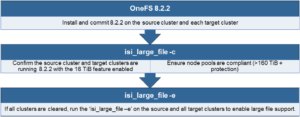
OneFS includes a number of security features to reduce risk and provide tighter access control. Among them is support for Multi-factor Authentication, or MFA. At its essence, MFA works by verifying the identity of all users with additional mechanisms, or factors – such as phone, USB device, fingerprint, retina scan, etc – before granting access to enterprise applications and systems. This helps corporations to protect against phishing and other access-related threats.
The SSH protocol in OneFS incorporates native support for the external Cisco Duo service for unified access and security to improve trust in the users and the storage resources accessed. The SSH protocol is configured using the CLI and now can be used to store public keys in LDAP rather than stored in the user’s home directory. A key advantage to this architecture is the simplicity in setup and configuration which reduces the chance of misconfiguration. The Duo service that provides MFA access can be used in conjunction with password and/or keys to provide additional security. The Duo service delivers maximum flexibility by including support for the Duo App, SMS, voice and USB keys. As a failback, specific users and groups in an exclusion list may be allowed to bypass MFA, if specified on the Duo server. It is also possible to generate one-time access to users to accommodate events like a forgotten phone or failback mode associated with the unavailability of the Duo service.
OneFS’ SSH protocol implementation:
- Supports Multi-Factor Authentication (MFA) with the Duo Service in conjunction with passwords and/or keys
- Is configurable via the OneFS CLI (No WebUI support yet)
- Can now use Public Keys stored in LDAP
Multi-factor Authentication helps to increase the security of their clusters and is a recommended best-practice for many public and private sector industry bodies, such as the MPAA.
OneFS 8.2 and later supports MFA with Duo, CLI configuration of SSH and support for storing public SSH keys in LDAP. A consistent configuration experience, heightened security and tighter access control for SSH is a priority for many customers.
The OneFS SSH authentication process is as follows:
| Step |
Action |
| 1 |
Administrator configures User Authentication Method. If configuring ‘publickey’, the correct settings are set for both SSH and PAM. |
| 2 |
If User Authentication Method is ‘publickey’ or ‘both’, user’s Private Key is provided at start of session. This is verified first against the Public Key from either their home directory on the cluster the LDAP Server. |
| 3 |
If Duo is enabled, the user’s name is sent to the Duo Service.
· If the Duo config has Autopush set to yes, a One Time Key is sent to the user on the set device.
· If the Duo config has Autopush set to no, the user chooses from a list of devices linked to their account and a One Time Key is sent to the user on that device.
· The user enters the key at the prompt, and the key is sent to Duo for verification. |
| 4 |
If User Authentication Method is ‘password’ or ‘both’, the SSH server requests the user’s password, which is sent to PAM and verified against the password file or LSASS. |
| 5 |
The user is checked for the appropriate RBAC SSH privilege |
| 6 |
If all of the above steps succeed, the user is SSH granted access. |
A new CLI command family is added to view and configure SSH, and defined authentication types help to eliminate misconfiguration issues. Any SSH config settings that are not exposed by the CLI can still be configured in the SSHD configuration template. In addition, Public Keys stored in LDAP may now also be used by SSH for authentication. There is no WebUI interface for SSH yet, but this will be added in a future release.
Many of the common SSH settings can now be configured and displayed via the OneFS CLI using ‘isi ssh settings modify’ and ‘isi ssh settings view’ commands respectively.
The authentication method is configured with the option ‘–user-auth-method’, which can be set to ‘password’, ‘publickey’, ‘both’ or ‘any’. For example:
# isi ssh settings modify -–login-grace-time=1m -–permit-root-login=no –-user-auth-method=both
# isi ssh settings view
Banner:
Ciphers: aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com,chacha20-poly1305@openssh.com
Host Key Algorithms: +ssh-dss,ssh-dss-cert-v01@openssh.com
Ignore Rhosts: Yes
Kex Algorithms: curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1
Login Grace Time: 1m
Log Level: INFO
Macs: hmac-sha1
Max Auth Tries: 6
Max Sessions: -
Max Startups:
Permit Empty Passwords: No
Permit Root Login: No
Port: 22
Print Motd: Yes
Pubkey Accepted Key Types: +ssh-dss,ssh-dss-cert-v01@openssh.com
Strict Modes: No
Subsystem: sftp /usr/local/libexec/sftp-server
Syslog Facility: AUTH
Tcp Keep Alive: No
Auth Settings Template: both
On upgrade to 8.2 or later, the cluster’s existing SSH Config will automatically be imported into gconfig. This includes settings both exposed and not exposed by the CLI. Any additional SSH settings that are not included in the CLI config options can still be manually set by adding them the /etc/mcp/templates/sshd.conf file. These settings will be automatically propagated to the /etc/ssh/sshd_config file by mcp and imported into gconfig.
To aid with auditing or troubleshooting SSH, the desired verbosity of logging can be configured with the option ‘–log-level’, which accepts the default values allowed by SSH.
The ‘–match’ option allows for one or more match settings block to be set, for example:
# isi ssh settings modify –-match=”Match group sftponly
dquote> X11Forwarding no
dquote> AllowTcpForwarding no
dquote> ChrootDirectory %h”
And to verify:
# less /etc/ssh/sshd_config
# X: ----------------
# X: This file automatically generated. To change common settings, use 'isi ssh'.
# X: To change settings not covered by 'isi ssh', please contact customer support.
# X: ----------------
AuthorizedKeysCommand /usr/libexec/isilon/isi_public_key_lookup
AuthorizedKeysCommandUser nobody
Ciphers aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.# X: ----------------
# X: This file automatically generated. To change common settings, use 'isi ssh'.
# X: To change settings not covered by 'isi ssh', please contact customer support.
# X: ----------------
AuthorizedKeysCommand /usr/libexec/isilon/isi_public_key_lookup
AuthorizedKeysCommandUser nobody
Ciphers aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.
com,chacha20-poly1305@openssh.com
HostKeyAlgorithms +ssh-dss,ssh-dss-cert-v01@openssh.com
IgnoreRhosts yes
KexAlgorithms curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1
LogLevel INFO
LoginGraceTime 120
MACs hmac-sha1
MaxAuthTries 6
MaxStartups 10:30:60
PasswordAuthentication yes
PermitEmptyPasswords no
PermitRootLogin yes
Port 22
PrintMotd yes
PubkeyAcceptedKeyTypes +ssh-dss,ssh-dss-cert-v01@openssh.com
StrictModes yes
Subsystem sftp /usr/local/libexec/sftp-server
SyslogFacility AUTH
UseDNS no
X11DisplayOffset 10
X11Forwarding no
Match group spftonly
X11Forwarding no
AllowTcpForwarding no
ForceCommand internal-sftp -u 0002
ChrootDirectory %h
Note that match blocks usually span multiple lines, and the ZSH shell will allow line returns and spaces until the double quotes (“) are closed.
When making SSH configuration changes, the SSH service will be restarted, but existing sessions will not be terminated. This allows for changes to be tested before ending the configuration session. Be sure to test any changes that could affect authentication before closing the current session.
A user’s public key may be viewed by adding ‘–show-ssh-key’ flag. Multiple keys may be specified in the LDAP configuration, and the key that corresponds to the private key presented in the SSH session will be used (unless there is no match of course). However, the user will still need a home directory on the cluster or they will get an error upon log-in.
OneFS can now be configured to use Cisco’s Duo MFA with SSH. Duo MFA supports the Duo App, SMS, Voice and USB Keys.
Be aware that the use of Duo requires an account with the Duo service. Duo will provide a host, ‘ikey’ and ‘skey’ to use for configuration, and the skey should be treated as a secure credential.
From the cluster side, multi-factor auth support with Duo is configured via the ‘isi auth duo’. For example, the following syntax will enable Duo support in safe mode with autopush disabled, set the ikey, and prompt interactively to configure the skey:
# isi auth duo modify -–autopush=false -–enabled=true -–failmode=safe -–host=api.9283eefe.duosecurity.com -–ikey=DIZIQCXV9HIVMKYZ8V4S -–set-skey
Enter skey:
Confirm:
Similarly, the following command will verify the cluster’s Duo config settings:
# isi auth duo view -v
Autopush: No
Enabled: Yes
Failmode: safe
Fallback Local IP: No
Groups:
HTTP Proxy:
HTTPS Timeout: 0
Prompts: 3
Pushinfo: No
Host: api.9283eefe.duosecurity.com
Ikey: DIZIQCXV9HIVMKYZ8V4S
Duo MFA rides on top of existing password and/or public key requirements and therefore cannot be configured if the SSH authentication type is set to ‘any’. Specific users or groups may be allowed to bypass MFA if specified on the Duo server, and Duo allows for the creation of one time or date/time limited bypass keys for a specific user.
Note that a bypass key will not work if ‘autopush’ is set to ‘true’, since no prompt option will be shown to the user. Be advised that Duo uses a simple name match and is not Active Directory-aware. For example, the AD user ‘DOMAIN\foo’ and the LDAP user ‘foo’ are the considered to be one and the same user by Duo.
Duo uses HTTPS for communication with the Duo server and there is an option to set a proxy to use if needed. Duo also has a failback mode specifying what to do if the Duo service is unavailable:
| Failback Mode |
Characteristics |
| Safe |
In safe mode SSH will allow normal authentication if Duo can not be reached. |
| Secure |
In secure mode SSH will fail if Duo can not be reached. This includes ‘bypass’ users, since the bypass state is determined by the Duo service. |
The Duo ‘autopush’ option controls whether a key will be automatically pushed or if a user can choose the method:
| Autopush Option |
Characteristics |
| Yes |
If set to yes, Duo will push the one-time key to the device associated with the user. |
| No |
If set to no, Duo will provide a list of methods to push the one-time key to. |
| Pushinfo |
The Pushinfo option allows a small message to be sent to the user along with the one-time key as part of the push notification. |
Duo may be disabled and re-enabled without re-entering the host, ikey and skey.
The ‘groups’ option groups may be used to specify one or more groups to be associated with the Duo Service and can be used to create an exclusion list. Three types of groups may be configured:
| Group Option |
Characteristics |
| Local |
Local groups using the local authentication provider. |
| Remote |
Remote authentication provider groups, such as LDAP. |
| Duo |
Duo Groups created and managed though the Duo Service. |
A Duo group can be used to both add users to the group and specify that its status is ‘Bypass’. This will allow users of this group to SSH in without MFA. Configuration is within Duo itself and the users must already be known to the Duo service. The Duo service must still be contacted to determine whether the user is in the bypass group or not.
Using a local or remote authentication provider group allows users without a Duo account to be added to the group. If a user is in a group that has been added to the Isilon Duo the user can SSH into the cluster without a Duo account. The created account can then be approved by an administrator at which time the user can SSH into the cluster.
It is also possible to create a local or remote provider group as an exclusion group by configuring it via the CLI with a ‘!’ before it. Any user in this group will not be prompted for a Duo key. Note that ZSH, OneFS’ default CLI shell, typically requires the ‘!’ character to be escaped.
This exclusion is checked by OneFS prior to contacting Duo. This is one method of creating users that can SSH into the cluster even when the Duo Service is not available and failback mode is set to secure. If using such an exclusion group, it should be preceded by an asterisk to ensure that all other groups do required the Duo One Time Key. For example:
# isi auth duo modify --groups=”*,\!duo_exclude”
# isi auth duo view -v
Autopush: No
Enabled: No
Failmode: safe
Fallback Local IP: No
Groups: *,!duo_exclude
HTTP Proxy:
HTTPS Timeout: 0
Prompts: 3
Pushinfo: No
Host: api-9283eefe.duosecurity.com
Ikey: DIZIQCXV9HIVMKYZ8V4S
The ‘groups’ option can also be used to specify users that are required to use Duo while users not in the group do not need to. For example: “–groups=<group>”.
The following output shows a multi-factor authenticated SSH session to a cluster running OneFS 8.2 using a passcode:
# ssh duo_user1@isilon.com
Duo two-factor login for duo_user1
Enter a passcode or select one of the following options:
-
Duo Push to iOS
-
Duo Push to XXX-XXX-4237
-
Phone call to XXX-XXX-4237
-
SMS passcodes to XXX-XXX-4237 (next code starts with: 1)
Passcode or option (1-4): 907949100
Success. Logging you in…
Password:
Copyright (c) 2001-2017 EMC Corporation. All Rights Reserved.
Copyright (c) 1992-2017 The FreeBSD Project.
Copyright (c) 1979, 1980. 1983, 1986, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
With 8.2 and later, Public SSH keys can eb used from LDAP rather than from a user’s home directory on the cluster. For example:
# isi auth users view –-user=ssh_user_1 –-show-ssh-keys
Name: ssh_user1_rsa
DN: cn-ssh_user1_rsa,ou=People,dc=tme-ldap1dc=isilon,dc=com
DNS Domain: -
Domain: LDAP_USERS
Provider: lsa-ldap-provider:tme-ldap1
Sam Account Name: ssh_user1_rsa
UID: 4567
SID: S-1-22-1-4567
Enabled: Yes
Expired: No
Expiry: -
Locked: No
Email: -
GECOS: The private SSH key for this user may be found at isilon/tst/ssh_tst_keys. The key type will match the end of the user name (rsa in this case)
Generated GID: No
Generated UID: No
Generated UPN: -
Primary Group
ID: GID:4567
Name: ssh_user1_rsa
Home Directory: /ifs/home/ssh_user1_rsa
Max Password Age: -
Password Expired: No
Password Expiry: -
Password Last Set: -
Password Expires: Yes
Shell: /usr/local/bin/zsh
UPN: -
User Can Change Password: No
SSH Public Keys: ssh-rsa AAAAB3Nza……………
The LDAP create and modify commands also now include the ‘–ssh-public-key-attribute’ option. The most common attribute for this is the sshPublicKey attribute from the ldapPublicKey objectClass.