In this article, we’ll take a look at one of the quieter but genuinely useful serviceability enhancements that arrives with the OneFS 9.14 release: REST API access for creating and updating syslog rules. Delivered under capability 5512, this feature brings the cluster’s logging configuration into the same programmatic, automation-friendly world that storage admins increasingly expect from the rest of the platform
Before digging into what’s new, it’s worth a brief recap of what syslog actually does. Syslog is the ubiquitous standard that devices and applications use to ship event logs to a central location. On a PowerScale node, the syslog daemon receives log messages from the operating system and its various services through its sockets, and then routes each message to the appropriate destination: a local log file, or a remote log server.
Those routing decisions are governed by rules. Each message is tagged with a facility – the subsystem it originated from, such as auth, mail, kern, or daemon – and a severity level, running from debug all the way up to emergency. A syslog rule is essentially a filter-plus-destination pairing: messages from a given facility, at a given severity or above, are sent to a particular destination. On OneFS, as on most BSD-derived systems, these rules live in the /etc/syslog.conf file, which the daemon reads and evaluates at runtime.
Centralized, well-routed logging matters for more than just day-to-day troubleshooting. It underpins security monitoring, forensic investigation, and the audit trails that many compliance regimes mandate – which is precisely why reliably forwarding the right messages to the right collector is something operations teams care about getting right. It’s a simple, battle-tested model; the friction has always been in how you manage it.
Historically, configuring syslog rules on a cluster involved editing system files directly. To add a rule that forwarded authentication events to a security information and event management (SIEM) collector, for example, you’d open syslog.conf, hand-craft the appropriate selector and action lines, save the file, and validate the result manually. That approach works, but it carries a familiar set of problems:
- Error-prone – hand-editing configuration files is exactly the kind of task where a stray tab, a typo in a facility name, or a malformed destination quietly breaks logging, often in ways you don’t notice until you go looking for logs that were never written.
- Operational overhead – every change is a manual, repeated sequence of steps, and every cluster has to be touched individually.
- Inconsistent setups – without a programmatic source of truth, it’s hard to guarantee that twenty clusters share the same logging policy, and configuration drift inevitably creeps in.
- Poor automation support – manual file edits don’t slot neatly into the Infrastructure-as-Code and DevOps pipelines that modern operations teams build everything else around.
For a single cluster managed by one administrator, none of this is fatal. At scale, it becomes a genuine source of toil and risk.
OneFS 9.14 addresses this by exposing syslog configuration through the OneFS Platform API (PAPI). Rather than editing files, you now create, update, and delete syslog rules – including rules that forward to remote servers – through a documented, versioned REST interface. The benefits are exactly what you’d expect from moving any configuration surface from files to an API:
- Programmatic configuration that can be scripted and version-controlled.
- Seamless integration into existing automation workflows, whether that’s a provisioning script, a configuration-management tool, or a CI/CD pipeline.
- Consistency and repeatability, so the same policy can be applied identically across every cluster in the estate.
- Easier maintenance, because the API enforces structure rather than relying on free-form text.
Under the covers, the flow is straightforward. A client (i.e. a script, automation tool, or a simple curl one-liner) issues a request to the PAPI endpoint.
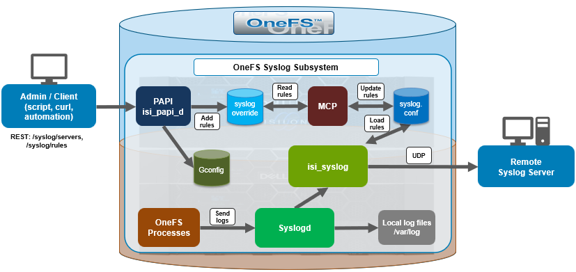
The platform API daemon, isi_papi_d, validates the request and translates it into the corresponding change in the syslog configuration. OneFS’s Master Control Program (MCP) is then responsible for propagating that configuration consistently across the nodes of the cluster, and the syslog daemon, isi_syslogd, picks up the updated rules and begins routing messages accordingly.
The key thing to note is that the API operates on the canonical configuration. There’s no risk of the API view and the on-disk configuration diverging, because the API is the thing writing the configuration. And because MCP handles distribution, a rule you create once is applied cluster-wide rather than node-by-node – which is precisely the consistency guarantee that hand-editing files on individual nodes could never offer.
The syslog auto rule functionality introduces two new endpoint groups. The first, /syslog/servers, manages the definition of remote syslog destinations, while the second, /syslog/rules, manages the rules themselves:
GET /platform/<ver>/syslog/servers # list configured remote servers POST /platform/<ver>/syslog/servers # define a new remote server DELETE /platform/<ver>/syslog/servers/<id> # remove a remote server GET /platform/<ver>/syslog/rules # list API-created rules POST /platform/<ver>/syslog/rules # create a new rule DELETE /platform/<ver>/syslog/rules/<id> # remove a rule
The division of responsibility is clean: The remote collectors are registered once via /syslog/servers, and then referenced when creating forwarding rules via /syslog/rules. A rule can forward matching messages to one of two kinds of destination – a local log file (restricted, sensibly, to the /var/log directory), or a remote syslog server that has been previously defined through the servers endpoint.
That /var/log restriction is worth calling out. By constraining local destinations to /var/log, OneFS avoids a whole class of problems in which a misconfigured rule could write log data into arbitrary – and potentially sensitive or space-constrained – areas of the filesystem. It’s a small guardrail, but a sensible one.
A typical sequence to forward authentication logs to a central collector breaks down into two steps. First, the remote server is registered through /syslog/servers, giving OneFS the address – and, depending on your environment, the transport and port – of the collector you want to ship logs to. Then, create a rule through /syslog/rules that selects the facility and severity you care about (authentication messages at, say, informational level and above) and points them at the server you just registered.
Removing the configuration later is the mirror image: delete the rule, then delete the server definition once nothing else references it. Listing is a simple GET against either endpoint, which makes the API equally valuable for auditing – you can ask a cluster what syslog rules it actually has, programmatically, rather than parsing a configuration file and hoping you read it correctly.
Because every one of these operations is a REST call, the whole sequence can be wrapped in a script and applied uniformly across as many clusters as you like. That is the entire point of the capability: the same logging policy, defined once, applied everywhere, with no text editors and no drift.
When investigating or troubleshooting syslog issues, there are a handful of places to look. To confirm that the syslog daemon itself is healthy, first check its service status:
# isi service isi_syslogd status
If an API call isn’t producing the configuration you expect, the platform API daemon’s log is the first stop, since that’s where request handling and validation are recorded:
# less /var/log/isi_papi_d.log
And because MCP is responsible for distributing the configuration across the cluster, its logs are the place to look if a change appears to have been accepted but has not been applied consistently:
# less /var/log/isi_mcp
Between the three – the daemon’s health, the API request log, and the MCP distribution log – you can usually pinpoint whether an issue lies in the request, in its propagation, or in the service itself.
In summary, the automated syslog rule configuration capability in OneFS 9.14 is a modest-sounding change with an outsized practical impact for anyone running PowerScale at scale. By exposing syslog server and rule management through the Platform API, OneFS turns what used to be a manual, error-prone, file-editing chore into a clean, scriptable, repeatable operation. Remote forwarding to a SIEM or central log server becomes a couple of API calls; auditing a cluster’s logging policy becomes a single GET; and rolling the same configuration out across an entire fleet becomes a loop in a script. So, for organizations standardizing on Infrastructure-as-Code, it removes one more manual island from the management plane. Plus, for everyone else, it simply makes a tricky task quicker, safer, and more easily and accurately repeatable.