As part of new OneFS 9.3 release’s support for NFSv4.1 and NFSv4.2, the NFS session model, is now incorporated into the OneFS NFS stack, which allows clients to leverage trunking and its associated performance benefits. Similar to multi-pathing in the SMB3 world, NFS trunking enables the use of multiple connections between a client and the cluster in order to dramatically increase the I/O path.
OneFS 9.3 supports both session and client ID trunking:
- Client ID trunking is the association of multiple sessions per client.
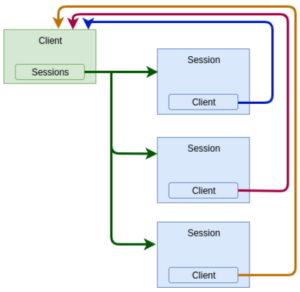
- Session trunking involves multiple connections per mount.
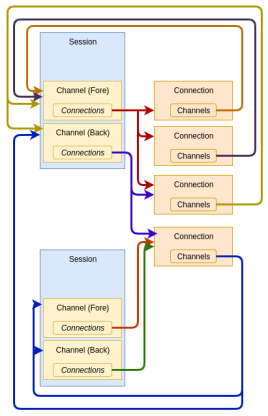
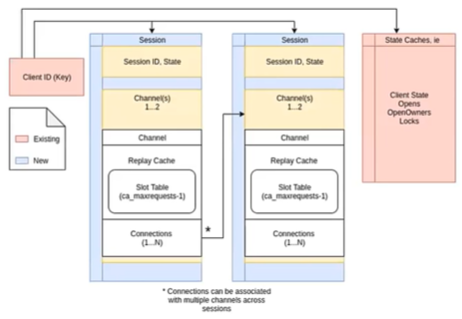
A connection, which represents a socket, exists within an object called a channel, and there can be many sessions associated with a channel. The fore channel represents client > cluster communication, and the back channel cluster > client.
Each channel has a set of configuration values that affect a session’s connections. With a few exceptions, the cluster must respect client-negotiated values. Typically, the configuration value meanings are the same for both the fore and back channels, although the defaults are typically significantly different for each.
Also, be aware that there can only be one client per session, but multiple sessions per client. And here’s what combined session and client ID trunking looks like:
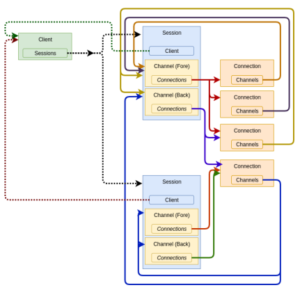
Most Linux flavors support session trunking via the ‘nconnect’ option within the ‘mount’ command, which is included in kernel version 5.3 and later. However, support for client ID trunking is fairly nascent across the current Linux distributions. As such, we’ll focus on session trunking for the remainder of this article.
So let’s walk through a simple example of configuring NFS v4.1 and session trunking in OneFS 9.3.
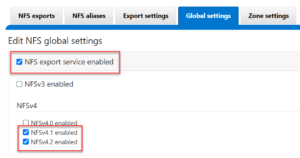
The first step is to enable the NFS service, if it’s not already running, and select the desired protocol versions. This can be done from the CLI via the following command syntax:
# isi services nfs enable
# isi nfs settings global modify --nfsv41-enabled=true --nfsv42-enabled=true
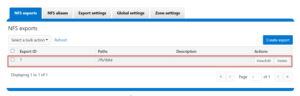
Next, create an NFS export:
# isi nfs exports create --paths=/ifs/data
When using NFSv4.x, the domain name should be uniform across both the cluster and client(s). The NFSv4.x domain is presented as user@domain or group@domain pairs in ‘getattr’ and ‘setattr’ operations, for example. If the domain does not match, new and existing files will appear as owned by user ‘nobody’ user on the cluster.
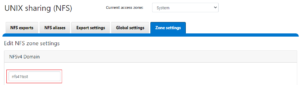
The cluster’s NFSv4.x domain can be configured via the CLI using the ‘isi nfs settings zone modify’ command as follows:
# isi nfs settings zone modify --nfsv4-domain=nfs41test --zone=System
Once the cluster is configured, the next step is to prepare the NFSv4.1 client(s). As mentioned previously, Linux clients running the 5.3 kernel or later can use the nconnect mount option to configure session trunking.
Note that the current maximum limit of client-server connections opened by nconnect is 16. If unspecified, this value defaults to 1.
The following example uses an Ubuntu 21.04 client with the Linux 5.11 kernel version. The linux client will need to have the ‘nfs-common’ package installed in order to obtain the necessary nconnect binaries and libraries. If not already present, this can be installed as follows:
# sudo apt-get install nfs-common nfs-kernel-server
Next, edit the client’s /etc/idmapd.conf and add the appropriate the NFSv4.x domain:
# cat /etc/idmapd.conf [General] Verbosity = 0 Pipefs-Directory = /run/rpc_pipefs # set your own domain here, if it differs from FQDN minus hostname Domain = nfs41test [Mapping] Nobody-User = nobody Nobody-Group = nogroup
NFSv4.x clients use the nfsidmap daemon for the NFSv4.x ID <-> name mapping translation, and the following CLI commands will restart the nfs-idmapd daemon and confirm that it’s happily running:
# systemctl restart nfs-idmapd
# systemctl status nfs-idmapd nfs-idmapd.service - NFSv4 ID-name mapping service Loaded: loaded (/lib/systemd/system/nfs-idmapd.service; static) Active: active (running) since Thurs 2021-11-18 19:47:01 PDT; 6s ago Process: 2611 ExecStart=/usr/sbin/rpc.idmapd $RPCIDMAPDARGS (code=exited, status=0/SUCCESS) Main PID: 2612 (rpc.idmapd) Tasks: 1 (limit: 4595) Memory: 316.0K CGroup: /system.slice/nfs-idmapd.service └─2612 /usr/sbin/rpc.idmapd Nov 18 19:47:01 ubuntu systemd[1]: Starting NFSv4 ID-name mapping service... Nov 18 25 19:47:01 ubuntu systemd[1]: Started NFSv4 ID-name mapping service.
The domain value can also be verified by running the nfsidmap command as follows:.
# sudo nfsidmap -d nfs41test
Next, mount the cluster’s NFS export via NFSv4.1, v4.2, and trunking, as desired. For example, the following syntax will establish an NFSv4.1 mount using 4 trunked sessions, specified via the nconnect argument:
# sudo mount -t nfs -vo nfsvers=4.1,nconnect=4 10.1.128.10:/ifs/data/ /mnt/nfs41
This can be verified on the client side by running nestat and grepping for port 2049, the output in this case confirming the four TCP connections established for the above mount, as expected:
# netstat -ant4 | grep 2049 tcp 0 0 0.0.0.0:2049 0.0.0.0:* LISTEN tcp 0 0 10.1.128.131:857 10.1.128.10:2049 ESTABLISHED tcp 0 0 10.1.128.131:681 10.1.128.10:2049 ESTABLISHED tcp 0 0 10.1.128.131:738 10.1.128.10:2049 ESTABLISHED tcp 0 0 10.1.128.131:959 10.1.128.10:2049 ESTABLISHED
Similarly, from the cluster side, the NFS connections can be checked with the OneFS ‘isi_nfs4mgmt’ CLI command. The command output includes the client ID, NFS version, session ID, etc.
# isi_nfs4mgmt –list ID Vers Conn SessionId Client Address Port O-Owners Opens Handles L-Owners 456576977838751506 4.1 n/a 4 912.168.198.131 959 0 0 0 0
The OneFS isi_nfs4mgmt CLI command also includes a ‘—dump’ flag, which when used with the ID as the argument, will display the details of a client mount, such as the TCP port, NFSv4.1 channel options, auth type, etc.
# isi_nfs4mgmt --dump=456576977838751506 Dump of client 456576977838751506 Open Owners (0): Session ID: 4 Forward Channel Connections: Remote: 10.1.128.131.959 Local: 10.1.128.10.2049 Remote: 10.1.128.131.738 Local: 10.1.128.10.2049 Remote: 10.1.128.131.857 Local: 10.1.128.10.2049 Remote: 10.1.128.131.681 Local: 10.1.128.10.2049 Attributes: header pad size 0 max operations 8 max request size 1048576 max requests 64 max response size 1048576 max response size cached 7584 Slots Used/Available: 1/63 Cache Contents: 0) SEQUENCE Back Channel Connections: Remote: 10.1.128.131.959 Local: 10.1.128.10.2049 Attributes: header pad size 0 max operations 2 max request size 4096 max requests 16 max response size 4096 max response size cached 0 Security Attributes: AUTH_SYS: gid 0 uid 0 Summary of Client 456576977838751506: Long Name (hex): 0x4c696e7578204e465376342e31207562756e74752e312f3139322e3136382e3139382e313000 Long Name (ascii): Linux.NFSv4.1.ubuntu.1/10.1.128.10. State: Confirmed Open Owners: 0 Opens: 0 Open Handles: 0 Lock Owners: 0 Sessions: 1 Full JSON dump can be found at /var/isi_nfs4mgmt/nfs_clients.dump_2021-11-18T15:25:18
Be aware that sessions trunking is not permitted across multi-tenant access zones, because of different auth levels, since a session represents a single auth level. Similarly, sessions trunking is disallowed across dynamic IP addresses.