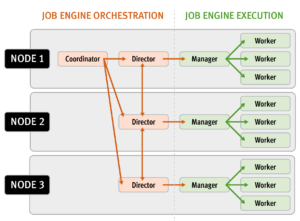
The majority of the OneFS job engine’s jobs have no default schedule and are typically manually started by a cluster administrator or process. Other jobs such as FSAnalyze, MediaScan, ShadowStoreDelete, and SmartPools, are normally started via a schedule. The job engine can also initiate certain jobs on its own. For example, if the SnapshotIQ process detects that a snapshot has been marked for deletion, it will automatically queue a SnapshotDelete job.
The Job Engine will also execute jobs in response to certain system event triggers. In the case of a cluster group change, for example the addition or subtraction of a node or drive, OneFS automatically informs the job engine, which responds by starting a FlexProtect job. The coordinator notices that the group change includes a newly-smart-failed device and then initiates a FlexProtect job in response.
Job administration and execution can be controlled via the WebUI, CLI, or platform API and a job can be started, stopped, paused and resumed, and this is managed via the job engines’ check-pointing system. For each of these control methods, additional administrative security can be configured using roles-based access control (RBAC).
The job engine’s impact control and work throttling mechanism is able to limit the rate at which individual jobs can run. Throttling is employed at a per-manager process level, so job impact can be managed both granularly and gracefully.
Every twenty seconds, the coordinator process gathers cluster CPU and individual disk I/O load data from all the nodes across the cluster. The coordinator uses this information, in combination with the job impact configuration, to decide how many threads may run on each cluster node to service each running job. This can be a fractional number, and fractional thread counts are achieved by having a thread sleep for a given percentage of each second.
Using this CPU and disk I/O load data, every sixty seconds the coordinator evaluates how busy the various nodes are and makes a job throttling decision, instructing the various job engine processes as to the action they need to take. This enables throttling to be sensitive to workloads in which CPU and disk I/O load metrics yield different results. Additionally, there are separate load thresholds tailored to the different classes of drives utilized in OneFS powered clusters, from capacity optimized SATA disks to flash-based SSDs.
However, up through OneFS 9.2, a job engine job was an all or nothing entity. Whenever a job ran, it involved the entire cluster – regardless of individual node type, load, or condition. As such, any nodes that were overloaded or in a degraded state could still impact the execution ability of the job at large.
To address this, OneFS 9.3 provides the capability to exclude one or more nodes from participating in running a job. This allows the temporary removal of any nodes with high load, or other issues, from the job execution pool so that jobs do not become stuck. Configuration is via the OneFS CLI and gconfig and is global, such that it applies to all jobs on startup. However, the exclusion configuration is not dynamic, and once a job is started with the final node set, there is no further reconfiguration permitted. So if a participant node is excluded, it will remain excluded until the job has completed. Similarly, if a participant needs to be excluded, the current job will have to be cancelled and a new job started. Any nodes can be excluded, including the node running the job engine’s coordinator process. The coordinator will still monitor the job, it just won’t spawn a manager for the job.
The list of participating nodes for a job are computed in three phases:
- Query the cluster’s GMP group.
- Call to job.get_participating_nodes to get a subset from the gmp group
- Remove the nodes listed in core.excluded_participants from the subset.
The CLI syntax for configuring an excluded nodes list on a cluster is as follows (in this example, excluding nodes one through three):
# isi_gconfig –t job-config core.excluded_participants="{1,2,3}"
The ‘excluded_participants’ are entered as a comma-separated devid value list with no spaces, specified within parentheses and double quotes.
Note that it is the node’s device ID (devid) which is required in the above command, and this is not always the same as the node number (LNN). The following command will report both the LNN and corresponding devid:
# isi_nodes %{lnn} , %{id}
All excluded nodes must be specified in full, since there’s no aggregation. Note that, while the excluded participant configuration will be displayed via gconfig, it is not reported as part of the ‘sysctl efs.gmp.group’ output.
A job engine node exclusion configuration can be easily reset to avoid excluding any nodes by assigning the “{}” value.
# isi_gconfig –t job-config core.excluded_participants="{}"
A ‘core.excluded_participant_percent_warn’ parameter defines the maximum percentage of removed nodes.
# isi_gconfig -t job-config core.excluded_participant_percent_warn core.excluded_participant_percent_warn (uint) = 10
This parameter defaults to 10%, above which a CELOG event warning is generated.
As many nodes as desired can be removed from the job group. CELOG informational event will notify of removed nodes. If too many nodes have been removed, (gconfig parameter sets too many node threshold) CELOG will fire a warning event. If some nodes are removed but they’re not part of the GMP group, a different warning event will trigger.
If all nodes are removed, a CLI/pAPI error will be returned, the job will fail, and a CELOG warning will fire. For example:
# isi job jobs start LinCount Job operation failed: The job had no participants left. Check core.excluded_participants setting and make sure there is at least one node to run the job: Invalid argument # isi job status 10 LinCount Failed 2021-10-24T:20:45:23 ------------------------------------------------------------------ Total: 9
Note, however, that the following core system maintenance jobs will continue to run across all nodes in a cluster even if a node exclusion has been configured:
- AutoBalance
- Collect
- FlexProtect
- MediaScan
- MultiScan