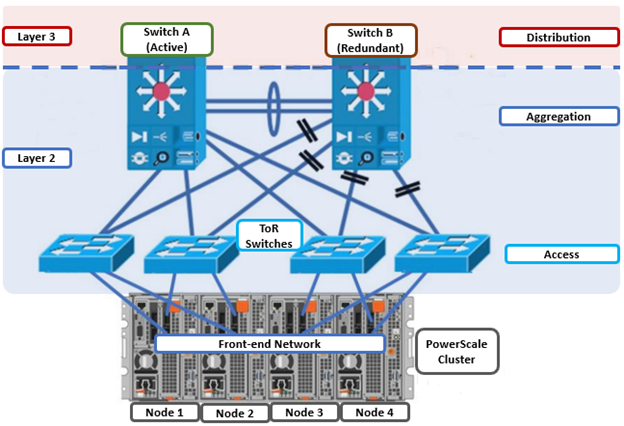
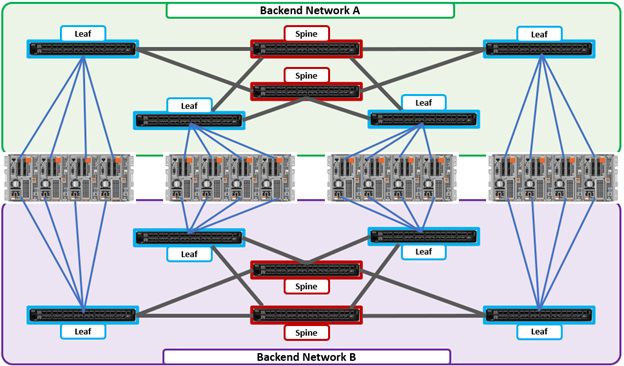
In the previous articles in this series, we’ve looked at the fundamentals of a cluster’s network infrastructure:
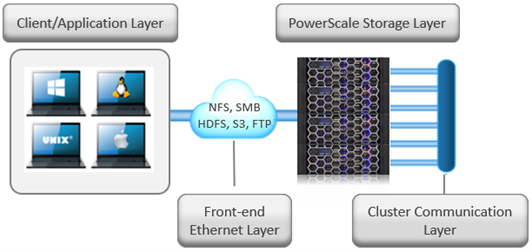
The complete cluster architecture – software, hardware, and network – all cooperate to provide a distributed single file system that can scale dynamically as workloads and capacity and/or throughput needs change in a scale-out environment.
OneFS SmartConnect provides the load balancing services that work at the front-end Ethernet layer to evenly distribute client connections across the cluster. SmartConnect supports dynamic NFS failover and failback for Linux and UNIX clients and SMB3 continuous availability for Windows clients. This ensures that when a node failure occurs, or preventative maintenance is performed, all in-flight reads and writes are handed off to another node in the cluster to finish its operation without any user or application interruption.
During failover, clients are evenly redistributed across all remaining nodes in the cluster, ensuring minimal performance impact. If a node is brought down for any reason, including a failure, the virtual IP addresses on that node is seamlessly migrated to another node in the cluster.
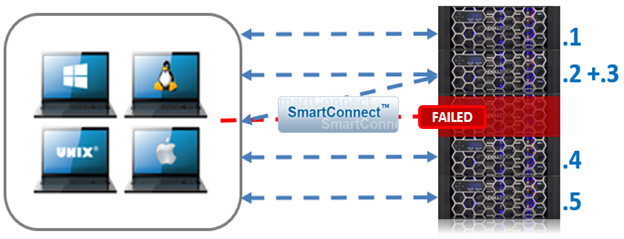
When the offline node is brought back online, SmartConnect automatically rebalances the NFS and SMB3 clients across the entire cluster to ensure maximum storage and performance utilization. For periodic system maintenance and software updates, this functionality allows for per-node rolling upgrades affording full-availability throughout the duration of the maintenance window.
The OneFS SmartConnect module itself can be run in two modes – with or without a license:
| SmartConnect Attribute | SmartConnect Basic (unlicensed) | SmartConnect Advanced (Licensed) |
| Connection Balancing | Round-robin only. | Round-robin, CPU utilization, connection counting, and throughput balancing. |
| Address Allocation | Static IP allocation only. | Static and dynamic IP address allocation, up to a maximum of six SmartConnect Service IP addresses per subnet. |
| Address Failover | No IP address failover policy. | Supports defining a failover policy for the IP address pool. |
| Address Rebalance | No IP address rebalance policy. | Supports defining a rebalance policy for the IP address pool. |
| Per-pool Addresses | Up to two IP address pools per external network subnet | Supports multiple IP address pools per external subnet to enable multiple DNS zones within a single subnet. |
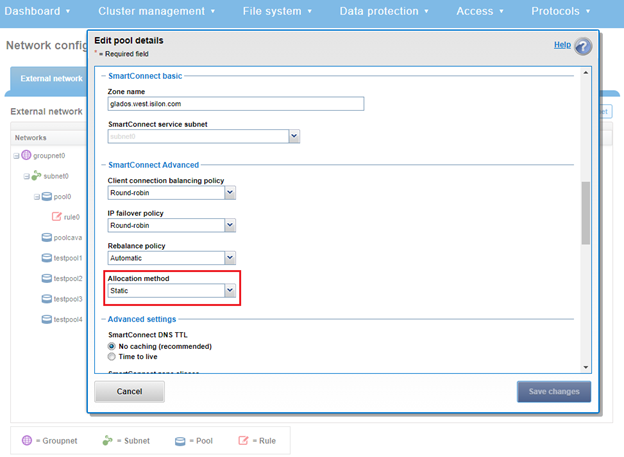
The SmartPools static vs dynamic address allocation method indicates whether the IP addresses in the pool can move back and forth between nodes when a node goes down. As such, a static IP pool displays the following characteristics:
- Each interface in the pool gets exactly one IP (assuming there are at least as many IPs as interfaces in the pool).
- If there are more IPs in the pool than interfaces, the additional IPs will not be allocated to any interface.
- IPs do not move from one interface to another.
- If an interface goes down, then the IP also goes down.
Conversely, in a dynamic IP pool:
- Each of the IPs in the pool is allocated to an interface in the pool.
- When an interface goes down in the pool, the IPs on that interface automatically move to another interface in the pool (preferring interfaces in the pool that are on the same node as the downed interface).
- When a node is transitions to an ‘unhealthy’ state, the IPs on that node automatically move to another node in the pool.
- When a node transitions back to a ‘healthy’ state, IPs will automatically move back to that node, assuming the rebalance policy is set to ‘auto’ and there are enough IPs available.
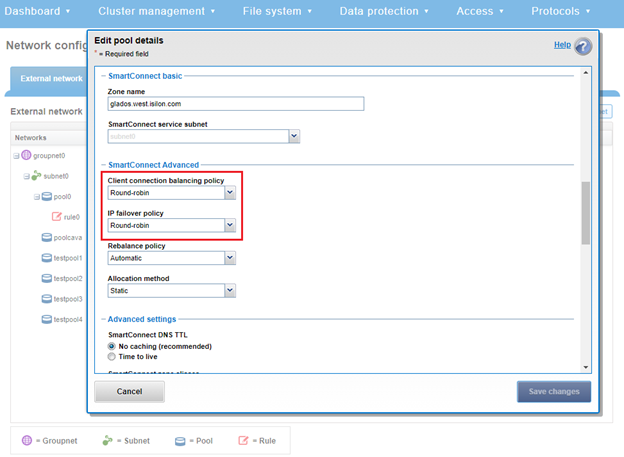
By default, OneFS SmartConnect balances connections among nodes using a round-robin policy and a separate IP pool for each subnet. A SmartConnect license adds advanced balancing policies to evenly distribute CPU usage, client connections, or throughput. It also lets you define IP address pools to support multiple DNS zones in a subnet.
| Load-balancing Policy | General | Few Clients with High Usage | Many Persistent NFS & SMB Connections | Many Ephemeral Connections (HTTP, FTP) | NFS Automount of UNC Paths are Used |
| Round Robin (Default) | | | | | |
| Connection Count | | | | | |
| CPU Usage | |||||
| Network Throughput |
Connection policies other than round robin are sampled every 10 seconds. The CPU policy is sampled every 5 seconds. If multiple requests are received during the same sampling interval, SmartConnect will attempt to balance these connections by estimating or measuring the additional load.
A ‘round robin’ load balancing strategy is generally a safe bet for both client connection balancing and IP failover.
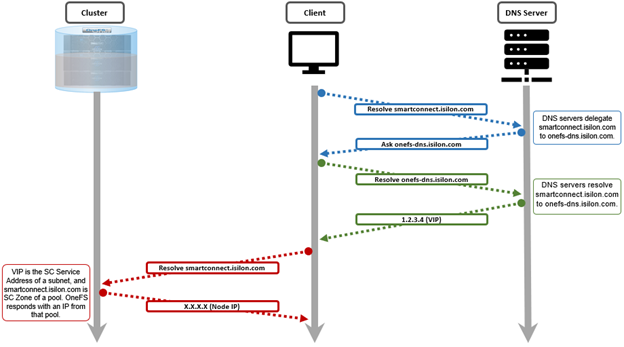
Under the hood, SmartConnect acts as DNS delegation server, responding to requests and returning IP addresses for the appropriate SmartConnect zone(s). The general transactional flow is as follows:
During a cluster ‘split’ or ‘merge’ group change the SmartConnect service will not respond to DNS inquiries. This is seldom as group changes typically take around 30 seconds. However, the time taken for a group change to complete can vary due to the load on the cluster at the time of the change. Any time a node is added, removed, or rebooted in a cluster there will be two group changes that cause SmartConnect to be impacted, one from down/split and one from up/merge.
For large clusters, if group changes are adversely impacting SmartConnect’s load-balancing performance, the core site DNS servers can be configured to use a Round Robin configuration instead of redirecting DNS requests to SmartConnect
SmartConnect supports IP failover to provide continuous access to data when hardware or a network path fails. Dynamic failover is recommended for high availability workloads on SmartConnect subnets that handle traffic from NFS clients.
For optimal network performance, avoid mixing interface types (100/40/25/10 GbE) in the same SmartConnect Pool and/or mixing node types with different performance profiles, such as H700 and A300 interfaces, for example. In general, the ‘round-robin’ SmartConnect Client Connection Balancing and IP-failover policies provide the most consistent results.
To evenly distribute connections and optimize performance, the recommendation is to size SmartConnect for the expected number of connections and for the anticipated overall throughput likely to be generated. The sizing factors for a pool include the total number of concurrently active client connections, the anticipated aggregate throughput for the pool, and he minimum performance and throughput requirements in case an interface fails.
Since OneFS is a single volume, fully distributed file system, a client can access all the files and associated metadata that are stored on the cluster, regardless of the type of node a client connects to or the node pool on which the data resides. For example, data stored for performance reasons on a pool of F-Series all-flash nodes can be mounted and accessed by connecting to an A-Series node in the same cluster. The different types of PowerScale nodes, however, deliver different levels of performance.
To avoid unnecessary network latency under most circumstances, the recommendation is to configure SmartConnect subnets such that client connections are to the same physical pool of nodes on which the data resides. In other words, if a workload’s data lives on a pool of F600 nodes for performance reasons, the clients that work with that data should mount the cluster through a pool that includes the same F600 nodes that host the data.
Keep in mind the following networking and name server considerations:
- Minimize disruption by suspending nodes in preparation for planned maintenance and resuming them after maintenance is complete
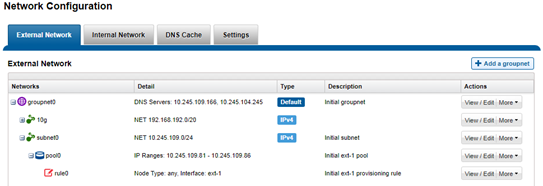
- Leverage the groupnet feature to enhance multi-tenancy and DNS delegation, where desirable.
- Ensure traffic flows through the right interface by tracing routes. Leverage OneFS Source-Based Routing (SBR) feature to keep traffic on desired paths.
If firewalling or filtering is deployed within the network, ensure that the appropriate ports are open. For example, open both UDP port 53 and TCP port 53 for the DNS service.
The client never sends a DNS request directly to the cluster. Instead, the site nameservers handle DNS requests from clients and route the requests appropriately.
In order to successfully distribute IP addresses, the OneFS SmartConnect DNS delegation server answers DNS queries with a time-to-live (TTL) of 0 so that the answer is not cached. Certain DNS servers (particularly Windows DNS Servers) will fix the value to one second. If you have many clients requesting an address within the same second, this will cause all of them to receive the same address. If you encounter this problem, you may need to use a different DNS server, such as BIND.
Certain clients perform DNS caching and might not connect to the node with the lowest load if they make multiple connections within the lifetime of the cached address. Recommend turning off client DNS caching, where possible. To handle client requests properly, SmartConnect requires that clients use the latest DNS entries.
The site DNS servers must be able to communicate with the node that is currently hosting the SmartConnect service. This is the node with the lowest logical node number (LNN) with an active interface in the subnet that contains the SSIP address.