OneFS file filtering enables a cluster administrator to either allow or deny access to files based on their file extensions. This allows the immediate blocking of certain types of files that might cause security issues, content licensing violations, throughput or productivity disruptions, or general storage bloat. For example, the ability to universally block an executable file extension such as ‘.exe’ after discovery of a software vulnerability is undeniably valuable.
File filtering in OneFS is multi-protocol, with support for SMB, NFS, HDFS and S3 at a per-multi-tenant access zone granularity. It also includes default share and per share level configuration for SMB, and specified file extensions can be instantly added or removed if the restriction policy changes.
Within OneFS, file filtering has two basic modes of operation:
- Allow file writes
- Deny file writes
In allow rights mode, an inclusion list specifies the file types by extension which can be written. In this example, OneFS only permits mp4 files, blocking all other file types.
# isi file-filter settings modify --file-filter-type allow --file-filter-extensions .mp4 # isi file-filter settings view Enabled: Yes File Filter Extensions: mp4 File Filter Type: allow
In contrast, with deny writes configured, an exclusion list specifies file types by extension which are denied from being written. OneFS permits all other file types to be written.
# isi file-filter settings modify --file-filter-type deny --file-filter-extensions .txt # isi file-filter settings view Enabled: Yes File Filter Extensions: txt File Filter Type: deny
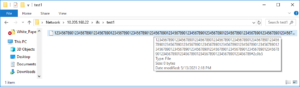
For example, with the configuration above, OneFS denies all other file types than ‘.txt’ from being written to the share, as shown in the following Windows client CMD shell output.
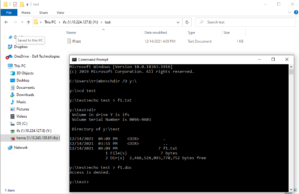
Note that preexisting files with filtered extensions on the cluster are still be able to read or deleted, but not appended.
Additionally, file filtering can also be configured when creating or modifying a share via the ‘isi smb shares create’ or ‘isi smb shares modify’ commands.
For example, the following CLI syntax enables file filtering on a share named ‘prodA’ and denies writing ‘.wav’ and ‘.mp3’ file types:
# isi smb shares create prodA /ifs/test/proda --file-filtering-enabled=yes --file-filter-extensions=.wav,.mp3
Similarly, to enable file filtering on a share named ‘prodB’ and allow writing only ‘.xml’ files:
# isi smb shares modify prodB --file-filtering-enabled=yes --file-filter-extensions=xml --file-filter-type=allow
Note that if a preceding ‘.’ (dot character) is omitted from a ‘–file-filter-extensions’ argument, the dot will automatically be added as a prefix to any file filter extension specified. Also, up to 254 characters can be used to specify a file filter extension.
Be aware that characters such as ‘*’ and ‘?’ are not recognized as ‘wildcard’ characters in OneFS file filtering and cannot be used to match multiple extensions. For example, the file filter extension ‘mp*’ will match the file f1.mp*, but not f1.mp3 or f1.mp4, etc.
A previous set of file extensions can be easily removed from the filtering configuration as follows:
# isi file-filter settings modify --clear-file-filter-extensions
File filtering can also be configured to allow or deny file writes based on file type at a per-multi-tenant access zone level, limiting filtering rules exclusively to files in the specified zone. OneFS does not take into consideration which file sharing protocol was used to connect to the multi-tenant access zone when applying file filtering rules. However, additional file filtering can be applied at the SMB share level.
The ‘isi file-filter settings modify’ command can be used to enable file filtering per multi-tenant access zone and specify which file types users are denied or allowed write access. For example, the following CLI syntax enables file filtering in the ‘az3’ zone and only allows users to write html and xml file types:
# isi file-filter settings modify --zone=az3 --enabled=yes --file-filter-type=allow --file-filter-extensions=.xml,.html
Similarly, the following command prevents writing pdf, txt, and word files in zone ‘az3’:
# isi file-filter settings modify --zone=az3 --enabled=yes --file-filter-type=deny --file-filter-extensions=.doc,.pdf,.txt
The file filtering settings in a multi-tenant access zone can be confirmed by running the ‘isi file-filter settings view’ command. For example, the following syntax displays file filtering config in the az3 multi-tenant access zone:
# isi file-filter settings view --zone=az3 Enabled: Yes File Filter Extensions: doc, pdf, txt File Filter Type: deny
For security post-mortem and audit purposes, file filtering events are written to /var/log/lwiod.log at the ‘verbose’ log level. The following CLI commands can be used to configure the lwiod.log level:
# isi smb log-level view Current logging level: 'info' # isi smb log-level modify verbose # isi smb log-level view Current logging level: 'verbose'
For example, the following entry is logged when unsuccessfully attempting to create file /ifs/test/f1.txt from a Windows client with ‘txt’ file filtering enabled:
# grep -i "f1.txt" /var/log/lwiod.log 2021-12-15T19:34:04.181592+00:00 <30.7> isln1(id8) lwio[6247]: Operation blocked by file filtering for test\f1.txt
After enabling file filtering, you can confirm that the filter drivers are running via the following command:
# /usr/likewise/bin/lwsm list * | grep -i 'file_filter' flt_file_filter [filter] running (lwio: 6247) flt_file_filter_hdfs [filter] running (hdfs: 35815) flt_file_filter_lwswift [filter] running (lwswift: 6349) flt_file_filter_nfs [filter] running (nfs: 6350)
When disabling file filtering, previous settings that specify filter type and file type extensions are preserved but no longer applied. For example, the following command disables file filtering in the az3 multi-tenant access zone but retains the type and extensions configuration:
# isi file-filter settings modify --zone=az3 --enabled=no # isi file-filter settings view Enabled: No File Filter Extensions: html, xml File Filter Type: deny
When disabled, the filter drivers will no longer be running:
# /usr/likewise/bin/lwsm list * | grep -i 'file_filter' flt_file_filter [filter] stopped flt_file_filter_hdfs [filter] stopped flt_file_filter_lwswift [filter] stopped flt_file_filter_nfs [filter] stopped