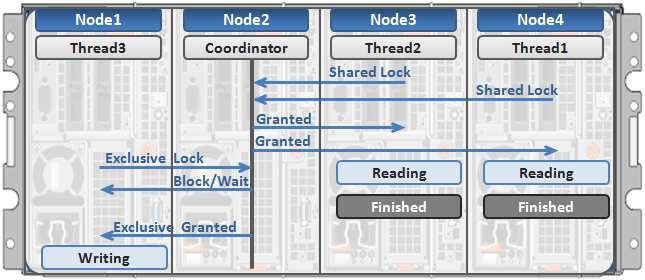
In the previous blog article we took a look at write locking and shared access in OneFS. Next, we’ll delve another layer deeper into OneFS concurrent file access.
The OneFS locking hierarchy also provides a mechanism called Multi-writer, which allows a cluster to support concurrent writes from multiple client writer threads to the same file. This granular write locking is achieved by sub-diving the file into separate regions and granting exclusive data write locks to these individual ranges, as opposed to the entire file. This process allows multiple clients, or write threads, attached to a node to simultaneously write to different regions of the same file.
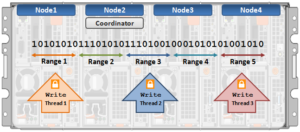
Concurrent writes to a single file need more than just supporting data locks for ranges. Each writer also needs to update a file’s metadata attributes such as timestamps, block count, etc. A mechanism for managing inode consistency is also needed, since OneFS is based on the concept of a single inode lock per file.
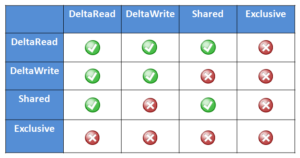
In addition to the standard shared read and exclusive write locks, OneFS also provides the following locking primitives, via journal deltas, to allow multiple threads to simultaneously read or write a file’s metadata attributes:
OneFS Lock Types include:
Exclusive: A thread can read or modify any field in the inode. When the transaction is committed, the entire inode block is written to disk, along with any extended attribute blocks.
Shared: A thread can read, but not modify, any inode field.
DeltaWrite: A thread can modify any inode fields which support delta-writes. These operations are sent to the journal as a set of deltas when the transaction is committed.
DeltaRead: A thread can read any field which cannot be modified by inode deltas.
These locks allow separate threads to have a Shared lock on the same LIN, or for different threads to have a DeltaWrite lock on the same LIN. However, it is not possible for one thread to have a Shared lock and another to have a DeltaWrite. This is because the Shared thread cannot perform a coherent read of a field which is in the process of being modified by the DeltaWrite thread.
The DeltaRead lock is compatible with both the Shared and DeltaWrite lock. Typically the file system will attempt to take a DeltaRead lock for a read operation, and a DeltaWrite lock for a write, since this allows maximum concurrency, as all these locks are compatible.
Here’s what the write lock incompatibilities looks like:
OneFS protects data by writing file blocks (restriping) across multiple drives on different nodes. The Job Engine defines a ‘restripe set’ comprising jobs which involve file system management, protection and on-disk layout. The restripe set contains the following jobs:
- AutoBalance & AutoBalanceLin
- FlexProtect & FlexProtectLin
- MediaScan
- MultiScan
- SetProtectPlus
- SmartPools
- Upgrade
Multi-writer for restripe allows multiple restripe worker threads to operate on a single file concurrently. This in turn improves read/write performance during file re-protection operations, plus helps reduce the window of risk (MTTDL) during drive Smartfails, etc. This is particularly true for workflows consisting of large files, while one of the above restripe jobs is running. Typically, the larger the files on the cluster, the more benefit multi-writer for restripe will offer.
Note that OneFS multi-writer ranges are not a fixed size and instead tied to layout/protection groups. So typically in the megabytes size range. The number of threads that can write to the same file concurrently, from the filesystem perspective, is only limited by file size. However, NFS file handle affinity (FHA) comes into play from the protocol side, and so the default is typically eight threads per node.
The clients themselves do not apply for granular write range locks in OneFS, since multi-writer operation is completely invisible to the protocol. Multi-writer uses proprietary locking which OneFS performs to coordinate filesystem operations. As such, multi-writer is distinct from byte-range locking that application code would call, or even oplocks/leases which the client protocol stack would call.
Depending on the workload, multi-writer can improve performance by allowing for more concurrency, and (while typically on by default in recent releases) can be enabled on a cluster from the CLI as follows:
# isi_sysctl_cluster efs.bam.coalescer.multiwriter=1
Similarly, to disable multi-writer:
# isi_sysctl_cluster efs.bam.coalescer.multiwriter=0
Note that, as a general rule, unnecessary contention should be avoided. For example:
- Avoid placing unrelated data in the same directory: Use multiple directories instead. Even if it is related, split it up if there are many entries.
- Use multiple files: Even if the data is ultimately related, from a performance/scalability perspective, having each client use its own file and then combining them as a final stage is the correct way to architect for performance.
With multi-writer for restripe, an exclusive lock is no longer required on the LIN during the actual restripe of data. Instead, OneFS tries to use a delta write lock to update the cursors used to track which parts of the file need restriping. This means that a client application or program should be able to continue to write to the file while the restripe operation is underway.
An exclusive lock is only required for a very short period of time while a file is set up to be restriped. A file will have fixed widths for each restripe lock, and the number of range locks will depend on the quantity of threads and nodes which are actively restriping a single file.