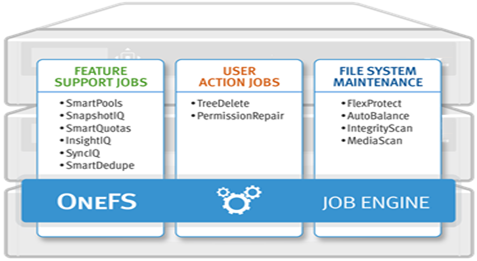
Within a PowerScale cluster, the OneFS Job Engine framework performs the background maintenance work on the cluster. It’s always there, but jobs come and go, and are run as necessary. Some of them are scheduled and executed automatically by the cluster, while others are run manually by cluster admins. Some of these jobs are very time critical like FlexProtect, who’s responsibility it is to reprotect data and help maintain and cluster’s availability and durability SLAs. Other jobs are less essential and perform general maintenance work, some optimizations, feature support, etc. And these can typically run with less criticality and a lower impact.
Some cluster administrators are blissfully unaware of the Job Engine’s existence, as it does its thing discretely behind the scenes, while others are distinctly more familiar with it.
The job engine uses the same set of resources as any clients accessing cluster. So the job engine has to manage how much CPU, memory, disk IO, etc, it uses, to avoid impinging upon client workloads. Obviously, if it consumes too much, the client loads will start to slow down and negatively impact customer productivity. The job engine manages its impact on client activity based on a set of internal disk IO and CPU metrics. But, until now, it has not paid attention to client load performance directly. So for protocol activity, the Job Engine in OneFS 9.7 and earlier does not monitor whether or not the latencies of protocol operations increase due to the jobs its running. And unfortunately, sometimes this results in client workloads being impacted more than desired. So OneFS 9.8 attempts to directly address this undesirable situation.
At its core, SmartThrottling is the Job Engine’s new automatic impact management framework.
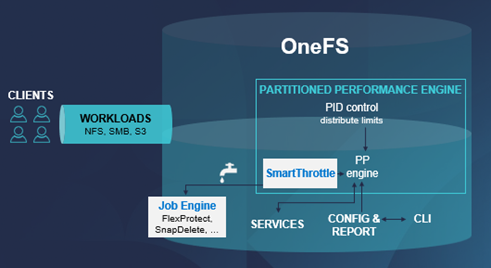
As such, it intelligently prioritizes primary client traffic, while automatically using any spare resources for cluster housekeeping.
It does this by dynamically throttling jobs forward and backward. And this means enhanced impact policy effectiveness, and improved predictability for cluster maintenance and data management tasks.
The read and write latencies of critical client protocol load are monitored, and SmartThrottling uses these metrics to keep the latencies within specified thresholds. As they approach the limit, the Job Engine stops increasing its work, and if latency exceeds the thresholds, it actively reduces the amount of work the jobs perform.
SmartThrottling also monitors the cluster’s drives and similarly maintains disk IO health within set limits. The actual job impact configuration remains unchanged in OneFS 9.8, and each job still has the same default level and priority as in prior releases.
But before we get into the nitty gritty of SmartThrottling, first, a quick Job Engine refresher.
The OneFS Job Engine itself is based on a delegation hierarchy made up of coordinator, director, manager, and worker processes.
Once the work is initially allocated, the Job Engine uses a shared work distribution model to process the work, and a unique Job ID identifies each job. When a job is launched, whether it is scheduled, started manually, or responding to a cluster event, the Job Engine spawns a child process from the isi_job_d daemon running on each node. This Job Engine daemon is also known as the parent process.
The Job Engine’s orchestration and job execution is handled by the coordinator process. Any node can act as the coordinator, and its principal responsibilities include:
- Monitoring workload and the constituent nodes’ status
- Controlling the number of worker threads per node and clusterwide
- Managing and enforcing job synchronization and checkpoints
While the individual nodes manage the actual work item allocation, the coordinator node takes control, divvies up the job, and evenly distributes the resulting tasks across the nodes in the cluster. The coordinator also periodically sends messages, through the director processes, instructing the managers to increment or decrement the number of worker threads as appropriate.
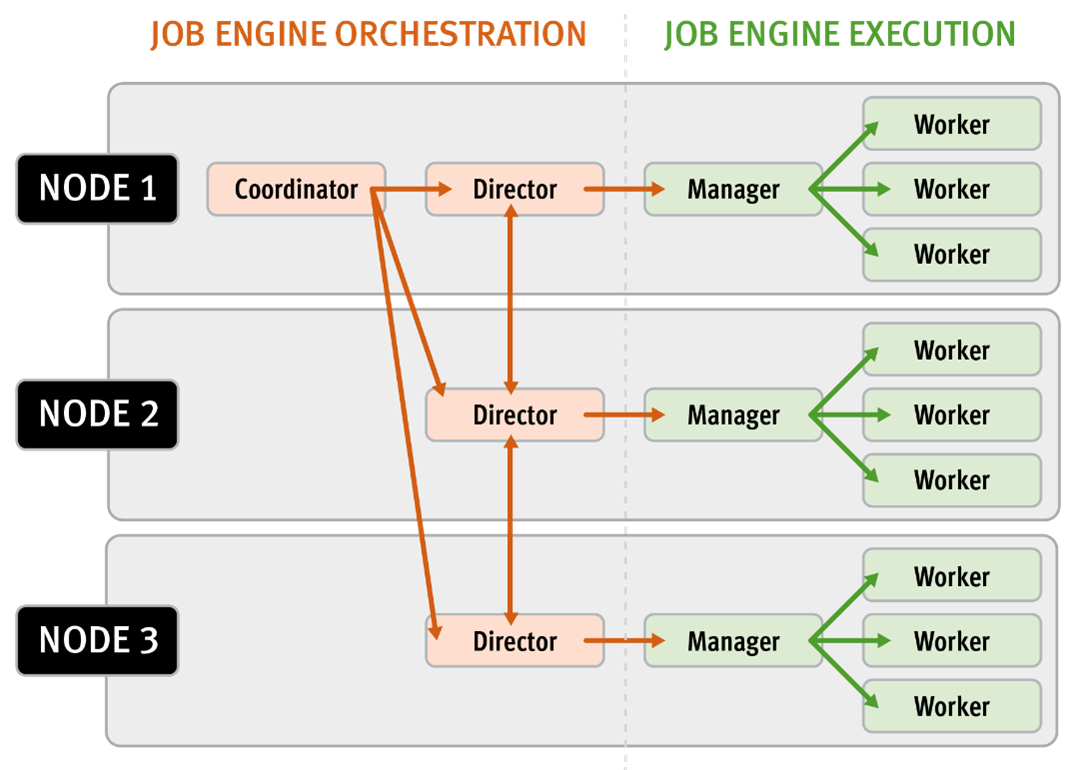
The coordinator is also responsible for starting and stopping jobs, and for processing work results as they are returned during job processing. Should it die for any reason, the coordinator responsibility automatically moves to another node.
Each node in the cluster has a Job Engine director process, which runs continuously and independently in the background. The director process is responsible for monitoring, governing, and overseeing all Job Engine activity on a particular node, constantly waiting for instruction from the coordinator to start a new job. The director process serves as a central point of contact for all the manager processes running on a node and as a liaison with the coordinator process across nodes. These responsibilities include manager process creation, delegating to and requesting work from other peers, and communicating status.
As such, the manager process is responsible for arranging the flow of tasks and task results throughout the duration of a job. The various manager processes request and exchange work with each other and supervise the worker threads assigned to them. At any time, each node in a cluster can have up to three manager processes, one for each job currently running. These managers are responsible for overseeing the flow of tasks and task results.
Each manager controls and assigns work items to multiple worker threads working on items for the designated job. Under direction from the coordinator and director, a manager process maintains the appropriate number of active threads for a configured impact level, and for the node’s current activity level. Once a job has been completed, the manager processes associated with that job, across all the nodes, are terminated. New managers are automatically spawned when the next job begins.
The manager processes on each node regularly send updates to their respective node’s director, which, in turn, informs the coordinator process of the status of the various worker tasks.
Each worker thread is given a task, if available, which it processes item-by-item until the task is complete or the manager unassigns the task. You can query the status of the nodes’ workers by running the CLI command isi job statistics view. In addition to the number of current worker threads per node, the query also provides a sleep-to-work (STW) ratio average, giving an indication of the worker thread activity level on the node.
Towards the end of a job phase, the number of active threads decreases as workers finish their allotted work and become idle. Nodes that have completed their work items remain idle, waiting for the last remaining node to finish its work allocation. When all tasks are done, the job phase is considered to be complete, and the worker threads are terminated.
As jobs are processed, the coordinator consolidates the task status from the constituent nodes and periodically writes the results to checkpoint files. These checkpoint files allow jobs to be paused and resumed, either proactively or in the event of a cluster outage. For example, if the node on which the Job Engine coordinator is running goes offline for any reason, a new coordinator automatically starts on another node. This new coordinator reads the last consistency checkpoint file, job control and task processing resume across the cluster, and no work is lost.
Each Job Engine job has an associated impact policy, dictating when a job runs and the resources that a job can consume. The default Job Engine impact policies are as follows:
| Impact policy | Schedule | Impact level |
| LOW | Any time of day | Low |
| MEDIUM | Any time of day | Medium |
| HIGH | Any time of day | High |
| OFF_HOURS | Outside of business hours (9 a.m. to 5 p.m., Monday to Friday), paused during business hours | Low |
While these default impact policies cannot be modified or deleted, additional custom impact policies can be manually created as needed.
A mix of jobs with different impact levels results in resource sharing. Each job cannot exceed the impact level set for it, and the aggregate impact level cannot exceed the highest level of the individual jobs.
In addition to the impact level, each Job Engine job also has a priority. These are based on a scale of one to ten, with a lower value signifying a higher priority. This is similar in concept to the UNIX ‘nice’ scheduling utility.
Higher-priority jobs cause lower-priority jobs to be paused. If a job is paused, it is returned to the back of the Job Engine priority queue. When the job reaches the front of the priority queue again, it resumes from where it left off. If the system schedules two jobs of the same type and priority level to run simultaneously, the job that was queued first runs first.
Priority takes effect when two or more queued jobs belong to the same exclusion set, or when, if exclusion sets are not a factor, four or more jobs are queued. The fourth queued job may be paused if it has a lower priority than the three other running jobs.
In contrast to priority, job impact policy only comes into play once a job is running and determines the resources a job can use across the cluster.
The FlexProtect, FlexProtectLIN, and IntegrityScan jobs have the highest Job Engine priority level of 1, by default. Of these, the FlexProtect jobs, having the core role of reprotecting data, are the most important.
All Job Engine job priorities are configurable by the cluster administrator. The default priority settings are strongly recommended, particularly for the highest-priority jobs.
The default impact policy and relative priority settings for the range of Job Engine jobs are as follows. Typically, the elevated impact jobs are also run at an increased priority. Note that the recommendation is to keep the default impact and priority settings, where possible, unless there is a compelling reason to change them.
| Job name | Impact policy | Priority |
| AutoBalance | LOW | 4 |
| AutoBalanceLIN | LOW | 4 |
| AVScan | LOW | 6 |
| ChangelistCreate | LOW | 5 |
| Collect | LOW | 4 |
| ComplianceStoreDelete | LOW | 6 |
| Deduplication | LOW | 4 |
| DedupeAssessment | LOW | 6 |
| DomainMark | LOW | 5 |
| DomainTag | LOW | 6 |
| FilePolicy | LOW | 6 |
| FlexProtect | MEDIUM | 1 |
| FlexProtectLIN | MEDIUM | 1 |
| FSAnalyze | LOW | 6 |
| IndexUpdate | LOW | 5 |
| IntegrityScan | MEDIUM | 1 |
| MediaScan | LOW | 8 |
| MultiScan | LOW | 4 |
| PermissionRepair | LOW | 5 |
| QuotaScan | LOW | 6 |
| SetProtectPlus | LOW | 6 |
| ShadowStoreDelete | LOW | 2 |
| ShadowStoreProtect | LOW | 6 |
| ShadowStoreRepair | LOW | 6 |
| SmartPools | LOW | 6 |
| SmartPoolsTree | MEDIUM | 5 |
| SnapRevert | LOW | 5 |
| SnapshotDelete | MEDIUM | 2 |
| TreeDelete | MEDIUM | 4 |
| WormQueue | LOW | 6 |
The majority of Job Engine jobs are intended to run in the background with LOW impact. Notable exceptions are the FlexProtect jobs, which by default are set at MEDIUM impact. This allows FlexProtect to quickly and efficiently reprotect data without critically affecting other user activities.
In the next article in this series, we’ll delve into the architecture and operation of SmartThrottling.