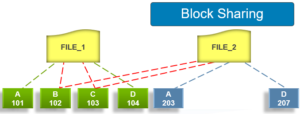
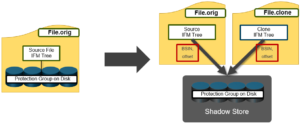
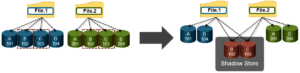
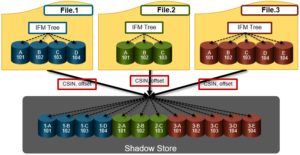
As we saw in the previous article in this series, SmartDedupe operates at the directory level, targeting all files and directories underneath one or more root directories.
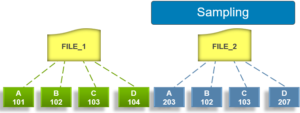
SmartDedupe not only deduplicates identical blocks in different files, it also matches and shares identical blocks within a single file. For two or more files to be deduplicated, the two following attributes must be the same:
- Disk pool policy ID
- Protection policy
If either of these attributes differs between two or more matching files, their common blocks will not be shared. SmartDedupe also does not deduplicate files that are less than 32 KB or smaller, because the resource consumption overhead outweighs the small storage efficiency benefit.
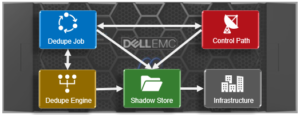
There are two principal elements to managing deduplication in OneFS. The first is the configuration of the SmartDedupe process itself. The second involves the scheduling and execution of the Dedupe job. These are both described below.
SmartDedupe works on data sets which are configured at the directory level, targeting all files and directories under each specified root directory. Multiple directory paths can be specified as part of the overall deduplication job configuration and scheduling.
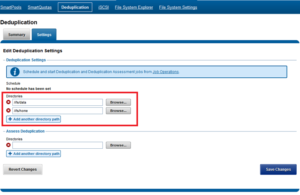
Similarly, the dedupe directory paths can also be configured from the CLI via the isi dedupe settings modify command. For example, the following command targets /ifs/data and /ifs/home for deduplication:
# isi dedupe settings modify --paths /ifs/data, /ifs/home
Bear in mind that the permissions required to configure and modify deduplication settings are separate from those needed to run a deduplication job. For example, a user’s role must have job engine privileges to run a deduplication job. However, in order to configure and modify dedupe configuration settings, they must have the deduplication role privileges.
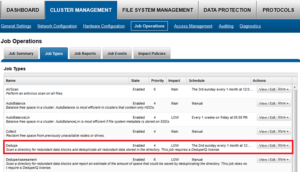
SmartDedupe can be run either on-demand (started manually) or via a predefined schedule. This is configured via the cluster management ‘Job Operations’ section of the WebUI.
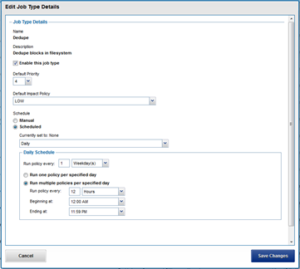
The recommendation is to schedule and run deduplication during off-hours, when the rate of data change on the cluster is low. If clients are continually writing to files, the amount of space saved by deduplication will be minimal because the deduplicated blocks are constantly being removed from the shadow store.
To modify the parameters of the dedupe job itself, run the isi job types modify command. For example, the following command configures the deduplication job to be run every Saturday at 12:00 AM:
# isi job types modify Dedupe --schedule "Every Saturday at 12:00 AM"
For most clusters, after the initial deduplication job has completed, the recommendation is to run an incremental deduplication job once every two weeks.
The amount of disk space currently saved by SmartDedupe can be determined by viewing the cluster capacity usage chart and deduplication reports summary table in the WebUI. The cluster capacity chart and deduplication reports can be found by navigating to File System Management > Deduplication > Summary.
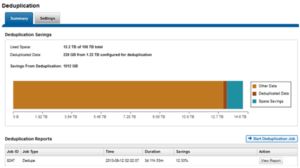
In addition to the bar chart and accompanying statistics (above), which graphically represents the data set and space efficiency in actual capacity terms, the dedupe job report overview field also displays the SmartDedupe savings as a percentage.
SmartDedupe space efficiency metrics are also provided via the ‘isi dedupe stats’ CLI command:
# isi dedupe stats Cluster Physical Size: 676.8841T Cluster Used Size: 236.3181T Logical Size Deduplicated: 29.2562T Logical Saving: 25.5125T Estimated Size Deduplicated: 42.5774T Estimated Physical Saving: 37.1290T
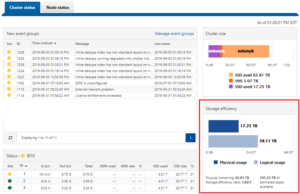
In OneFS 8.2.1 and later, SmartQuotas has been enhanced to report the capacity saving from deduplication, and data reduction in general, as a storage efficiency ratio. SmartQuotas reports efficiency as a ratio across the desired data set as specified in the quota path field. The efficiency ratio is for the full quota directory and its contents, including any overhead, and reflects the net efficiency of compression and deduplication. On a cluster with licensed and configured SmartQuotas, this efficiency ratio can be easily viewed from the WebUI by navigating to ‘File System > SmartQuotas > Quotas and Usage’.
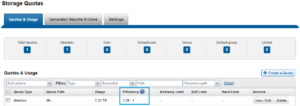
Similarly, the same data can be accessed from the OneFS command line via is ‘isi quota quotas list’ CLI command. For example:
# isi quota quotas list Type AppliesTo Path Snap Hard Soft Adv Used Efficiency ----------------------------------------------------------------------------- directory DEFAULT /ifs No - - - 2.3247T 1.29 : 1 ----------------------------------------------------------------------------- Total: 1
More detail, including both the physical (raw) and logical (effective) data capacities, is also available via the ‘isi quota quotas view <path> <type>’ CLI command. For example:
# isi quota quotas view /ifs directory Path: /ifs Type: directory Snapshots: No Thresholds Include Overhead: No Usage Files: 4245818 Physical(With Overhead): 1.80T Logical(W/O Overhead): 2.33T Efficiency(Logical/Physical): 1.29 : 1 …
To configure SmartQuotas for data efficiency reporting, create a directory quota at the top-level file system directory of interest, for example /ifs. Creating and configuring a directory quota is a simple procedure and can be performed from the WebUI, as follows:
Navigate to ‘File System > SmartQuotas > Quotas and Usage’ and select ‘Create a Quota’. In the create pane, field, set the Quota type to ‘Directory quota’, add the preferred top-level path to report on, select ‘File system logical size’ for Quota Accounting, and set the Quota Limits to ‘Track storage without specifying a storage limit’. Finally, select the ‘Create Quota’ button to confirm the configuration and activate the new directory quota.
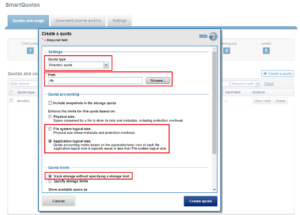
The efficiency ratio is a single, current-in time efficiency metric that is calculated per quota directory and includes the sum of SmartDedupe plus in-line data reduction. This is in contrast to a history of stats over time, as reported in the ‘isi statistics data-reduction’ CLI command output, described above. As such, the efficiency ratio for the entire quota directory will reflect what is actually there. via the platform API as of OneFS 8.2.2.
The OneFS WebUI cluster dashboard also now displays a storage efficiency tile, which shows physical and logical space utilization histograms and reports the capacity saving from in-line data reduction as a storage efficiency ratio. This dashboard view is displayed by default when opening the OneFS WebUI in a browser and can be easily accessed by navigating to ‘File System > Dashboard > Cluster Overview’.
The Job Engine parallel execution framework provides comprehensive run time and completion reporting for the deduplication job.
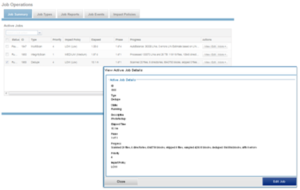
Once the dedupe job has started working on a directory tree, the resulting space savings it achieves can be monitored in real time. While SmartDedupe is underway, job status is available at a glance via the progress column in the active jobs table. This information includes the number of files, directories and blocks that have been scanned, skipped and sampled, and any errors that may have been encountered.
Additional progress information is provided in an Active Job Details status update, which includes an estimated completion percentage based on the number of logical inodes (LINs) that have been counted and processed.
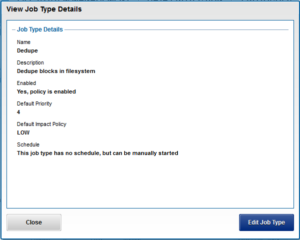
Once the SmartDedupe job has run to completion, or has been terminated, a full dedupe job report is available. This can be accessed from the WebUI by navigating to Cluster Management > Job Operations > Job Reports, and selecting ‘View Details’ action button on the desired Dedupe job line item.
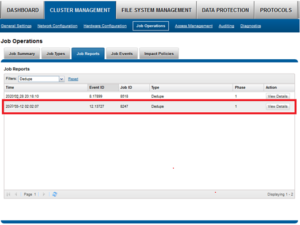
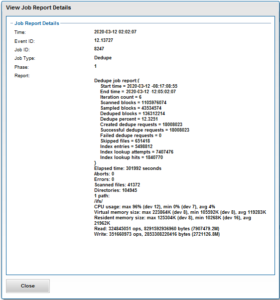
The job report contains the following relevant dedupe metrics.
| Report Field | Description of Metric |
| Start time | When the dedupe job started. |
| End time | When the dedupe job finished. |
| Scanned blocks | Total number of blocks scanned under configured path(s). |
| Sampled blocks | Number of blocks that OneFS created index entries for. |
| Created dedupe requests | Total number of dedupe requests created. A dedupe request gets created for each matching pair of data blocks. For example, three data blocks all match, two requests are created: One request to pair file1 and file2 together, the other request to pair file2 and file3 together. |
| Successful dedupe requests | Number of dedupe requests that completed successfully. |
| Failed dedupe requests | Number of dedupe requests that failed. If a dedupe request fails, it does not mean that the also job failed. A deduplication request can fail for any number of reasons. For example, the file might have been modified since it was sampled. |
| Skipped files | Number of files that were not scanned by the deduplication job. The primary reason is that the file has already been scanned and hasn’t been modified since. Another reason for a file to be skipped is if it’s less than 32KB in size. Such files are considered too small and don’t provide enough space saving benefit to offset the fragmentation they will cause. |
| Index entries | Number of entries that currently exist in the index. |
| Index lookup attempts | Cumulative total number of lookups that have been done by prior and current deduplication jobs. A lookup is when the deduplication job attempts to match a block that has been indexed with a block that hasn’t been indexed. |
| Index lookup hits | Total number of lookup hits that have been done by earlier deduplication jobs plus the number of lookup hits done by this deduplication job. A hit is a match of a sampled block with a block in index. |
Dedupe job reports are also available from the CLI via the ‘ isi job reports view <job_id> ’ command.
From an execution and reporting stance, the Job Engine considers the ‘dedupe’ job to comprise of a single process or phase. The Job Engine events list will report that Dedupe Phase1 has ended and succeeded. This indicates that an entire SmartDedupe job, including all four internal dedupe phases (sampling, duplicate detection, block sharing, & index update), has successfully completed. For example:
# isi job events list --job-type dedupe Time Message ------------------------------------------------------ 2020-09-01T13:39:32 Dedupe[1955] Running 2020-09-01T13:39:32 Dedupe[1955] Phase 1: begin dedupe 2020-09-01T14:20:32 Dedupe[1955] Phase 1: end dedupe 2020-09-01T14:20:32 Dedupe[1955] Phase 1: end dedupe 2020-09-01T14:20:32 Dedupe[1955] Succeeded
For deduplication reporting across multiple OneFS clusters, SmartConnect is also integrated with Isilon’s InsightIQ cluster reporting and analysis product. A report detailing the space savings delivered by deduplication is available via InsightIQ’s File Systems Analytics module.