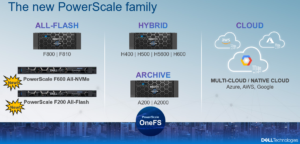
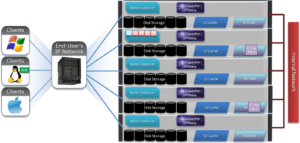
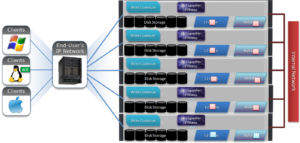
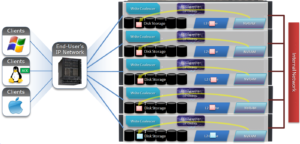
First introduced in version 9.0, OneFS supports the AWS S3 API as a protocol, extending the PowerScale data lake to natively include object, and enabling workloads which write data via file protocols such as NFS, HDFS or SMB, and then read that data via S3, or vice versa.
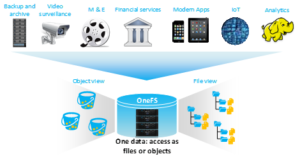
Because objects are files “under the hood”, the same OneFS data services, such as Snapshots, SyncIQ, WORM, etc, are all seamlessly integrated.
Applications now have multiple access options – across both file and object – to the same underlying dataset, semantics, and services, eliminating the need for replication or migration for different access requirements, and vastly simplifying management.
This makes it possible to run hybrid and cloud-native workloads, which use S3-compatible backend storage, for example cloud backup & archive software, modern apps, analytics flows, IoT workloads, etc. – and to run these on-prem, alongside and coexisting with traditional file-based workflows.
In addition to HTTP 1.1, OneFS S3 supports HTTPS 1.2, to meet organizations’ security and compliance needs. And since S3 is integrated as a top-tier protocol, performance is anticipated to be similar to SMB.
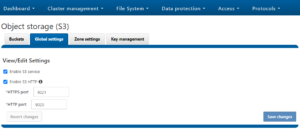
By default, the S3 service listens on port 9020 for HTTP and 9021 for HTTPS, although both these ports are easily configurable.
Every S3 object is linked to a file, and each S3 bucket maps to a specific directory called the bucket path. If the bucket path is not specified, a default is used. When creating a bucket, OneFS adds a dot-s3 directory under the bucket path, which is used to store temporary files for PUT objects.
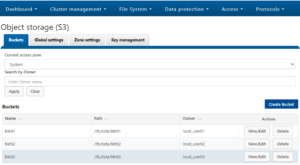
The AWS S3 data model is a flat structure, without a strict hierarchy of sub-buckets or sub-folders. However, it does provide a logical hierarchy, using object key-name prefixes and delimiters, which OneFS leverages to support a rudimentary concept of folders.
OneFS S3 also incorporates multi-part upload, using HTTP’s ‘100 continue’ header, allowing OneFS to ingest large objects, or copy existing objects, in parts, thereby improving upload performance.
OneFS allows both ‘virtual hosted-style requests’, where you specify a bucket in a request using the HTTP Host header, and also ‘path-style requests’, where a bucket is specified using the first slash-delimited component of the Request-URI path.
Every interaction with S3 is either authenticated or anonymous. While authentication verifies the identity of the requester, authorization controls access to the desired data. OneFS treats unauthenticated requests as anonymous, mapping it to the user ‘nobody’.
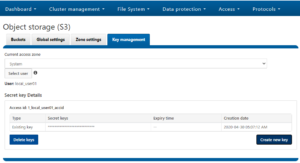
OneFS S3 uses either AWS Signature Version 2 or Version 4 to authenticate requests, which must include a signature value that authenticates the request sender. This requires the user to have both an access ID and a secret Key, which can be obtained from the OneFS key management portal.
The secret key is used to generate the signature value, along with several request header values. After receiving the signed request, OneFS uses the access ID to retrieve a copy of the secret key internally, recomputes the signature value of the request, and compares it against the received signature. If they match, the requester is authenticated, and any header value used in the signature is verified to be tamper-free.
Bucket ACLs control whether a user has permission on an S3 bucket. When receiving a request for a bucket operation, OneFS parses the user access ID from the request header and evaluates the request according to the target bucket ACL. To access OneFS objects, the S3 request must be authorized at both the bucket and object level, using permission enforcement based on the native OneFS ACLs.
Here’s the list of the principle S3 operations that OneFS 9.0 currently supports:
| Operation | S3 API name | Description | |
| DELETE object | DeleteObject | This operation enables you to delete a single object from a bucket. Delete multiple objects from a bucket using a single request is not supported. | |
| GET object | GetObject | Retrieves an object content. | |
| GET object ACL | GetObjectAcl | Get the access control list (ACL) of an object. | |
| HEAD object | HeadObject | The HEAD operation retrieves metadata from an object without returning the object itself. This operation is useful if you’re only interested in an object’s metadata. The operation returns a 200 OK if the object exists and you have permission to access it. Otherwise, the operation might return responses such as 404 Not Found and 403 Forbidden. | |
| PUT object | PutObject | Adds an object to a bucket. | |
| PUT object – copy | CopyObject | Creates a copy of an object that is already stored in OneFS. | |
| PUT object ACL | PutObjectAcl | Sets the access control lists (ACL) permissions for an object that already exists in a bucket. | |
| Initiate multipart upload | CreateMultipartUpload | Initiate a multipart upload and returns an upload ID. This upload ID is used to associate with all the parts in the specific multipart upload. You specify this upload ID in each of your subsequent upload part requests. You also include this upload ID in the final request to either complete or abort the multipart upload request. | |
| Upload part | UploadPart | Uploads a part in a multipart upload. Each part must be at least 5MB in size, except the last part. And max size of each part is 5GB. | |
| Upload part – Copy | UploadPartCopy | Upload a part by copying data from an existing object as data source. Each part must be at least 5MB in size, except the last part. And max size of each part is 5GB. | |
| Complete multipart upload | CompleteMultipartUpload | Completes a multipart upload by assembling previously uploaded parts. | |
| List multipart uploads | ListMultipartUploads | Lists in-progress multipart uploads. An in-progress multipart upload is a multipart upload that has been initiated using the Initiate Multipart Upload request but has not yet been completed or aborted. | |
| List parts | ListParts | List the parts that have been uploaded for a specific multipart upload. | |
| Abort multipart upload | AbortMultipartUpload | Abort a multipart upload. After a multipart upload is aborted, no additional parts can be uploaded using that upload ID. The storage consumed by any previously uploaded parts will be freed. However, if any part uploads are currently in progress, those part uploads might or might not succeed. As a result, it might be necessary to abort a given multipart upload multiple times in order to completely free all storage consumed by all parts. | |
Essentially, this includes the basic bucket and object create, read, update, delete, or CRUD, operations, plus multipart upload.
It’s worth noting that OneFS can accommodate individual objects up to 16TB in size, unlike AWS S3, which caps this at a maximum of 5TB per object.
Please be aware that OneFS 9.0 does not natively support versioning or Cross-Origin Resource Sharing (CORS). However, SnapshotIQ and SyncIQ can be used as a substitute for this functionality.
The OneFS S3 implementation includes a new WebUI and CLI for ease of configuration and management. This enables:
- The creation of buckets and configuration of OneFS specific options, such as object ACL policy
- The ability to generate access IDs and secret keys for users through the WebUI key management portal.
- Global settings, including S3 service control and configuration of the HTTP listening ports.
- Configuration of multi-tenant access zones, for multi-tenant support.
All the WebUI functionality and more is also available through the CLI using the new ‘isi s3’ command set:
|