework allows individual event types to be easily be suppressed (and un-suppressed) as desired, albeit manually.
Additionally, OneFS also provides a ‘maintenance mode’ for temporary cluster-wide alert suppression during either a scheduled or ad-hoc maintenance window. For example:
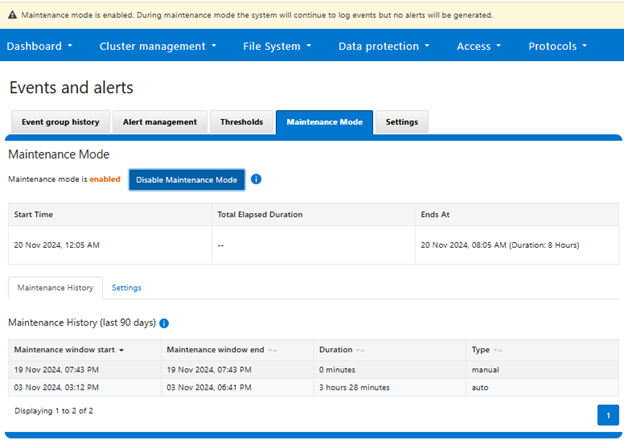
When enabled, OneFS will continue to log events, but no alerts will be generated until the maintenance period either ends or is disabled. CELOG will automatically resume alert generation for active event groups as soon as the maintenance period concludes.
We’ll explore OneFS maintenance mode further in the next blog article.