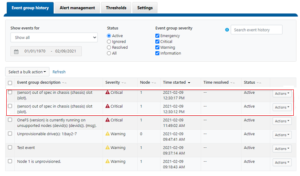
OneFS protects data stored on failing nodes or drives in a cluster through a process called Smartfail. During the process, OneFS places a device into quarantine and, depending on the severity of the issue, the data on it into a read-only state. While a device is quarantined, OneFS reprotects the data on the device by distributing the data to other devices.
After all data eviction or reconstruction is complete, OneFS logically removes the device from the cluster and the node or drive can be physically replaced. OneFS only automatically Smartfails devices as a last resort. Nodes and/or drives can also be manually Smartfailed. However, it is strongly recommended to first consult Dell Technical Support.
Occasionally a device might fail before OneFS detects a problem. If a drive fails without being Smartfailed, OneFS automatically starts rebuilding the data to available free space on the cluster. However, because a node might recover from a transient issue, if a node fails, OneFS does not start rebuilding data unless it is logically removed from the cluster.
A node that is unavailable and reported by isi status as ‘D’, or down, can be Smartfailed. If the node is hard down, likely with a significant hardware issue, the Smartfail process will take longer because data has to be recalculated from the FEC protection parity blocks. That said, it’s well worth attempting to bring the node up if at all possible – especially if the cluster and/or node pools is at the default +2D:1N protection. The concern here is that, with a node down, there is a risk of data loss if a drive or other component goes bad during the Smartfail process.
If possible, and assuming the disk content is still intact, it can often be quicker to have the node hardware repaired. In this case, the entire node’s chassis (or compute module in the case of Gen 6 hardware) could be replaced and the old disks inserted with original content on them. This should only be performed at the recommendation and under the supervision of Dell Technical support. If the node is down as a result of a journal inconsistency, it will have to be Smartfailed out. In this case, Support should be engaged to determine an appropriate action plan.
The recommended procedure for Smartfailing a node is as follows. In this example, we’ll assume that node 4 is down:
- From the CLI of any node except node 4, run the following command to Smartfail out the node:
# isi devices node smartfail --node-lnn 4
- Verify that node is removed from the cluster.
# isi status –q
(An ‘—S-’ will appear in node 4’s ‘Health’ column to indicate it has been Smartfailed).
- Monitor the successful completion of the job engine’s MultiScan, FlexProtect/FlexProtectLIN jobs:
# isi job status
- Un-cable and remove the node from the rack for disposal
As mentioned above, there are two primary Job Engine jobs that run as a result of a Smartfail:
- MultiScan
- FlexProtect or FlexProtectLIN
MultiScan performs the work of the both AutoBalance and Collect jobs simultaneously, and it is triggered after every group change. The reason is that new file layouts and file deletions that happen during a disruption to the cluster may be imperfectly balanced or, in the case of deletions, simply lost.
The Collect job reclaims free space from previously unavailable nodes or drives. A mark and sweep garbage collector, it identifies everything valid on the filesystem in the first phase, then in the second phase scans the drives freeing anything that isn’t marked valid.
AutoBalance ensures that, when node and drive usage across the cluster are out of balance. This job scans through all the drives looking for files to re-layout to make use of the less filled devices.
The purpose of the FlexProtect job is to scan the file system after a device failure to ensure that all files remain protected. Incomplete protection levels are fixed, in addition to missing data or parity blocks caused by drive or node failures. This job is started automatically after Smartfailing a drive or node. If a Smartfailed device was the reason the job started, the device is marked gone (completely removed from the cluster) at the end of the job.
Although a new node can be added to a cluster at any time, it’s best to avoid major group changes during a Smartfail operation. This helps avoid any unnecessary interruptions of a critical job engine data reprotection job. However, since a node is down, there is a window of risk while the cluster is rebuilding the data from that cluster. Under pressing circumstances the Smartfail operation can be paused, the node added, and then Smartfail resumed once the new node has happily joined the cluster.
Be aware that, if the node you are adding is the same node that was Smartfailed, the cluster maintains a record of that node and may prevent the re-introduction of that node until the Smartfail is complete. To mitigate risk, Dell Technical Support should definitely be involved to ensure data integrity.
The time for a Smartfail to complete is hard to predict with any accuracy, and is dependent on:
| Attribute | Description |
| OneFS release | Determines OneFS job engine version and how efficiently it operates. |
| System hardware | Drive types, CPU, RAM, etc. |
| File system | Quantity and type of data (ie. small vs large files), protection, tunables, etc. |
| Cluster load | Processor and CPU utilization, capacity utilization, etc. |
Typical Smartfail runtimes range from minutes for fairly empty, idle nodes with SSD and SAS drives to days for nodes with large SATA drives and a high capacity utilization. The FlexProtect job already runs at the highest job engine priority (value=1) and medium impact by default. As such, there isn’t much that can be done to speed up this job, beyond reducing cluster load.
Smartfail is also a valuable tool for proactive cluster node replacement, for example during a hardware refresh. Provided cluster quorum is not broken, a Smartfail can be initiated on multiple nodes concurrently – but never more than n/2 – 1 nodes (rounded up)!
If replacing an entire node-pool as part of a tech refresh, a SmartPools filepool policy can be crafted to migrate the data to another nodepool across the back-end network. When complete, the nodes can then be Smartfailed out, which should progress swiftly since they are now empty.
If multiple nodes are Smartfailed simultaneously, at the final stage of the process the node remove is serialized with around 60 seconds pause between each. The Smartfail job places the selected nodes in read-only mode while it copies the protection stripes to the cluster’s free space. Using SmartPools to evacuate data from a node or set of nodes in preparation to remove them is generally a good idea, and is usually a relatively fast process.
SmartPools’ Virtual Hot Spare (VHS) functionality helps ensure that node pools maintain enough free space to successfully re-protect data in the event of a Smartfail. Though configured globally, VHS actually operates at the node pool level so that nodes with different size drives reserve the appropriate VHS space. This helps ensures that, while data may move from one disk pool to another during repair, it remains on the same class of storage. VHS reservations are cluster wide and configurable as either a percentage of total storage (0-20%) or as a number of virtual drives (1-4), with the default being 10%.
Note, a Smartfail is not guaranteed to remove all data on a node. Any pool in a cluster that’s flagged with the ‘System’ flag can store /ifs/.ifsvar data. A filepool policy to move the regular data won’t address this data. Also, since SmartPools ‘spillover’ may have occurred at some point, there are no guarantees that an ‘empty’ node is completely devoid of data. For this reason, OneFS still has to search the tree for files that may have blocks residing on the node.
Nodes can be easily Smartfailed via the OneFS WebUI by navigating to Cluster Management > Hardware Configuration and selecting ‘Actions > More > Smartfail Node’ for the desired node(s):
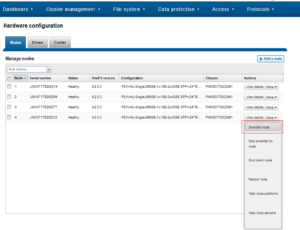
Similarly, the following CLI commands initiate and halt the node Smartfail process respectively. Firstly, the ‘isi devices node smartfail’ command kicks off the Smartfail process on a node and removes it from the cluster.
# isi devices node smartfail -h
Syntax
# isi devices node smartfail [--node-lnn <integer>] [--force | -f] [--verbose | -v]
If necessary, the ‘isi devices node stopfail’ command can be used to discontinue the Smartfail process on a node.
# isi devices node stopfail -h Syntax isi devices node stopfail [--node-lnn <integer>] [--force | -f] [--verbose | -v]
Similarly, individual drives within a node can be Smartfailed with the ‘isi devices drive smartfail’ CLI command.
# isi devices drive smartfail { <bay> | --lnum <integer> | --sled <string> }
[--node-lnn <integer>]
[{--force | -f}]
[{--verbose | -v}]
[{--help | -h}]
When it comes to Smartfailing PowerScale chassis-based nodes, there are a couple of other things to be aware of regarding the mirrored journal:
- When you smartfail a node in a node pair, you do not have to smartfail its partner node.
- A node will still run indefinitely with its partner missing. However, this significantly increases the window of risk since there’s no journal mirror to rely on (in addition to lack of redundant power supply, etc).
- If you do smartfail a single node in a pair, the journal is still protected by the vault and powerfail memory persistence.