HDP Upgrade and Transparent Data Encryption support on Isilon OneFS 8.2
The objective of this testing is to demonstrate the Hortonworks HDP upgrade from HDP 2.6.5 to HDP 3.1 , during which Transparent Data Encryption(TDE) KMS keys and configuration are ported to OneFS Service from HDFS service after upgrade accurately, this facilitates Hadoop user to leverage TDE support on OneFS 8.2 straight out of the box after upgrade without any changes to the TDE/KMS configurations.
HDFS Transparent Data Encryption
The primary motivation of Transparent Data Encryption on HDFS is to support both end-to-end on wire and at rest encryption for data without any modification to the user application. The TDE scheme adds an additional layer of data protection by storing the decryption keys for files on a separate key management server. This separation of keys and data guarantees that even if the HDFS service is completely compromised the files cannot be decrypted without also compromising the keystore.
Concerns and Risks
The primary concern with TDE is mangling/losing Encrypted Data Encryption Keys (EDEKs) which are unique to each file in an Encryption Zone and are necessary to decrypt the data within. If this occurs, the customer’s data will be lost (DL). A secondary concern is managing Encryption Zone Keys (EKs) which are unique to each Encryption Zone and are associated with the root directory of each Zone. Losing/Mangling the EK would result in data unavailability (DU) for the customer and would require admin intervention to remedy. Finally, we need to make sure that EDEKs are not reused in anyway as this would weaken the security of TDE. Otherwise, there is little to no risk to existing or otherwise unencrypted data since TDE only works within Encryption Zones which are not currently supported.
Hortonworks HDP 2.6.5 on Isilon OneFS 8.2
To install HDP 2.6.5 on OneFS 8.2 by following the install guide.
Note: In install, the document is for OneFS 8.1.2 in which hdfs user is mapped to root in the Isilon setting, which is not required on OneFS 8.2, but need to create a new role to the hdfs user to backup/restore RWX access on the file system.
OneFS 8.2 [New Steps to be new role to the hdfs multi-tenant access zone]
hop-isi-dd-3# isi auth roles create --name=BackUpAdmin --description="Bypass FS permissions" --zone=hdp
hop-isi-dd-3# isi auth roles modify BackupAdmin --add-priv=ISI_PRIV_IFS_RESTORE --zone=hdp
hop-isi-dd-3# isi auth roles modify BackupAdmin --add-priv=ISI_PRIV_IFS_BACKUP --zone=hdp
hop-isi-dd-3# isi auth roles view BackUpAdmin --zone=hdp
Name: BackUpAdmin
Description: Bypass FS permissions
Members: -
Privileges
ID: ISI_PRIV_IFS_BACKUP
Read Only: True
ID: ISI_PRIV_IFS_RESTORE
Read Only: True
hop-isi-dd-3# isi auth roles modify BackupAdmin --add-user=hdfs --zone=hdp
----- [ Optional:: Flush the auth mapping and cache to make hdfs take effect immediately]
hop-isi-dd-3# isi auth mapping flush --all
hop-isi-dd-3# isi auth cache flush --all
-----
1. After HDP 2.6.5 is installed on OneFS 8.2 following the install guide and above steps to add hdfs user backup/restore role. Install Ranger and Ranger KMS services, run service check on all the services to make sure the cluster is healthy and functional.

2. On the Isilon make sure hdfs multi-tenant access zone and hdfs user role are setup as required.
Isilon version

hop-isi-dd-3# isi version
Isilon OneFS v8.2.0.0 B_8_2_0_0_007(RELEASE): 0x802005000000007:Thu Apr 4 11:44:04 PDT 2019 root@sea-build11-04:/b/mnt/obj/b/mnt/src/amd64.amd64/sys/IQ.amd64.release FreeBSD clang version 3.9.1 (tags/RELEASE_391/final 289601) (based on LLVM 3.9.1)
hop-isi-dd-3#
HDFS user role setup
hop-isi-dd-3# isi auth roles view BackupAdmin --zone=hdp
Name: BackUpAdmin
Description: Bypass FS permissions
Members: hdfs
Privileges
ID: ISI_PRIV_IFS_BACKUP
Read Only: True
ID: ISI_PRIV_IFS_RESTORE
Read Only: True
hop-isi-dd-3#
Isilon HDFS setting
hop-isi-dd-3# isi hdfs settings view --zone=hdp
Service: Yes
Default Block Size: 128M
Default Checksum Type: none
Authentication Mode: all
Root Directory: /ifs/data/zone1/hdp
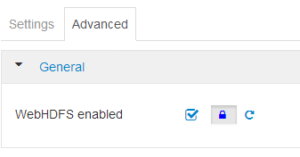
WebHDFS Enabled: Yes
Ambari Server:
Ambari Namenode: kb-hdp-z1.hop-isi-dd.solarch.lab.emc.com
ODP Version:
Data Transfer Cipher: none
Ambari Metrics Collector: pipe-hdp1.solarch.emc.com
hop-isi-dd-3#
hdfs to root mapping removed from the MULTI-TENANT access zone setting
hop-isi-dd-3# isi zone view hdp
Name: hdp
Path: /ifs/data/zone1/hdp
Groupnet: groupnet0
Map Untrusted:
Auth Providers: lsa-local-provider:hdp
NetBIOS Name:
User Mapping Rules:
Home Directory Umask: 0077
Skeleton Directory: /usr/share/skel
Cache Entry Expiry: 4H
Negative Cache Entry Expiry: 1m
Zone ID: 2
hop-isi-dd-3#
3. TDE Functional Testing
Primary Testing Foci
Reads and Writes: Clients with the correct permissions must always be able to reliably decrypt.
Kerberos Integration: Realistically, customers will not deploy TDE without Kerberos. [ In this testing Kerberos is not integrated]
TDE Configurations
HDFS TDE Setup
a. Create an encryption zone (EZ) key
Hadoop key create <keyname>
User “keyadmin” has privileges to create, delete, rollover, set key material, get, get keys, get metadata, generate EEK and Decrypt EEK. These privileges are controlled in Ranger web UI, login as keyadmin / <password> and setup these privileges.
[root@pipe-hdp1 ~]# su keyadmin
bash-4.2$ whoami
keyadmin
bash-4.2$ hadoop key create key_a
key_a has been successfully created with options Options{cipher='AES/CTR/NoPadding', bitLength=128, description='null', attributes=null}.
KMSClientProvider[http://pipe-hdp1.solarch.emc.com:9292/kms/v1/] has been updated.
bash-4.2$ hadoop key create key_a
key_a has been successfully created with options Options{cipher='AES/CTR/NoPadding', bitLength=128, description='null', attributes=null}.
KMSClientProvider[http://pipe-hdp1.solarch.emc.com:9292/kms/v1/] has been updated.
bash-4.2$
bash-4.2$ hadoop key list
Listing keys for KeyProvider: KMSClientProvider[http://pipe-hdp1.solarch.emc.com:9292/kms/v1/]
key_data
key_b
key_a
bash-4.2$
Note:: New Keys can also be created from Ranger KMS UI.
OneFS TDE Setup
a. Configure KMS URL in the Isilon OneFS CLI
isi hdfs crypto settings modify –kms-url=<url-string> –zone=<hdfs-zone-name> -v
isi hdfs crypto settings view –zone=<hdfs-zone-name>
hop-isi-dd-3# isi hdfs crypto settings view --zone=hdp
Kms Url: http://pipe-hdp1.solarch.emc.com:9292
hop-isi-dd-3#
b. Create a new directory in Isilon OneFS CLI under the Hadoop zone that needs to be encryption zone
mkdir /ifs/hdfs/<new-directory-name>
hop-isi-dd-3# mkdir /ifs/data/zone1/hdp/data_a
hop-isi-dd-3# mkdir /ifs/data/zone1/hdp/data_b
c. After new directory created, create encryption zone by assigning encryption key and directory path
isi hdfs crypto encryption-zones create –path=<new-directory-path> –key-name=<key-created-via-hdfs> –zone=<hdfs-zone-name> -v
hop-isi-dd-3# isi hdfs crypto encryption-zones create --path=/ifs/data/zone1/hdp/data_a --key-name=key_a --zone=hdp -v
Create encryption zone named /ifs/data/zone1/hdp/data_a, with key_a
hop-isi-dd-3# isi hdfs crypto encryption-zones create --path=/ifs/data/zone1/hdp/data_b --key-name=key_b --zone=hdp -v
Create encryption zone named /ifs/data/zone1/hdp/data_b, with key_b
NOTE:
-
- Encryption keys need to be created from hdfs client
- Need KMS store to manage keys example Ranger KMS
- Encryption zones can be created only on Isilon with CLI
- Creating an encryption zone from hdfs client fails with Unknown RPC RemoteException.
TDE Setup Validation
On HDFS Cluster
a. Verify the same from hdfs client [Path is listed from the hdfs root dir]
hdfs crypto -listZones
bash-4.2$ hdfs crypto -listZones
/data_a key_a
/data_b key_b
On Isilon Cluster
a. List the encryption zones on Isilon [Path is listed from the Isilon root path]
hdfs crypto -listZones
bash-4.2$ hdfs crypto -listZones
/data_a key_a
/data_b key_b
TDE Functional Testing
Authorize users to the EZ and KMS Keys
Ranger KMS UI
a. Login into Ranger KMS UI using keyadmin / <password>

b. Create 2 new policies to assign users (yarn, hive) to key_a and (mapred, hive) to key_b with the Get, Get Keys, Get Metadata, Generate EEK and Decrypt EEK permissions.


TDE HDFS Client Testing
a. Create sample files, copy it to respective EZs and access them from respective users.
/data_a EZ associated with key_a and only yarn, hive users have permissions
bash-4.2$ whoami
yarn
bash-4.2$ echo "YARN user test file, can you read this?" > yarn_test_file
bash-4.2$ rm -rf yarn_test_fil
bash-4.2$ hadoop fs -put yarn_test_file /data_a/
bash-4.2$ hadoop fs -cat /data_a/yarn_test_file
YARN user test file, can you read this?
bash-4.2$ whoami
yarn
bash-4.2$ exit
exit
[root@pipe-hdp1 ~]# su mapred
bash-4.2$ hadoop fs -cat /data_a/yarn_test_file
cat: User:mapred not allowed to do 'DECRYPT_EEK' on 'key_a'
bash-4.2$
/data_b EZ associated with key_b and only mapred, hive users have permissions
bash-4.2$ whoami
mapred
bash-4.2$ echo "MAPRED user test file, can you read this?" > mapred_test_file
bash-4.2$ hadoop fs -put mapred_test_file /data_b/
bash-4.2$ hadoop fs -cat /data_b/mapred_test_file
MAPRED user test file, can you read this?
bash-4.2$ exit
exit
[root@pipe-hdp1 ~]# su yarn
bash-4.2$ hadoop fs -cat /data_b/mapred_test_file
cat: User:yarn not allowed to do 'DECRYPT_EEK' on 'key_b'
bash-4.2$
User hive has permission to decrypt both keys i.e. ca access both EZs
USER user with decrypt privilege [HIVE]
[root@pipe-hdp1 ~]# su hive
bash-4.2$ pwd
/root
bash-4.2$ hadoop fs -cat /data_b/mapred_test_file
MAPRED user test file, can you read this?
bash-4.2$ hadoop fs -cat /data_a/yarn_test_file
YARN user test file, can you read this?
bash-4.2$
Sample distcp to copy data between EZs.
bash-4.2$ hadoop distcp -skipcrccheck -update /data_a/yarn_test_file /data_b/
19/05/20 21:20:02 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=true, deleteMissing=false, ignoreFailures=false, overwrite=false, append=false, useDiff=false, fromSnapshot=null, toSnapshot=null, skipCRC=true, blocking=true, numListstatusThreads=0, maxMaps=20, mapBandwidth=100, sslConfigurationFile='null', copyStrategy='uniformsize', preserveStatus=[], preserveRawXattrs=false, atomicWorkPath=null, logPath=null, sourceFileListing=null, sourcePaths=[/data_a/yarn_test_file], targetPath=/data_b, targetPathExists=true, filtersFile='null', verboseLog=false}
19/05/20 21:20:03 INFO client.RMProxy: Connecting to ResourceManager at pipe-hdp1.solarch.emc.com/10.246.156.91:8050
19/05/20 21:20:03 INFO client.AHSProxy: Connecting to Application History server at pipe-hdp1.solarch.emc.com/10.246.156.91:10200
"""
"""
19/05/20 21:20:04 INFO mapreduce.Job: Running job: job_1558336274787_0003
19/05/20 21:20:12 INFO mapreduce.Job: Job job_1558336274787_0003 running in uber mode : false
19/05/20 21:20:12 INFO mapreduce.Job: map 0% reduce 0%
19/05/20 21:20:18 INFO mapreduce.Job: map 100% reduce 0%
19/05/20 21:20:18 INFO mapreduce.Job: Job job_1558336274787_0003 completed successfully
19/05/20 21:20:18 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=152563
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=426
HDFS: Number of bytes written=40
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=4045
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=4045
Total vcore-milliseconds taken by all map tasks=4045
Total megabyte-milliseconds taken by all map tasks=4142080
Map-Reduce Framework
Map input records=1
Map output records=0
Input split bytes=114
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=91
CPU time spent (ms)=2460
Physical memory (bytes) snapshot=290668544
Virtual memory (bytes) snapshot=5497425920
Total committed heap usage (bytes)=196083712
File Input Format Counters
Bytes Read=272
File Output Format Counters
Bytes Written=0
org.apache.hadoop.tools.mapred.CopyMapper$Counter
BYTESCOPIED=40
BYTESEXPECTED=40
COPY=1
bash-4.2$
bash-4.2$ hadoop fs -ls /data_b/
Found 2 items
-rwxrwxr-x 3 mapred hadoop 42 2019-05-20 04:24 /data_b/mapred_test_file
-rw-r--r-- 3 hive hadoop 40 2019-05-20 21:20 /data_b/yarn_test_file
bash-4.2$ hadoop fs -cat /data_b/yarn_test_file
YARN user test file, can you read this?
bash-4.2$
Hadoop user without permission
bash-4.2$ hadoop fs -put test_file /data_a/
put: User:hdfs not allowed to do 'DECRYPT_EEK' on 'key_A'
19/05/20 02:35:10 ERROR hdfs.DFSClient: Failed to close inode 4306114529
org.apache.hadoop.ipc.RemoteException(java.io.FileNotFoundException): File does not exist: /data_a/test_file._COPYING_ (inode 4306114529)
TDE OneFS CLI Testing
EZ on Isilon EZ, no user has access to read the file
hop-isi-dd-3# whoami
root
hop-isi-dd-3# cat data_a/yarn_test_file
▒?Tm@DIc▒▒B▒▒>\Qs▒:[VzC▒▒Rw^<▒▒▒▒▒8H#
hop-isi-dd-3% whoami
yarn
hop-isi-dd-3% cat data_a/yarn_test_file
▒?Tm@DIc▒▒B▒▒>\Qs▒:[VzC▒▒Rw^<▒▒▒▒▒8H%
Upgrade the HDP to the latest version, following the upgrade process blog.
After upgrade make sure all the services are up running and pass the service check.
HDFS service will be replaced with OneFS service, under OneFS service configuration make sure KMS related properties are ported successfully.

Login into KMS UI and check the policies are intact after upgrade [ Note after upgrading new “Policy Labels” column added]

TDE validate existing configuration and keys after HDP 3.1 upgrade
TDE HDFS client testing existing configuration and keys
a. List the KMS provider and key to check they are intact after the upgrade
[root@pipe-hdp1 ~]# su hdfs
bash-4.2$ hadoop key list
Listing keys for KeyProvider: org.apache.hadoop.crypto.key.kms.LoadBalancingKMSClientProvider@2f54a33d
key_b
key_a
key_data
bash-4.2$ hdfs crypto -listZones
/data key_data
/data_a key_a
/data_b key_b
b. Create sample files, copy it to respective EZs and access them from respective users
[root@pipe-hdp1 ~]# su yarn
bash-4.2$ cd
bash-4.2$ pwd
/home/yarn
bash-4.2$ echo "YARN user testfile after upgrade to hdp3.1, can you read this?" > yarn_test_file_2
bash-4.2$ hadoop fs -put yarn_test_file_2 /data_a/
bash-4.2$ hadoop fs -cat /data_a/yarn_test_file_2
YARN user testfile after upgrade to hdp3.1, can you read this?
bash-4.2$
[root@pipe-hdp1 ~]# su mapred
bash-4.2$ cd
bash-4.2$ pwd
/home/mapred
bash-4.2$ echo "MAPRED user testfile after upgrade to hdp3.1, can you read this?" > mapred_test_file_2
bash-4.2$ hadoop fs -put mapred_test_file_2 /data_b/
bash-4.2$ hadoop fs -cat /data_b/mapred_test_file_2
MAPRED user testfile after upgrade to hdp3.1, can you read this?
bash-4.2$
[root@pipe-hdp1 ~]# su yarn
bash-4.2$ hadoop fs -cat /data_b/mapred_test_file_2
cat: User:yarn not allowed to do 'DECRYPT_EEK' on 'key_b'
bash-4.2$
[root@pipe-hdp1 ~]# su hive
bash-4.2$ hadoop fs -cat /data_a/yarn_test_file_2
YARN user testfile after upgrade to hdp3.1, can you read this?
bash-4.2$ hadoop fs -cat /data_b/mapred_test_file_2
MAPRED user testfile after upgrade to hdp3.1, can you read this?
bash-4.2$
bash-4.2$ hadoop distcp -skipcrccheck -update /data_a/yarn_test_file_2 /data_b/
19/05/21 05:23:38 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=true, deleteMissing=false, ignoreFailures=false, overwrite=false, append=false, useDiff=false, useRdiff=false, fromSnapshot=null, toSnapshot=null, skipCRC=true, blocking=true, numListstatusThreads=0, maxMaps=20, mapBandwidth=0.0, copyStrategy='uniformsize', preserveStatus=[BLOCKSIZE], atomicWorkPath=null, logPath=null, sourceFileListing=null, sourcePaths=[/data_a/yarn_test_file_2], targetPath=/data_b, filtersFile='null', blocksPerChunk=0, copyBufferSize=8192, verboseLog=false}, sourcePaths=[/data_a/yarn_test_file_2], targetPathExists=true, preserveRawXattrsfalse
19/05/21 05:23:38 INFO client.RMProxy: Connecting to ResourceManager at pipe-hdp1.solarch.emc.com/10.246.156.91:8050
19/05/21 05:23:38 INFO client.AHSProxy: Connecting to Application History server at pipe-hdp1.solarch.emc.com/10.246.156.91:10200
"
19/05/21 05:23:54 INFO mapreduce.Job: map 0% reduce 0%
19/05/21 05:24:00 INFO mapreduce.Job: map 100% reduce 0%
19/05/21 05:24:00 INFO mapreduce.Job: Job job_1558427755021_0001 completed successfully
19/05/21 05:24:00 INFO mapreduce.Job: Counters: 36
"
Bytes Copied=63
Bytes Expected=63
Files Copied=1
bash-4.2$ hadoop fs -ls /data_b/
Found 4 items
-rwxrwxr-x 3 mapred hadoop 42 2019-05-20 04:24 /data_b/mapred_test_file
-rw-r--r-- 3 mapred hadoop 65 2019-05-21 05:21 /data_b/mapred_test_file_2
-rw-r--r-- 3 hive hadoop 40 2019-05-20 21:20 /data_b/yarn_test_file
-rw-r--r-- 3 hive hadoop 63 2019-05-21 05:23 /data_b/yarn_test_file_2
bash-4.2$ hadoop fs -cat /data_b/yarn_test_file_2
YARN user testfile after upgrade to hdp3.1, can you read this?
bash-4.2$ hadoop fs -cat /data_b/yarn_test_file_2
YARN user testfile after upgrade to hdp3.1, can you read this?
bash-4.2$
TDE OneFS client testing existing configuration and keys
a. List the KMS provider and key to check they are intact after upgrade
hop-isi-dd-3# isi hdfs crypto settings view --zone=hdp
Kms Url: http://pipe-hdp1.solarch.emc.com:9292
hop-isi-dd-3# isi hdfs crypto encryption-zones list
Path Key Name
------------------------------------
/ifs/data/zone1/hdp/data key_data
/ifs/data/zone1/hdp/data_a key_a
/ifs/data/zone1/hdp/data_b key_b
------------------------------------
Total: 3
hop-isi-dd-3#
b. Permission to access previous created EZs
hop-isi-dd-3# cat data_b/yarn_test_file_2
3▒
▒{&▒{<N▒7▒ ,▒▒l▒n.▒▒▒bz▒6▒ ▒G▒_▒l▒Ieñ+
▒t▒▒N^▒ ▒# hop-isi-dd-3# whoami
root
hop-isi-dd-3#
TDE validate new configuration and keys after HDP 3.1 upgrade
TDE HDFS Client new keys setup
a. Create new keys and list
bash-4.2$ hadoop key create up_key_a
up_key_a has been successfully created with options Options{cipher='AES/CTR/NoPadding', bitLength=128, description='null', attributes=null}.
org.apache.hadoop.crypto.key.kms.LoadBalancingKMSClientProvider@11bd0f3b has been updated.
bash-4.2$ hadoop key create up_key_b
up_key_b has been successfully created with options Options{cipher='AES/CTR/NoPadding', bitLength=128, description='null', attributes=null}.
org.apache.hadoop.crypto.key.kms.LoadBalancingKMSClientProvider@11bd0f3b has been updated.
bash-4.2$ hadoop key list
Listing keys for KeyProvider: org.apache.hadoop.crypto.key.kms.LoadBalancingKMSClientProvider@2f54a33d
key_b
key_a
key_data
up_key_b
up_key_a
bash-4.2$
b. After EZs created from OneFS CLI check the zones reflect from HDFS client
bash-4.2$ hdfs crypto -listZones
/data key_data
/data_a key_a
/data_b key_b
/up_data_a up_key_a
/up_data_b up_key_b
TDE OneFS Client new encryption zone setup
a. Create new EZ from OneFS CLI
HOP-ISI-DD-3# ISI HDFS CRYPTO ENCRYPTION-ZONES CREATE --PATH=/IFS/DATA/ZONE1/HDP/UP_DATA_A --KEY-NAME=UP_KEY_A --ZONE=HDP -V
Create encryption zone named /ifs/data/zone1/hdp/up_data_a, with up_key_a
hop-isi-dd-3# isi hdfs crypto encryption-zones create --path=/ifs/data/zone1/hdp/up_data_b --key-name=up_key_b --zone=hdp -v
Create encryption zone named /ifs/data/zone1/hdp/up_data_b, with up_key_b
hop-isi-dd-3# isi hdfs crypto encryption-zones list
Path Key Name
---------------------------------------
/ifs/data/zone1/hdp/data key_data
/ifs/data/zone1/hdp/data_a key_a
/ifs/data/zone1/hdp/data_b key_b
/ifs/data/zone1/hdp/up_data_a up_key_a
/ifs/data/zone1/hdp/up_data_b up_key_b
---------------------------------------
Total: 5
hop-isi-dd-3#
Create 2 new policies to assign users (yarn, hive) to up_key_a and (mapred, hive) to up_key_b with the Get, Get Keys, Get Metadata, Generate EEK and Decrypt EEK permissions.

TDE HDFS Client testing on upgraded HDP 3.1
a. Create sample files, copy it to respective EZs and access them from respective users
/up_data_a EZ associated with up_key_a and only yarn, hive users have permissions
[root@pipe-hdp1 ~]# su yarn
bash-4.2$ echo "After HDP Upgrade to HDP 3.1, YARN user, Creating this file" > up_yarn_test_file
bash-4.2$ hadoop fs -put up_yarn_test_file /up_data_a/
bash-4.2$ hadoop fs -cat /up_data_a/up_yarn_test_file
After HDP Upgrade to HDP 3.1, YARN user, Creating this file
bash-4.2$ hadoop fs -cat /up_data_b/up_mapred_test_file
cat: User:yarn not allowed to do 'DECRYPT_EEK' on 'up_key_b'
bash-4.2$
/up_data_b EZ associated with up_key_b and only mapred, hive users have permissions
[root@pipe-hdp1 ~]# su mapred
bash-4.2$ cd
bash-4.2$ echo "After HDP Upgrade to HDP 3.1, MAPRED user, Creating this file" > up_mapred_test_file
bash-4.2$ hadoop fs -put up_mapred_test_file /up_data_b/
bash-4.2$ hadoop fs -cat /up_data_b/up_mapred_test_file
After HDP Upgrade to HDP 3.1, MAPRED user, Creating this file
bash-4.2$
User hive has permission to decrypt both keys i.e. ca access both EZs
USER user with decrypt privilege [HIVE]
[root@pipe-hdp1 ~]# su hive
bash-4.2$ hadoop fs -cat /up_data_b/up_mapred_test_file
After HDP Upgrade to HDP 3.1, MAPRED user, Creating this file
bash-4.2$ hadoop fs -cat /up_data_a/up_yarn_test_file
After HDP Upgrade to HDP 3.1, YARN user, Creating this file
bash-4.2$
Sample distcp to copy data between EZs.
bash-4.2$ hadoop distcp -skipcrccheck -update /up_data_a/up_yarn_test_file /up_data_b/
19/05/22 04:48:21 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=true, deleteMissing=false, ignoreFailures=false, overwrite=false, append=false, useDiff=false, useRdiff=false, fromSnapshot=null, toSnapshot=null, skipCRC=true, blocking=true, numListstatusThreads=0, maxMaps=20, mapBandwidth=0.0, copyStrategy='uniformsize', preserveStatus=[BLOCKSIZE], atomicWorkPath=null, logPath=null, sourceFileListing=null, sourcePaths=[/up_data_a/up_yarn_test_file], targetPath=/up_data_b, filtersFile='null', blocksPerChunk=0, copyBufferSize=8192, verboseLog=false}, sourcePaths=[/up_data_a/up_yarn_test_file], targetPathExists=true, preserveRawXattrsfalse
"
19/05/22 04:48:23 INFO mapreduce.Job: The url to track the job: http://pipe-hdp1.solarch.emc.com:8088/proxy/application_1558505736502_0001/
19/05/22 04:48:23 INFO tools.DistCp: DistCp job-id: job_1558505736502_0001
19/05/22 04:48:23 INFO mapreduce.Job: Running job: job_1558505736502_0001
"
Bytes Expected=60
Files Copied=1
bash-4.2$ hadoop fs -ls /up_data_b/
Found 2 items
-rw-r--r-- 3 mapred hadoop 62 2019-05-22 04:43 /up_data_b/up_mapred_test_file
-rw-r--r-- 3 hive hadoop 60 2019-05-22 04:48 /up_data_b/up_yarn_test_file
bash-4.2$ hadoop fs -cat /up_data_b/up_yarn_test_file
After HDP Upgrade to HDP 3.1, YARN user, Creating this file
bash-4.2$
Hadoop user without permission
bash-4.2$ hadoop fs -put test_file /data_a/
put: User:hdfs not allowed to do 'DECRYPT_EEK' on 'key_A'
19/05/20 02:35:10 ERROR hdfs.DFSClient: Failed to close inode 4306114529
org.apache.hadoop.ipc.RemoteException(java.io.FileNotFoundException): File does not exist: /data_a/test_file._COPYING_ (inode 4306114529)
TDE OneFS CLI Testing
Permissions on Isilon EZ, no user has access to read the file
hop-isi-dd-3# cat up_data_a/up_yarn_test_file
%*݊▒▒ixu▒▒▒=}▒▒▒h~▒7▒=_▒▒▒0▒[.-$▒:/▒Ԋ▒▒▒▒\8vf▒{F▒Sl▒▒#
Conclusion
Above testing and results prove that HDP upgrade does not break and TDE configuration and same are ported to new OneFS service after a successful upgrade.
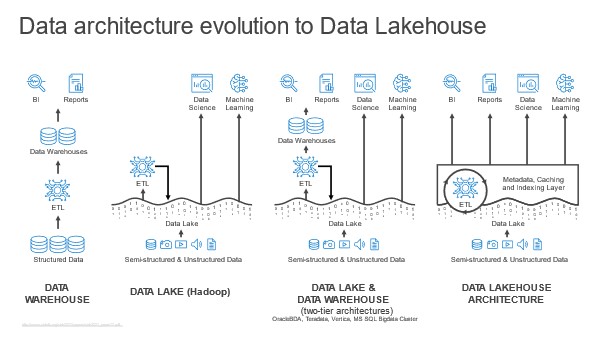
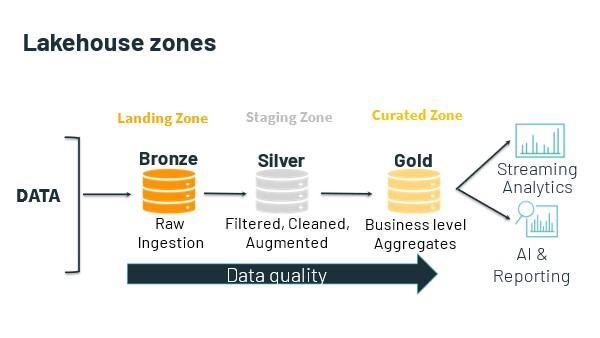 Usually, the data lake is home to all an organization’s useful data. This data is already there. So, the data lakehouse begins with query against this data where it lives.
Usually, the data lake is home to all an organization’s useful data. This data is already there. So, the data lakehouse begins with query against this data where it lives.