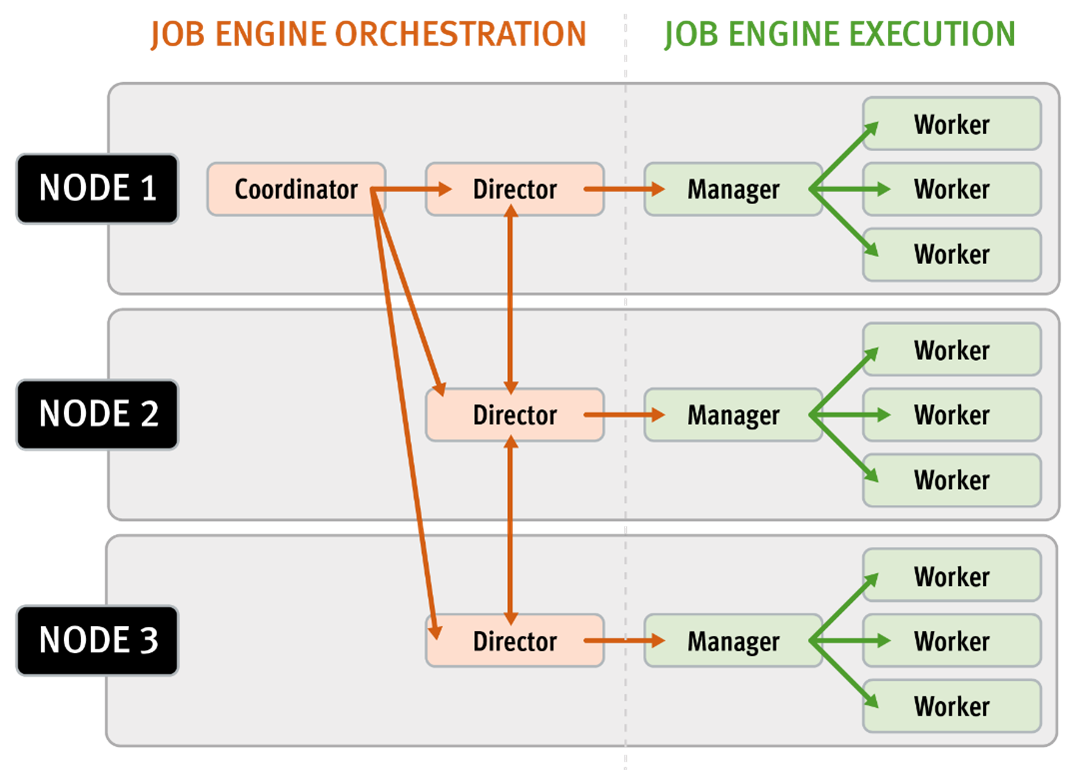
The Job Engine resource monitoring and execution framework allows jobs to be throttled based on both CPU and disk I/O metrics. The granularity of the resource utilization monitoring data provides the coordinator process with visibility into exactly what is generating IOPS on any particular drive across the cluster. This level of insight allows the coordinator to make very precise determinations about exactly where and how impact control is best applied. As we will see, the coordinator itself does not communicate directly with the worker threads, but rather with the director process, which in turn instructs a node’s manager process for a particular job to cut back threads.
For example, if the job engine is running a low-impact job and CPU utilization drops below the threshold, the worker thread count is gradually increased up to the maximum defined by the ‘low’ impact policy threshold. If client load on the cluster suddenly spikes for some reason, then the number of worker threads is gracefully decreased. The same principal applies to disk I/O, where the job engine will throttle back in relation to both IOPS as well as the number of I/O operations waiting to be processed in any drive’s queue. Once client load has decreased again, the number of worker threads is correspondingly increased to the maximum ‘low’ impact threshold.
In summary, detailed resource utilization telemetry allows the job engine to automatically tune its resource consumption to the desired impact level and customer workflow activity.
Certain jobs, if left unchecked, could consume vast quantities of a cluster’s resources, contending with and impacting client I/O. To counteract this, the Job Engine employs a comprehensive work throttling mechanism which is able to limit the rate at which individual jobs can run. Throttling is employed at a per-manager process level, so job impact can be managed both granularly and gracefully.
Every twenty seconds, the coordinator process gathers cluster CPU and individual disk I/O load data from all the nodes across the cluster. The coordinator uses this information, in combination with the job impact configuration, to decide how many threads may run on each cluster node to service each running job. This can be a fractional number, and fractional thread counts are achieved by having a thread sleep for a given percentage of each second.
Using this CPU and disk I/O load data, every sixty seconds the coordinator evaluates how busy the various nodes are and makes a job throttling decision, instructing the various job engine processes as to the action they need to take. This enables throttling to be sensitive to workloads in which CPU and disk I/O load metrics yield different results. Additionally, there are separate load thresholds tailored to the different classes of drives utilized in OneFS powered clusters, including high speed SAS drives, lower performance SATA disks and flash-based solid-state drives (SSDs).
The Job engine allocates a specific number of threads to each node by default, thereby controlling the impact of a workload on the cluster. If little client activity is occurring, more worker threads are spun up to allow more work, up to a predefined worker limit. For example, the worker limit for a low-impact job might allow one or two threads per node to be allocated, a medium-impact job from four to six threads, and a high-impact job a dozen or more. When this worker limit is reached (or before, if client load triggers impact management thresholds first), worker threads are throttled back or terminated.
For example, a node has four active threads, and the coordinator instructs it to cut back to three. The fourth thread is allowed to finish the individual work item it is currently processing, but then quietly exit, even though the task as a whole might not be finished. A restart checkpoint is taken for the exiting worker thread’s remaining work, and this task is returned to a pool of tasks requiring completion. This unassigned task is then allocated to the next worker thread that requests a work assignment, and processing continues from the restart check-point. This same mechanism applies in the event that multiple jobs are running simultaneously on a cluster.
Not all OneFS Job Engine jobs run equally fast. For example, a job which is based on a file system tree walk will run slower on a cluster with a very large number of small files than on a cluster with a low number of large files. Jobs which compare data across nodes, such as Dedupe, will run more slowly where there are many more comparisons to be made. Many factors play into this, and true linear scaling is not always possible. If a job is running slowly the first step is to discover what the specific context of the job is.
There are four main methods for jobs, and their associated processes, to interact with the file system:
| Method | Description |
| LIN Scan | Via metadata, using a LIN scan. An example of this is the IntegrityScan restriping job, when performing an on-line file system verification. |
| Tree Walk | Traversing the directory structure directly via a tree walk. For example, the SmartPoolsTree restriping job, when enacting file pool policies on a filesystem subtree. |
| Drive Scan | Directly accessing the underlying cylinder groups and disk blocks, via a linear drive scan. For example, the MediaScan restriping job, when looking for bad disk sectors. |
| Changelist | For example, the FilePolicy restriping job, which, in conjunction with IndexUpdate, runs an efficient SmartPools file pool policy job. |
Each of these approaches has its fortes and drawbacks and will suit particular jobs. The specific access method influences the run time of a job. For instance, some jobs are unaffected by cluster size, others slow down or accelerate with the more nodes a cluster has, and some are highly influenced by file counts and directory depths.
For a number of jobs, particularly the LIN-based ones, the job engine will provide an estimated percentage completion of the job during runtime (see figure 20 below).
With LIN scans, even though the metadata is of variable size, the job engine can fairly accurately predict how much effort will be required to scan all LINs. The data, however, can be of widely-variable size, and so estimates of how long it will take to process each task will be a best reasonable guess.
For example, the job engine might know that the highest LIN is 1:0009:0000. Assuming the job will start with a single thread on each of three nodes, the coordinator evenly divides the LINs into nine ranges: 1:0000:0000-1:0000:ffff, 1:0001:0000-1:0001:ffff, etc., through 1:0008:0000-1:0009:0000. These nine tasks would then be divided between the three nodes. However, there is no guaranty that each range will take the same time to process. For example, the first range may have fewer actual LINs, as a result of old LINs having been deleted, so complete unexpectedly fast. Perhaps the third range contains a disproportional number of large files and so takes longer to process. And maybe the seventh range has heavy contention with client activity, also resulting in an increased execution time. Despite such variances, the splitting and redistribution of tasks across the node manager processes alleviates this issue, mitigating the need for perfectly-fair divisions at the onset.
Priorities play a large role in job initiation and it is possible for a high priority job to significantly impact the running of other jobs. This is by design, since FlexProtect should be able to run with a greater level of urgency than SmartPools, for example. However, sometimes this can be an inconvenience, which is why the storage administrator has the ability to manually control the impact level and relative priority of jobs.
Certain jobs like FlexProtect have a corresponding job provided with a name suffixed by ‘Lin’, for example FlexProtectLin. This indicates that the job will automatically, where available, use an SSD-based copy of metadata to scan the LIN tree, rather than the drives themselves. Depending on the workflow, this will often significantly improve job runtime performance.
In situations where the job engine sees the available capacity on one or more disk pools fall below a low space threshold, it engages low space mode. This enables space-saving jobs to run and reclaim space before the job engine or even the cluster become unusable. When the job engine is in low-space mode new jobs will not be started, and any jobs that are not space-saving will be paused. Once free space returns above the low-space threshold, jobs that have been paused for space are resumed.
The space-saving jobs are:
- AutoBalance(LIN)
- Collect
- MultiScan
- ShadowStoreDelete
- SnapshotDelete
- TreeDelete
Once the cluster is no longer space constrained, any paused jobs are automatically resumed.
Until OneFS 9.7, the Job Engine had two clearly defined ‘exclusion sets’ for classes of jobs that could potentially cause performance or data integrity issues if run together. These exclusion sets help ensure that job phases with overlapping exclusion sets do not run and the same time, and the lowest priority job will be waiting.
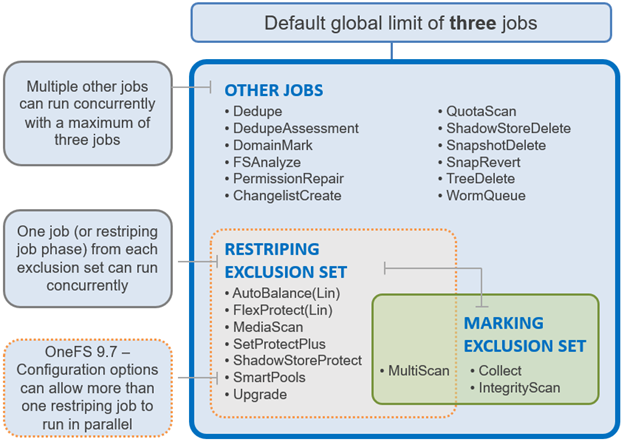
The first of these is the Marking exclusion set, which includes Collect and Integrity Scan which is strictly enforced since OneFS can only permit a single mark job without running the risk of corruption.
The other is the Restripe exclusion set, and the focus of this Job Engine enhancement. The restripe set are the jobs that move /ifs data blocks around for repair, balance, tiering, etc, in a process known as ‘restriping’ in the OneFS vernacular. These jobs include FlexProtect, MediaScan, AutoBalance, and SmartPools plus its sidekick, FilePolicy. Restriping typically has three specific goals:
| Goal | Description |
| Repair | Ensures that files have the proper protection after the loss of a storage device. |
| Reprotect | Moves files and reprotects them based on their file pool policy, while repairing at the same time, if needed. |
| Rebalance | Ensures the correct placement of a files’ blocks to balance the drives based on the file’s policy and protection settings. |
The fundamental responsibility of the jobs within the Restripe exclusion set is to ensure that the data on /ifs is protected at the desired level, balanced across nodes, and properly accounted for. It does this by running various file system maintenance jobs either manually, via a predefined schedule, or based on a cluster event, like a group change. These jobs include:
Multiscan
The MultiScan job, which combines the functionality of AutoBalance and Collect, is automatically run after a group change which adds a device to the cluster. AutoBalance(Lin) and/or Collect are only run manually if MultiScan has been disabled.
In addition to group change notifications, MultiScan is also started when:
- Data is unbalanced within one or more disk pools, which triggers MultiScan to start the AutoBalance phase only.
- When drives have been unavailable for long enough to warrant a Collect job, which triggers MultiScan to start both its AutoBalance and Collect phases.
AutoBalance
The goal of the AutoBalance job is to ensure that each node has the same amount of data on it, in order to balance data evenly across the cluster. AutoBalance, along with the Collect job, is run after any cluster group change, unless there are any storage nodes in a “down” state.
Upon visiting each file, AutoBalance performs the following two operations:
- File level rebalancing
- Full array rebalancing
For file level rebalancing, AutoBalance evenly spreads data across the cluster’s nodes in order to achieve balance within a particular file. And with full array rebalancing, AutoBalance moves data between nodes to achieve an overall cluster balance within a 5% delta across nodes.
There is also an AutoBalanceLin job available, which can be run in place of by AutoBalance when the cluster has a metadata copy available on SSD, providing an expedited job runtime. The following CLI syntax will enable the AutoBalanceLin job:
# isi_gconfig -t job-config jobs.common.lin_based_jobs=True
Collect
The Collect job is responsible for locating unused inodes and data blocks across the file system. Collect runs by default after a cluster group change, in conjunction with AutoBalance, as part of the MultiScan job.
In its first phase, Collect performs a marking job, scanning all the inodes (LINs) and identifying their associated blocks. Collect marks all the blocks which are currently allocated and in use, and any unmarked blocks are identified as candidates to be freed for reuse, so that the disk space they occupy can be reclaimed and re-allocated. All metadata must be read in this phase in order to mark every reference, and must be done completely, to avoid sweeping in-use blocks and introducing allocation corruption.
Collect’s second phase scans all the cluster’s drives and performs the freeing up, or sweeping, of any unmarked blocks so that they can be reused.
MediaScan
MediaScan’s role within the file system protection framework is to periodically check for and resolve drive bit errors across the cluster. This proactive data integrity approach helps guard against a phenomenon known as ‘bit rot’, and the resulting specter of hardware induced silent data corruption.
MediaScan is run as a low-impact, low-priority background process, based on a predefined schedule (monthly, by default).
First, MediaScan’s search and repair phase checks the disk sectors across all the drives in a cluster and, where necessary, utilizes OneFS’ dynamic sector repair (DSR) process to resolve any ECC sector errors that it encounters. For any ECC errors which can’t immediately be repaired, MediaScan will first try to read the disk sector again several times in the hopes that the issue is transient, and the drive can recover. Failing that, MediaScan will attempt to restripe files away from irreparable ECCs. Finally, the MediaScan summary phase generates a report of the ECC errors found and corrected.
IntegrityScan
The IntegrityScan job is responsible for examining the entire live file system for inconsistencies. It does this by systematically reading every block and verifying its associated checksum. Unlike traditional ‘fsck’ style file system integrity checking tools, IntegrityScan is designed to run while the cluster is fully operational, thereby removing the need for any downtime. In the event that IntegrityScan detects a checksum mismatch, it generates and alert, logs the error to the IDI logs and provides a full report upon job completion.
IntegrityScan is typically run manually if the integrity of the file system is ever in doubt. Although the job itself may take several days or more to complete, the file system is online and completely available during this time. Additionally, like all phases of the OneFS job engine, IntegrityScan can be prioritized, paused or stopped, depending on the impact to cluster operations.
FlexProtect
The FlexProtect job is responsible for maintaining the appropriate protection level of data across the cluster. For example, it ensures that a file which is configured to be protected at +2n, is actually protected at that level. Given this, FlexProtect is arguably the most critical of the OneFS maintenance jobs because it represents the Mean-Time-To-Repair (MTTR) of the cluster, which has an exponential impact on MTTDL. Any failures or delay has a direct impact on the reliability of the OneFS file system.
In addition to FlexProtect, there is also a FlexProtectLin job. FlexProtectLin is run by default when there is a copy of file system metadata available on solid state drive (SSD) storage. FlexProtectLin typically offers significant runtime improvements over its conventional disk based counterpart.
As such, the primary purpose of FlexProtect is to repair nodes and drives which need to be removed from the cluster. In the case of a cluster group change, for example the addition or subtraction of a node or drive, OneFS automatically informs the job engine, which responds by starting a FlexProtect job. Any drives and/or nodes to be removed are marked with OneFS’ ‘restripe_from’ capability. The job engine coordinator notices that the group change includes a newly-smart-failed device and then initiates a FlexProtect job in response.
FlexProtect falls within the job engine’s restriping exclusion set and, similar to AutoBalance, comes in two flavors: FlexProtect and FlexProtectLin.
Run automatically after a drive or node removal or failure, FlexProtect locates any unprotected files on the cluster, and repairs them as rapidly as possible. The FlexProtect job runs by default with an impact level of ‘medium’ and a priority level of ‘1’, and includes six distinct job phases:
The regular version of FlexProtect has the following phases:
| Job Phase | Description |
| Drive Scan | Job engine scans the disks for inodes needing repair. If an inode needs repair, the job engine sets the LIN’s ‘needs repair’ flag for use in the next phase.
|
| LIN Verify | This phase scans the OneFS LIN tree to addresses the drive scan limitations. |
| LIN Re-verify | The prior repair phases can miss protection group and metatree transfers. FlexProtect may have already repaired the destination of a transfer, but not the source. If a LIN is being restriped when a metatree transfer, it is added to a persistent queue, and this phase processes that queue.
|
| Repair | LINs with the ‘needs repair’ flag set are passed to the restriper for repair. This phase needs to progress quickly and the job engine workers perform parallel execution across the cluster. |
| Check | This phase ensures that all LINs were repaired by the previous phases as expected. |
| Device Removal | The successfully repaired nodes and drives that were marked ‘restripe from’ at the beginning of phase 1 are removed from the cluster in this phase. Any additional nodes and drives which were subsequently failed remain in the cluster, with the expectation that a new FlexProtect job will handle them shortly. |
Be aware that prior to OneFS 8.2, FlexProtect is the only job allowed to run if a cluster is in degraded mode, such as when a drive has failed, for example. Other jobs will automatically be paused and will not resume until FlexProtect has completed and the cluster is healthy again. In OneFS 8.2 and later, FlexProtect does not pause when there is only one temporarily unavailable device in a disk pool, when a device is smartfailed, or for dead devices.
The FlexProtect job executes in userspace and generally repairs any components marked with the ‘restripe from’ bit as rapidly as possible. Within OneFS, a LIN Tree reference is placed inside the inode, a logical block. A B-Tree describes the mapping between a logical offset and the physical data blocks:
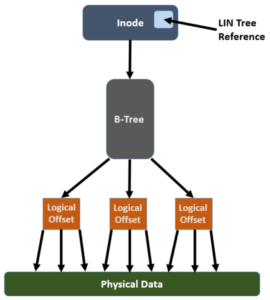
In order for FlexProtect to avoid the overhead of having to traverse the whole way from the LIN Tree reference -> LIN Tree -> B-Tree -> Logical Offset -> Data block, it leverages the OneFS construct known as the ‘Width Device List’ (WDL). The WDL enables FlexProtect to perform fast drive scanning of inodes because the inode contents are sufficient to determine need for restripe. The WDL keeps a list of the drives in use by a particular file, and are stored as an attribute within an inode and are thus protected by mirroring. There are two WDL attributes in OneFS, one for data and one for metadata. The WDL is primarily used by FlexProtect to determine whether an inode references a degraded node or drive. It New or replaced drives are automatically added to the WDL as part of new allocations.
As mentioned previously, the FlexProtect job has two distinct variants. In the FlexProtectLin version of the job the Disk Scan and LIN Verify phases are redundant and therefore removed, while keeping the other phases identical. FlexProtectLin is preferred when at least one metadata mirror is stored on SSD, providing substantial job performance benefits.
In addition to automatic job execution after a drive or node removal or failure, FlexProtect can also be initiated on demand. The following CLI syntax will kick of a manual job run:
# isi job start flexprotect Started job [274] # isi job list ID Type State Impact Pri Phase Running Time ---------------------------------------------------------- 274 FlexProtect Running Medium 1 1/6 4s ---------------------------------------------------------- Total: 1
The FlexProtect job’s progress can be tracked via a CLI command as follows:
# isi job jobs view 274
ID: 274
Type: FlexProtect
State: Succeeded
Impact: Medium
Policy: MEDIUM
Pri: 1
Phase: 6/6
Start Time: 2020-12-04T17:13:38
Running Time: 17s
Participants: 1, 2, 3
Progress: No work needed
Waiting on job ID: -
Description: {"nodes": "{}", "drives": "{}"}
Upon completion, the FlexProtect job report, detailing all six stages, can be viewed by using the following CLI command with the job ID as the argument:
# isi job reports view <job_id>