In this final blog of this series, we’ll look at SmartSync’s diagnostic tools, performance, plus review some of its idiosyncrasies and coexistence with other OneFS features.
But first, performance. Unlike SyncIQ, which operates solely on a push model, SmartSync allows pull replication, too. This can be an incredibly useful performance option for environments that grow organically. As demand for replication on a source cluster increases, the additional compute and network load needs to be considered. Push replication, especially with multiple targets, can generate a significant load on the source cluster, as shown in CPU graphs in the following graphic:
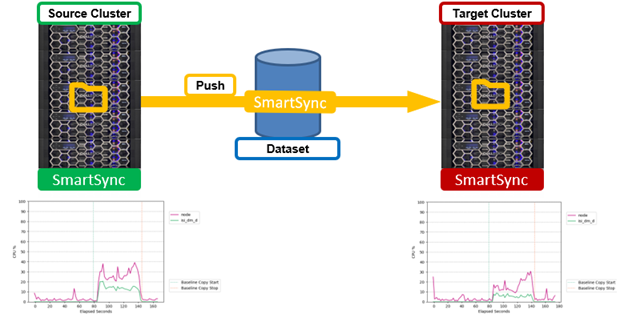
In extreme cases, replication traffic resource utilization can potentially impact client workloads as data is pushed to the target. On the other hand, enabling a pull replication model for a dataset can drastically reduce the resource impacts on the source cluster’s CPU utilization by offloading replication overhead to the target cluster. This can be seen in the following graphs:
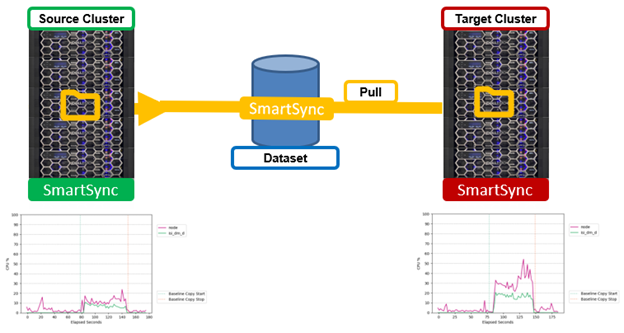
For single-source dataset environments with numerous targets, pull replication can free up the source cluster’s compute and network resources, which can then be used more beneficially for client IO. However, if the target cluster is a capacity-optimized archive cluster without CPU and/or network resources to spare, a pull policy model, rather than the traditional push, may not be an option. In such cases, SmartSync also allows its policies to be limited, or throttled, in order to reduce system and/or network resource impacts from replication. SmartSync throttling come in two flavors: Bandwidth and CPU throttling.
- Bandwidth throttling is specified through a set of netmask rules plus a maximum throughput limit, and is configured via the ‘isi dm throttling’ CLI syntax:
# isi dm throttling bw-rules create NETMASK – [subnet] --bw-limit= command
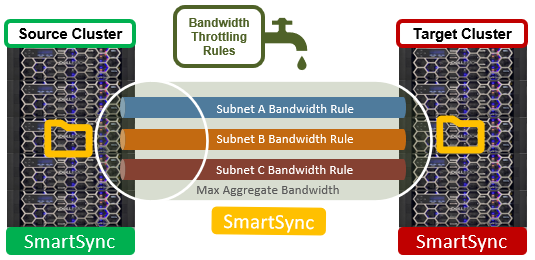
Bandwidth limits are specified in bytes for a specific subnet and netmask. For example:
# isi dm throttling bw-rules create NETMASK --netmask 10.20.100.0/24 --bw-limit=$((20*1024*1024))
In this case, the bandwidth limit of 20MB (20*1024*1024 bytes) is applied to the 10.20.100.0 class C subnet. The throttling configuration change can be verified as follows:
# isi dm throttling bw-rules list
ID Rule Type Netmask Bw Limit
------------------------------------------
0 NETMASK 10.20.100.0/24 20.00MB
------------------------------------------
Total: 1
- Compute-wise, SmartSync policies by default can consume up to 30% of a node’s CPU cycles if its total CPU usage is less than 90%. If the node’s total CPU utilization reaches 90%, or if the SmartSync consumption reaches 30% of the total CPU, SmartSync automatically throttles its CPU consumption.
Additional CPU throttling is specified through ‘allowed CPU percentage’ and ‘backoff CPU percentage’ limits, which are also configured via the ‘isi dm throttling’ CLI command syntax.
The ‘allowed CPU Threshold’ paramater sets the always-allowed CPU cycles that SmartSync is allowed to use, regardless of the overall node CPU usage. If system’s CPU usage crosses the ‘System CPU Load Threshold’ and SmartSync uses more than the ‘Allowed CPU Threshold’, it will then throttle CPU utilization to remain at or below the ‘Allowed CPU Threshold’.
For example, to set the allowed CPU threshold to 20% and the system CPU threshold to 80%:
# isi dm throttling settings view
Allowed CPU Threshold: 30
System CPU Load Threshold: 90
# isi dm throttling settings modify --allowed-cpu-threshold 20 --system-cpu-load-threshold 80
# isi dm throttling settings view
Allowed CPU Threshold: 20
System CPU Load Threshold: 80
Additionally, SmartSync performance is also aided by a scalable run-time engine, spanning the cluster, and which spins up threads (fibers) on demand and uses asynchronous IO to process replication tasks (chunks). Batch operations are used for efficient small file, attribute, and data block transfer. Namespace contention avoidance, efficient snapshot utilization, and separation of dataset creation from transfer are salient design features of the both the baseline and incremental sync algorithms. Plus, the availability of a pull transfer model can significantly reduce the impact on a source cluster, if needed.
On the caveats and considerations front, SmartSync v1 in OneFS 9.4 does have some notable limitations to be cognizant of. Notably, failover and failback of a SmartSync policy option is not currently supported, nor is an option to allow writes on the target cluster. However, the dataset is available for read and write on copy policies once the replication to the target platform is complete if the ‘–copy-createdataset-on-target=false’ option is specified. These limitations will be lifted in a future OneFS release. But for now, if required, repeat-copy data on the target platform may be copied out of the SmartSync data mover snapshot.
Other interoperability considerations include:
| Component |
Interoperability |
| ADS/resource forked files |
With CloudCopy, only the main file stored; Alternate data stream/resource fork skipped when encountered. |
| Cloud copy-back |
Not supported unless data was created by a OneFS Datamover. |
| Cloud incrementals |
Unsupported for file->object transfers. One-time copy to/from cloud only. |
| CloudPools |
CloudPools Smartlink stub files are not supported. |
| Compression |
Compression for replication transfer is not supported. |
| Failover/failback policy |
Failover and failback option is not available, nor is an option to allow writes on the target cluster. |
| File metadata |
With CloudCopy, only POSIX UID, GID, atime, mtime, and ctime are copied. |
| File name encoding |
With CloudCopy, all encodings are converted to UTF-8. |
| Hadoop TDE |
SmartSync does not support the replication of the TDE domain and keys, rendering TDE encrypted data on the target cluster inaccessible. |
| Hard links |
With CloudCopy, hard links are not preserved, and a file/object is created for each link. |
| Inline data reduction |
Inline compressed and/or deduped data is rehydrated, decompressed, and transferred uncompressed to the target cluster. |
| Large files (4TB –> 16 TB) |
Supported up to the cloud provider’s maximum object size. SmartSync policies only connect with target clusters that also have large file support enabled. |
| RBAC |
SmartSync administrative access is assigned through the ISI_PRIV_DATAMOVER privilege |
| SFSE |
SFSE containerized small files are unpacked on the source cluster before replication. |
| SmartDedupe |
Deduplicated files are rehydrated back to their original size prior to replication. |
| SmartLock |
Compliance mode cluster are not supported with SmartSync. |
| SnapshotIQ |
Tightly integrated; uses snapshots for incrementals and re-baselining. |
| Sparse files |
With CloudCopy, sparse regions of files are written out as zeros. |
| Special files |
With CloudCopy, special files are skipped when encountered. |
| Symbolic links |
With CloudCopy, symlinks are skipped when encountered. |
| SyncIQ |
SmartSync and SyncIQ replication both happily coexist. An active SyncIQ license is required for both. |
When it comes to monitoring and troubleshooting SmartSync, there are a variety of diagnostic tools available. These include:
| Component |
Tools |
Issue |
| Logging |
· /var/log/isi_dm.log
· /var/log/messages
· ifs/data/Isilon_Support/datamover/transfer_failures/baseline_failures_ <jobid> |
General SmartSync info and triage. |
| Accounts |
· isi dm accounts list / view |
Authentication, trust and encryption. |
| CloudCopy |
· S3 Browser (ie. Cloudberry), Microsoft Azure Storage Explorer |
Cloud access and connectivity. |
| Dataset |
· isi dm dataset list/view |
Dataset creation and health. |
| File system |
· isi get |
Inspect replicated files and objects. |
| Jobs |
· isi dm jobs list/view
· isi_datamover_job_status -jt |
Job and task execution, auto-pausing, completion, control, and transfer. |
| Network |
· isi dm throttling bw-rules list/view
· isi_dm network ping/discover |
Network connectivity and throughput. |
| Policies |
· isi dm policies list/view
· isi dm base-policies list/view |
Copy and dataset policy execution and transfer. |
| Service |
· isi services -a isi_dm_d <enable/disable> |
Daemon configuration and control. |
| Snapshots |
· isi snapshot snapshots list/view |
Snapshot execution and access. |
| System |
· isi dm throttling settings |
CPU load and system performance. |
SmartSync info and errors are typically written to /var/log/isi_dm.log and /var/log/messages, while DM jobs transfer failures generate a log specific to the job ID under /ifs/data/Isilon_Support/datamover/transfer_failures.
Once a policy is running, the job status is reported via ‘isi dm jobs list’. Once complete, job histories are available by running ‘isi dm historical jobs list’. More details for a specific job can be glean from the ‘isi dm job view’ command, using the pertinent job ID from the list output above. Additionally, the ‘isi_datamover_job_status’ command with the job ID as an argument will also supply detailed information about a specific job.
Once running, a DM job can be further controlled via the ‘isi dm jobs modify’ command, and available actions include cancel, partial-completion, pause, or resume.
If a certificate authority (CA) is not correctly configured on a PowerScale cluster, the SmartSync daemon will not start, even though accounts and policies can still be configured. Be aware that the failed policies will not be reported via ‘isi dm jobs list’ or ‘isi dm historical-jobs list’ since they never started. Instead, an improperly configured CA is reported in the /var/log/isi_dm.log as follows:
Certificates not correctly installed, Data Mover service sleeping: At least one CA must be installed: No such file or directory from dm_load_certs_from_store (/b/mnt/src/isilon/lib/isi_dm/isi_dm_remote/src/rpc/dm_tls.cpp:197 ) from dm_tls_init (/b/mnt/src/isilon/lib/isi_dm/isi_dm_remote/src/rpc/dm_tls.cpp:279 ): Unable to load certificate information
Once a CA and identity are correctly configured, the SmartSync service automatically activates. Next, SmartSync attempts a handshake with the target cluster. If the CA or identity is mis-configured, the handshake process fails, and generates an entry in /var/log/isi_dm.log. For example:
2022-06-30T12:38:17.864181+00:00 GEN-HOP-NOCL-RR-1(id1) isi_dm_d[52758]: [0x828c0a110]: /b/mnt/src/isilon/lib/isi_dm/isi_dm_remote/src/acct_mon.cpp:dm_acc tmon_try_ping:348: [Fiber 3778] ping for account guid: 0000000000000000c4000000000000000000000000000000, result: dead
Note that the full handshake error detail is logged if the SmartSync service (isi_dm_d) is set to log at the ‘info’ or ‘debug’ level using isi_ilog:
# isi_ilog -a isi_dm_d --level info+
Valid ilog levels include:
fatal error err notice info debug trace
error+ err+ notice+ info+ debug+ trace+
A copy or repeat-copy policy requires an available dataset for replication before running. If a dataset has not been successfully created prior to the copy or repeat-copy policy job starting for the same base path, the job is paused. In the following example, the base path of the copy policy is not the same as that of the dataset policy, hence the job fails with a “path doesn’t match…” error.
# ls -l /ifs/data/Isilon_support/Datamover/transfer_failures
Total 9
-rw-rw---- 1 root wheel 679 June 29 10:56 baseline_failure_10
# cat /ifs/data/Isilon_support/Datamover/transfer_failures/baseline_failure_10
Task_id=0x00000000000000ce, task_type=root task ds base copy, task_state=failed-fatal path doesn’t match dataset base path: ‘/ifs/test’ != /ifs/data/repeat-copy’:
from bc_task)initialize_dsh (/b/mnt/src/isilon/lib/isi_dm/isi_dm/src/ds_base_copy
from dmt_execute (/b/mnt/src/isilon/lib/isi_dm/isi_dm/src/ds_base_copy_root_task
from dm_txn_execute_internal (/b/mnt/src/isilon/lib/isi_dm/isi_dm_base/src/txn.cp
from dm_txn_execute (/b/mnt/src/isilon/lib/isi_dm/isi_dm_base/src/txn.cpp:2274)
from dmp_task_spark_execute (/b/mnt/src/isilon/lib/isi_dm/isi_dm/src/task_runner.
Once any errors for a policy have been resolved, the ‘isi dm jobs modify’ command can be used to resume the job.