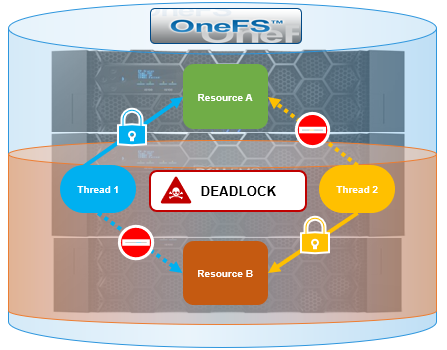
As we’ve seen previously in this series, very occasionally a cluster can become deadlocked and remain in an unstable state until the affected node(s), or sometimes the entire cluster, is rebooted or panicked. However, in addition to the data gathering discussed in the prior article, there are additional troubleshooting steps that can be explored by the more adventurous cluster admin – particularly with regard to investigating a LIN lock.
| Lock Domain | Resource | Description |
| LIN | LIN | Every object in the OneFS filesystem (file, directory, internal special LINs) is indexed by a logical inode number (LIN). A LIN provides an extra level of indirection, providing pointers to the mirrored copies of the on-disk inode. This domain is used to provide mutual exclusion around classic BSD vnode operations. Operations that require a stable view of data take a read lock which allows other readers to operate simultaneously but prevents modification. Operations that change data take a write lock that prevents others from accessing that directory while the change is taking place. |
The approach outlined can be useful to assist in identifying the problematic thread(s) and/or node(s) and helping to diagnose and resolve a cluster wide deadlock.
As a quick refresher, the various OneFS locking components include:
| Locking Component | Description |
| Coordinator | A coordinator node arbitrates locking within the cluster for a particular subset of resources. The coordinator only maintains the lock types held and wanted by the initiator nodes. |
| Domain | Refers to the specific lock attributes (recursion, deadlock detection, memory use limits, etc) and context for a particular lock application. There is one definition of owner, resource, and lock types, and only locks within a particular domain may conflict. |
| Initiator | The node requesting a lock on behalf of a thread is called an initiator. The initiator must contact the coordinator of a resource in order to acquire the lock. The initiator may grant a lock locally for types which are subordinate to the type held by the node. For example, with shared-exclusive locking, an initiator which holds an exclusive lock may grant either a shared or exclusive lock locally. |
| Lock Type | Determines the contention among lockers. A shared or read lock does not contend with other types of shared or read locks, while an exclusive or write lock contends with all other types. Lock types include: Advisory, Anti-virus, Data, Delete, LIN, Mark, Oplocks, Quota, Share Mode, SMB byte-range, Snapshot, and Write. |
| Locker | Identifies the entity which acquires a lock. |
| Owner | A locker which has successfully acquired a particular lock. A locker may own multiple locks of the same or different type as a result of recursive locking. |
| Resource | Identifies a particular lock. Lock acquisition only contends on the same resource. The resource ID is typically a LIN to associate locks with files. |
| Waiter | Has requested a lock but has not yet been granted or acquired it. |
So the basic data that will be required for a LIN lock investigation is as follows:
| Data | Description |
| <Waiter-LNN> | Node number with the largest ‘started’ value. |
| <Waiting-Address> | Address of <Waiter-LNN> node above. |
| <LIN> | LIN from the ‘resource =’ field of <Waiter-LNN> |
| <Block-Address> | Block address from “resource=’ field of <Waiter-LNN> |
| <Locker-Node> | Node that owns the lock for the <LIN>. Has a non-zero value for ‘owner_count‘. |
| <Locker-Address) | Address of Locker-Node. |
As such, the following process can be used to help investigate a LIN lock:
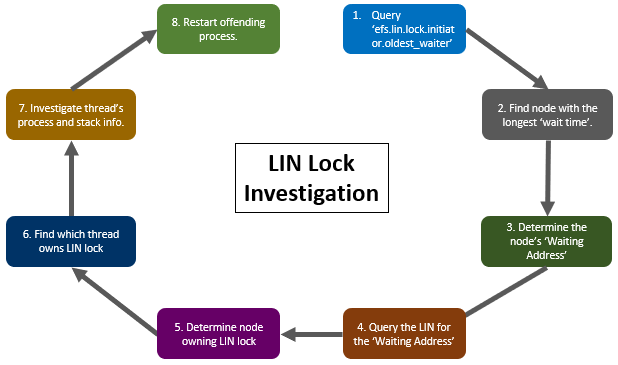
The details for each step above are as follows:
- First, execute the following CLI syntax from any node in the cluster to view the LIN lock.’oldest_waiter’ infol:
# isi_for_array -X 'sysctl efs.lin.lock.initiator.oldest_waiter | grep -E "address|started"' | grep -v "exited with status 1"
Querying the ‘efs.lin.lock.initiator.oldest_waiter’ sysctl returns a deluge of information, for example:
# sysctl efs.lin.lock.initiator.oldest_waiter
efs.lin.lock.initiator.oldest_waiter: resource = 1:02ab:002c
waiter = {
address = 0xfffffe8ff7674080
locker = 0xfffffe99a52b4000
type = shared
range = [all]
wait_type = wait ok
refcount_type = stacking
probe_id = 818112902
waiter_id = 818112902
probe_state = done
started = 773086.923126 (29.933031 seconds ago)
queue_in = 0xfffff80502ff0f08
lk_completion_callback = kernel:lk_lock_callback+0
waiter_type = sync
created by:
Stack: --------------------------------------------------
kernel:lin_lock_get_locker+0xfe
kernel:lin_lock_get_locker+0xfe
kernel:bam_vget_stream_invalid+0xe5
kernel:bam_vget_stream_valid_pref_hint+0x51
kernel:bam_vget_valid+0x21
kernel:bam_event_oprestart+0x7ef
kernel:ifs_opwait+0x12c
kernel:amd64_syscall+0x3a6
--------------------------------------------------
The pertinent areas of interest for this exercise are the ‘address’ and ‘started’ (wait time) fields.
If the ‘started’ value is short (ie. less than 90 seconds), or there is no output returned, then this is potentially an MDS lock issue (which can be investigated via the ‘efs.mds.block_lock.initiator.oldest_waiter’ sysctl).
- From the above output, examine the results with ‘started’ lines and find the one with the largest value for ‘(###.### seconds ago)’. The node number (<Waiter-LNN>) of this entry is the one of interest.
- Next, examine the ‘address =’ entries and find the one with that same node number (<Waiting-Address>).
Note that if there are multiple entries per node, this could indicate a multiple shared lock with another exclusive lock waiting.
- Query the LIN for the waiting address on the correct node using the following CLI syntax:
# isi_for_array -n<Waiter-LNN> 'sysctl efs.lin.lock.initiator.active_entries | egrep "resource|address|owner_count" | grep -B5 <Waiting-Address>'
- The LIN for this issue is shown in the ‘resource =’ field from the above output. Use the following command to find which node owns the lock on that LIN:
# isi_for_array -X 'sysctl efs.lin.lock.initiator.active_entries |egrep "resource|owner_count"' | grep -A1 <LIN>
Parse the output from this command to find the entry that has a non-zero value for ‘owner_count’. This is the node that owns the lock for this LIN (<Locker-Node>).
- Run the following command to find which thread owns the lock on the LIN:
# isi_for_array -n<Locker-Node> 'sysctl efs.lin.lock.initiator.active_entries | grep -A10 <LIN>'
- The ‘locker =’ field will provide the thread address (<Locker-Addr>) for the thread holding the lock on the LIN. The following CLI syntax can be used to find the associated process and stack details for this thread:
# isi_for_array -n<Locker-Node>'sysctl kern.proc.all_stacks |grep -B1 -A20 <Locker-Addr>'
- The output will provide the stack and process details. Depending on the process and stack information available from the previous command output, you may be able to terminate (ie. kill -9) the offending process in order to clear the deadlock issue.
Usually within a couple of minutes of killing the offending process, the cluster will become responsive again. The ‘isi get -L’ CLI command can be used to help determine which file was causing the issue, possibly giving some insight as to the root cause.
Please note that if you are unable to identify an individual culprit process, or are unsure of your findings, contact Dell Support for assistance.