There have been a number of questions from the field recently around how to calculate the OneFS storage protection overhead for different cluster sizes and protection levels. But first, a quick overview of the fundamentals…
OneFS supports several protection schemes. These include the ubiquitous +2d:1n, which protects against two drive failures or one node failure. The best practice is to use the recommended protection level for a particular cluster configuration. This recommended level of protection is clearly marked as ‘suggested’ in the OneFS WebUI storage pools configuration pages and is typically configured by default. For all current Gen6 hardware configurations, the recommended starting protection level is “+2d:1n’.
The hybrid protection schemes are particularly useful for the chassis-based high-density node configurations, where the probability of multiple drives failing far surpasses that of an entire node failure. In the unlikely event that multiple devices have simultaneously failed, such that the file is “beyond its protection level”, OneFS will re-protect everything possible and report errors on the individual files affected to the cluster’s logs.
OneFS also provides a variety of mirroring options ranging from 2x to 8x, allowing from two to eight mirrors of the specified content. Metadata, for example, is mirrored at one level above FEC by default. For example, if a file is protected at +2n, its associated metadata object will be 3x mirrored.
The full range of OneFS protection levels are as follows:
| Protection Level | Description |
| +1n | Tolerate failure of 1 drive OR 1 node |
| +2d:1n | Tolerate failure of 2 drives OR 1 node |
| +2n | Tolerate failure of 2 drives OR 2 nodes |
| +3d:1n | Tolerate failure of 3 drives OR 1 node |
| +3d:1n1d | Tolerate failure of 3 drives OR 1 node AND 1 drive |
| +3n | Tolerate failure of 3 drives or 3 nodes |
| +4d:1n | Tolerate failure of 4 drives or 1 node |
| +4d:2n | Tolerate failure of 4 drives or 2 nodes |
| +4n | Tolerate failure of 4 nodes |
| 2x to 8x | Mirrored over 2 to 8 nodes, depending on configuration |
The charts below show the ‘ideal’ protection overhead across the range of OneFS protection levels and node counts. For each field in this chart, the overhead percentage is calculated by dividing the sum of the two numbers by the number on the right.
x+y => y/(x+y)
So, for a five node cluster protected at +2d:1n, OneFS uses an 8+2 layout – hence an ‘ideal’ overhead of 20%.
8+2 => 2/(8+2) = 20%
| Number of nodes | [+1n] | [+2d:1n] | [+2n] | [+3d:1n] | [+3d:1n1d] | [+3n] | [+4d:1n] | [+4d:2n] | [+4n] |
| 3 | 2 +1 (33%) | 4 + 2 (33%) | — | 6 + 3 (33%) | 3 + 3 (50%) | — | 8 + 4 (33%) | — | — |
| 4 | 3 +1 (25%) | 6 + 2 (25%) | — | 9 + 3 (25%) | 5 + 3 (38%) | — | 12 + 4 (25%) | 4 + 4 (50%) | — |
| 5 | 4 +1 (20%) | 8+ 2 (20%) | 3 + 2 (40%) | 12 + 3 (20%) | 7 + 3 (30%) | — | 16 + 4 (20%) | 6 + 4 (40%) | — |
| 6 | 5 +1 (17%) | 10 + 2 (17%) | 4 + 2 (33%) | 15 + 3 (17%) | 9 + 3 (25%) | — | 16 + 4 (20%) | 8 + 4 (33%) | — |
The ‘x+y’ numbers in each field in the table also represent how files are striped across a cluster for each node count and protection level.
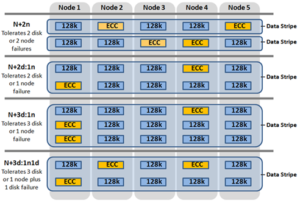
Take for example, with +2n protection on a 6-node cluster, OneFS will write a stripe across all 6 nodes, and use two of the stripe units for parity/ECC and four for data.
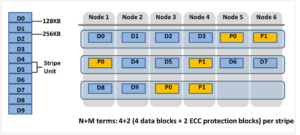
In general, for FEC protected data the OneFS protection overhead will look something like below.
Note that the protection overhead % (in brackets) is a very rough guide and will vary across different datasets, depending on quantities of small files, etc.
| Number of nodes | [+1n] | [+2d:1n] | [+2n] | [+3d:1n] | [+3d:1n1d] | [+3n] | [+4d:1n] | [+4d:2n] | [+4n] |
| 3 | 2 +1 (33%) | 4 + 2 (33%) | — | 6 + 3 (33%) | 3 + 3 (50%) | — | 8 + 4 (33%) | — | — |
| 4 | 3 +1 (25%) | 6 + 2 (25%) | — | 9 + 3 (25%) | 5 + 3 (38%) | — | 12 + 4 (25%) | 4 + 4 (50%) | — |
| 5 | 4 +1 (20%) | 8 + 2 (20%) | 3 + 2 (40%) | 12 + 3 (20%) | 7 + 3 (30%) | — | 16 + 4 (20%) | 6 + 4 (40%) | — |
| 6 | 5 +1 (17%) | 10 + 2 (17%) | 4 + 2 (33%) | 15 + 3 (17%) | 9 + 3 (25%) | — | 16 + 4 (20%) | 8 + 4 (33%) | — |
| 7 | 6 +1 (14%) | 12 + 2 (14%) | 5 + 2 (29%) | 15 + 3 (17%) | 11 + 3 (21%) | 4 + 3 (43%) | 16 + 4 (20%) | 10 + 4 (29%) | — |
| 8 | 7 +1 (13%) | 14 + 2 (12.5%) | 6 + 2 (25%) | 15 + 3 (17%) | 13 + 3 (19%) | 5 + 3 (38%) | 16 + 4 (20%) | 12 + 4 (25%) | — |
| 9 | 8 +1 (11%) | 16 + 2 (11%) | 7 + 2 (22%) | 15 + 3 (17%) | 15 + 3 (17%) | 6 + 3 (33%) | 16 + 4 (20%) | 14 + 4 (22%) | 5 + 4 (44%) |
| 10 | 9 +1 (10%) | 16 + 2 (11%) | 8 + 2 (20%) | 15 + 3 (17%) | 15 + 3 (17%) | 7 + 3 (30%) | 16 + 4 (20%) | 16 + 4 (20%) | 6 + 4 (40%) |
| 12 | 11 +1 (8%) | 16 + 2 (11%) | 10 + 2 (17%) | 15 + 3 (17%) | 15 + 3 (17%) | 9 + 3 (25%) | 16 + 4 (20%) | 16 + 4 (20%) | 6 + 4 (40%) |
| 14 | 13 +1 (7%) | 16 + 2 (11%) | 12 + 2 (14%) | 15 + 3 (17%) | 15 + 3 (17%) | 11 + 3 (21%) | 16 + 4 (20%) | 16 + 4 (20%) | 10 + 4 (29%) |
| 16 | 15 +1 (6%) | 16 + 2 (11%) | 14 + 2 (13%) | 15 + 3 (17%) | 15 + 3 (17%) | 13 + 3 (19%) | 16 + 4 (20%) | 16 + 4 (20%) | 12 + 4 (25%) |
| 18 | 16 +1 (6%) | 16 + 2 (11%) | 16 + 2 (11%) | 15 + 3 (17%) | 15 + 3 (17%) | 15 + 3 (17%) | 16 + 4 (20%) | 16 + 4 (20%) | 14 + 4 (22%) |
| 20 | 16 +1 (6%) | 16 + 2 (11%) | 16 + 2 (11%) | 16 + 3 (16%) | 16 + 3 (16%) | 16 + 3 (16%) | 16 + 4 (20%) | 16 + 4 (20%) | 14 + 4 (22%) |
| 30 | 16 +1 (6%) | 16 + 2 (11%) | 16 + 2 (11%) | 16 + 3 (16%) | 16 + 3 (16%) | 16 + 3 (16%) | 16 + 4 (20%) | 16 + 4 (20%) | 14 + 4 (22%) |
The protection level of the file is how the system decides to layout the file. A file may have multiple protection levels temporarily (because the file is being restriped) or permanently (because of a heterogeneous cluster). The protection level is specified as “n + m/b@r” in its full form. In the case where b, r, or both equal 1, it may be elided to get “n + m/b”, “n + m@r”, or “n + m”.
| Layout Attribute | Description |
| N | Number of data drives in a stripe. |
| +m | Number of FEC drives in a stripe. |
| /b | Number of drives per stripe allowed on one node. |
| @r | Number of drives to include in the layout of a file. |
The OneFS protection definition in terms of node and/or drive failures has the advantage of configuration simplicity. However, it does mask some of the subtlety of the interaction between stripe width and drive spread, as represented by the n+m/b notation displayed by the ‘isi get’ CLI command. For example:
# isi get README.txt POLICY LEVEL PERFORMANCE COAL FILE default 6+2/2 concurrency on README.txt
In particular, both +3/3 and +3/2 allow for a single node failure or three drive failures and appear the same according to the web terminology. Despite this, they do in fact have different characteristics. +3/2 allows for the failure of any one node in combination with the failure of a single drive on any other node, which +3/3 does not. +3/3, on the other hand, allows for potentially better space efficiency and performance because up to three drives per node can be used, rather than the 2 allowed under +3/2.
That said, the protection level does have a minor affect on write performance. The largest impact is from the first number after the + in the protection level. For example, the the ‘+2’ levels (including +2n or +2d:1n) may be around 3% faster than the ‘+3’ levels (including +3n, +3d:1n1d, or +3d:1n). There is also some variation on depending on the number of nodes in a cluster, but typically this is less significant.
Another factor to keep in mind is OneFS neighborhoods. A neighborhood is a fault domains within a node pool, and their purpose is to improve reliability in general – and guard against data unavailability from the accidental removal of Gen6 drive sleds. For self-contained nodes like the PowerScale F200, OneFS has an ideal size of 20 nodes per node pool, and a maximum size of 39 nodes. On the addition of the 40th node, the nodes split into two neighborhoods of twenty nodes.
With the Gen6 platform, the ideal size of a neighborhood changes from 20 to 10 nodes. This 10-node ideal neighborhood size helps protect the Gen6 architecture against simultaneous node-pair journal failures and full chassis failures. Partner nodes are nodes whose journals are mirrored. Rather than each node storing its journal in NVRAM as in the PowerScale platforms, the Gen6 nodes’ journals are stored on SSDs – and every journal has a mirror copy on another node. The node that contains the mirrored journal is referred to as the partner node. There are several reliability benefits gained from the changes to the journal. For example, SSDs are more persistent and reliable than NVRAM, which requires a charged battery to retain state. Also, with the mirrored journal, both journal drives have to die before a journal is considered lost. As such, unless both of the mirrored journal drives fail, both of the partner nodes can function as normal.
With partner node protection, where possible, nodes will be placed in different neighborhoods – and hence different failure domains. Partner node protection is possible once the cluster reaches five full chassis (20 nodes) when, after the first neighborhood split, OneFS places partner nodes in different neighborhoods:
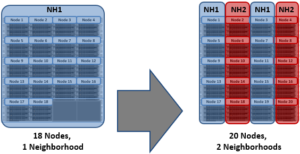
Partner node protection increases reliability because if both nodes go down, they are in different failure domains, so their failure domains only suffer the loss of a single node.
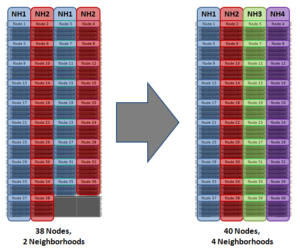
With chassis protection, when possible, each of the four nodes within a chassis will be placed in a separate neighborhood. Chassis protection becomes possible at 40 nodes, as the neighborhood split at 40 nodes enables every node in a chassis to be placed in a different neighborhood. As such, when a 38 node Gen6 cluster is expanded to 40 nodes, the two existing neighborhoods will be split into four 10-node neighborhoods:
Chassis protection ensures that if an entire chassis failed, each failure domain would only lose one node.