In this article we’ll dig into the details of configuring and managing SmartThrottling.
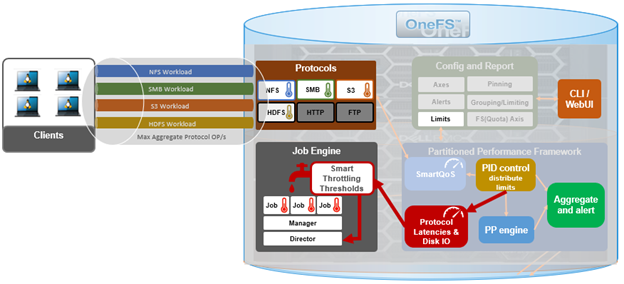
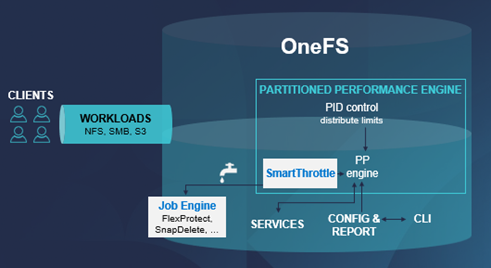
SmartThrottling intelligently prioritizes primary client traffic, while automatically using any spare resources for cluster housekeeping. It does this by dynamically throttling jobs forward and backward, yielding enhanced impact policy effectiveness, and improved predictability for cluster maintenance and data management tasks.
The read and write latencies of critical client protocol load are monitored, and SmartThrottling uses these metrics to keep the latencies within specified thresholds. As they approach the limit, the Job Engine stops increasing its work, and if latency exceeds the thresholds, it actively reduces the amount of work the jobs perform.
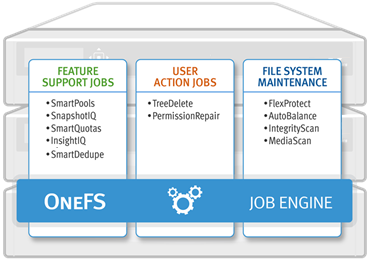
SmartThrottling also monitors the cluster’s drives and similarly maintains disk IO health within set limits. The actual job impact configuration remains unchanged in OneFS 9.8, and each job still has the same default level and priority as in prior releases.
Currently disabled by default on installation or upgrade to OneFS 9.8, SmartThrottling is currently recommended specifically for clusters that have experienced challenges related to the impact the Job Engine has on their workloads. For these environments, SmartThrottling should provide some noticeable improvements. However, like all 1.0 features, SmartThrottling does have some important caveats and limitations to be aware of in OneFS 9.8.
First, the SmartThrottling thresholds are currently global, so they treat all nodes equally. This means that lower powered nodes like the A-series might get impacted more than desired. This is especially germane for heterogenous clusters, with a range of differing node strengths within the cluster.
Second, it is also worth noting that, as PP performs its protocol monitoring at the IRP layer in the Likewise stack, so only NFS, SMB, S3, and HDFS are included.
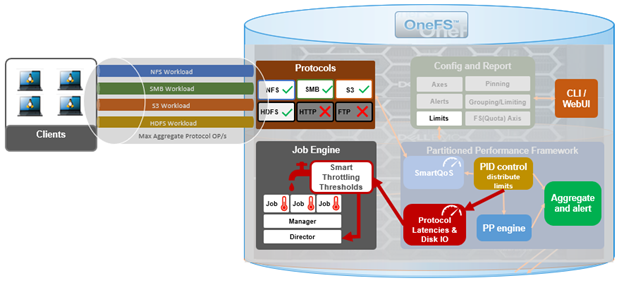
As such, FTP and HTTP, which don’t use Likewise, are not currently monitored by PP. So their latencies will not be considered, and the Job Engine will not notice if HTTP and FTP workloads are being impacted.
So these caveats are the main reason that SmartThrottling hasn’t been automatically enabled yet. But engineering’s plan is to make it even smarter and enable it by default in a future release.
Configuration-wise, SmartThrottling is pretty straightforward and via the CLI only, with no WebUI integration yet. The current state of throttling can be displayed with the ‘isi job settings view’ command:
# isi job settings view Parallel Restriper Mode: All Smartthrottling: False
It can also be easily enabled or disabled via a new ‘smartthrottling’ switch for ‘isi job settings modify’.
For example, to enable SmartThrottling:
# isi job settings modify --smartthrottling enable
Or to disable:
# isi job settings modify --smartthrottling disable
Running this command will cause the Job Engine to restart, temporarily pausing and resuming any running jobs, after which they will continue where they left off and run to completion as normal.
For advanced configuration, there are three main threshold options. These are:
- Target read latency for protocol operations.
- Target write latency thresholds for protocol operations.
- Disk IO time in queue threshold.
These thresholds can be viewed as follows:
# isi performance settings view Top N Collections: 1024 Time In Queue Threshold (ms): 10.00 Target read latency in microseconds: 12000.0 Target write latency in microseconds: 12000.0 Protocol Ops Limit Enabled: Yes Medium impact job latency threshold modifier in microseconds: 12000.0 High impact job latency threshold modifier in microseconds: 24000.0
The target read and write latency thresholds default to 12 milliseconds (ms) for low impact jobs, and are the thresholds at which SmartThrottling begins to throttle the work. There are also modifiers for both medium and high impact jobs, which are set to an additional 12 ms and 24 ms respectively by default. So for medium impact jobs, throttling will start to kick in around 20 ms, and then really throttle the job engine at 24 ms. It needs to be this high in order to maintain the mean time to data loss metrics for the FlexProtect job. Similarly, for the high impact jobs throttling starts at 30 ms and ramps up at 36 ms. But currently there are no default high impact jobs, so this level would have to be configured manually for a job.
Since SmartThrottling is currently configured for average, middle-of-the-road clusters, these advanced settings allow job engine throttling to be tuned for specific customer environments, if necessary. This can be done via the ‘isi performance settings modify’ CLI command and the following options:
# isi performance settings modify --target-protocol-read-latency-usec <int> --target-protocol-write-latency-usec --medium-impact-modifier-usec --high-impact-modifier-usec --target-disk-time-in-queue-ms
That’s pretty much it for configuration in OneFS 9.8, although engineering will likely be adding additional tunables in a future release, when job throttling is enabled by default.
In OneFS 9.8, the default SmartThrottling thresholds target average clusters. This means that the default latency thresholds are likely much higher than desired for all-flash nodes.
So F-series clusters usually respond well to setting thresholds considerably lower than 12 milliseconds. But since there’s little customer data at this point, there really aren’t any hard and fast guidelines yet, and it’ll likely require some experimentation.
The are also some idiosyncrasies and considerations to bear in mind with job throttling, particularly if a cluster become idle for a period. That is if no protocol load occurs – then the job engine will ramp up to use more resources. This means that when client protocol load does return, the job engine will be consuming more than its fair share of cluster resources. Typically, this will auto-correct itself rapidly in most circumstances. However, if A-series nodes are being used for protocol load, which is not a recommended use case for SmartThrottling, then this auto-correction may take longer than desired. This is another scenario that engineering will address before SmartThrottling becomes prime-time and enabled by default. But for now, possible interim solutions are either:
- Moving protocol load away from archive class nodes
Or:
- Disabling the use of SmartThrottling and letting ‘legacy’ job engine impact management continue to function, as it does in earlier OneFS versions.
Also, since a cluster has a finite quantity of resources, if it’s being pushed hard and protocol operation latency is constantly over the threshold, jobs will be throttled to their lowest limit. This is similar to the legacy job engine throttling behavior, except that it’s now using protocol operation latency instead of other metrics. The job will continue to execute but, depending on the circumstances, this may take longer than desired. Again, this is more frequently seen on the lower-powered archive class nodes. Possible solutions here include:
- Decreasing the cluster load so protocol latency recovers.
- Increasing the impact setting of the job so that it can run faster.
- Or tuning the thresholds to more appropriate values for the workload.
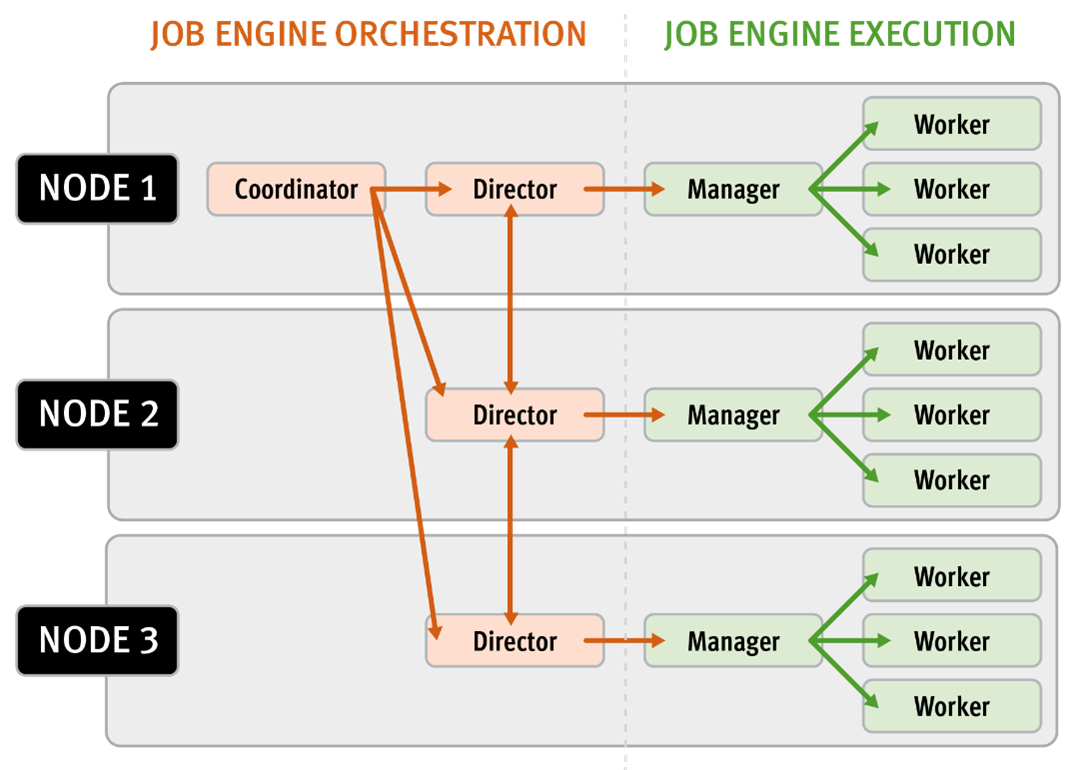
When it comes to monitoring and investigating SmartThrottling’s antics, there are a handful of logs that are a good place to start. First, there’s a new job engine throttling job, which contains information on the current work counts, throttling decisions, and their causes. The next place to look is the partitioned performance daemon log. This daemon is responsible for monitoring the cluster and setting throttling limits, and monitoring and throttling information and errors may be reported here. It logs the current metrics it sees across the cluster, and the job throttles it calculates from them. And finally, the standard job engine logs, where information and errors are typically reported.
| Log File | Location | Description |
| Throttling log | /var/log/isi_job_d_throttling.log | Contains information on the current worker counts, throttling decisions, and their causes. |
| PP log | /var/log/isi_pp_d.log | The partitioned performance daemon is responsible for monitoring the cluster and setting throttling limits. Monitoring and throttling information and errors may be reported here. It logs the current metrics is sees across the cluster and the job throttles it calculates from them. |
| Job engine log | /var/log/isi_job_d.log | Job and job engine information and errors may be reported here. |