OneFS cbind is the distributed DNS cache daemon for a PowerScale cluster. As such, its primary role is to accelerate domain name lookups on the cluster, particularly for NFS workloads, which can frequently involve a large number of lookups requests, especially when using netgroups. Cbind itself is logically separated into two halves:
| Component | Description |
| Gateway cache | The entries a node refreshes from the DNS server. |
| Local cache | The entries a node refreshes from the Gateway node. |
Cbind’s architecture helps to distribute the cache and associated DNS workload across all nodes in the cluster, and the daemon runs as a OneFS service under the purview of MCP and the /etc/mcp/sys/services/isi_cbind_d control script:
# isi services -a | grep i bind isi_cbind_d Bind Cache Daemon Enabled
On startup the cbind daemon, isi_cbind_d, reads its configuration from the cbind_config.gc gconfig file. If needed, configuration changes can be made using the ‘isi network dnscache’ or ‘isi_cbind’ CLI tools.
The cbind daemon also supports multi-tenancy across the cluster, with each tenant’s groupnet being allocated its own completely independent DNS cache, with multiple client interfaces to separate DNS requests from different groupnets. Cbind uses the 127.42.x.x address range and can be accessed by client applications across the entire range. The lower 16 bytes of the address are set by the client to the groupnet ID for the query. For example, if the client is trying to query the DNS servers on groupnet with ID 5 it will send the DNS query to 127.42.0.5.
Under the hood, the cbind daemon comprises two DNS query/response containers, or ‘stallsets’:
| Component | Description |
| DNS stallset | The DNS stallset is a collection of DNS stalls which encapsulate a single DNS server and a list of DNS queries which have been sent to the DNS servers and are waiting for a response. |
| Cluster stallset | The cluster stallset is similar to the DNS stallset, except the cluster stalls encapsulate the connection to another node in the cluster, known as the gateway node. It also holds a list of DNS queries which have been forwarded to the gateway node and are waiting for a response. |
Contained within a stallset are the stalls themselves, which store the actual DNS requests and responses. The DNS stallset provides a separate stall for each DNS server that cbind has been configured to use, and requests are handled via a round-robin algorithm. Similarly, for the cluster stallset, there is a stall for each node within the cluster. The index of the cluster stallset is the gateway node’s (devid – 1).
The cluster stallset entry for the node that is running the daemon is treated as a special case, known as ‘L1 mode’, because the gateway for these DNS requests is the node executing the code. Requests on the gateway stall also have an entry on the DNS stallset representing the request to the external DNS server. All other actively participating cluster stallset entries are referred to as ‘L2+L1’ mode. However, if a node cannot reach DNS, it is moved to L2 mode to prevent it from being used by the other nodes. An associated log entry is written to /var/log/isi_cbind_d.log, of the form:
isi_cbind_d[6204]: [0x800703800]bind: Error sending query to dns:10.21.25.11: Host is down
In order to support large clusters, cbind uses a consistent hash to determine the gateway node to cache a request and the appropriate cluster stallset to use. This consistent hashing algorithm, which decides on which node to cache an entry, is designed to minimize the number of entry transfers as nodes are added/removed, while also reducing the number of threads and UDP ports used. To illustrate cbind’s consistent hashing, consider the following three node cluster:
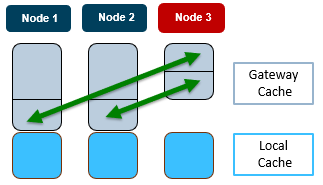
In this scenario, when the cbind service on Node 3 becomes active, one third each of the gateway cache from node 1 and 2 respectively gets transferred to node 3. Similarly, if node 3’s cbind service goes down, its gateway cache is divided equally between nodes 1 and 2. For a DNS request on node 3, the node first checks its local cache. If the entry is not found, it will automatically query the gateway (for example, node 2). This means that even if node 3 cannot talk to the DNS server directly, it can still cache the entries from a different node.
So, upon startup, a node’s cbind process attempts to contact, or ‘ping’, the DNS servers. Once a reply is received, the cbind moves into an up state and notifies GMP that the isi_cbind_d service is running on this node. GMP, in turn, then informs the cbind processes across the rest of the cluster that the node is up and available.
Conversely, after several DNS requests to an external server fail for a given node or the isi_cbind_d process is terminated, then the GMP code is notified that the isi_cbind_d service is down for this node. GMP then notifies the cluster that the node is down. When a cbind process (on node Y) receives this notification, the consistent hash algorithm is updated to report that node X is down. The cluster stallset is not informed of this change. Instead the DNS requests that have changed gateways will eventually timeout and be deleted.
As such, the cbind request and response processes can be summarized as follows:
- A client on the node sends a DNS query on the additional loopback address 127.42.x.x which is received by cbind.
- The cbind daemon uses the consistent hash algorithm to calculate the gateway value of the DNS query and uses the gateway to index the cluster stallset.
- If there is a cache hit, a response is sent to the client and the transaction is complete.
- Otherwise, the DNS query is placed in the cluster stallset using the gateway as the index. If this is the gateway node then the request is sent to the external DNS server, otherwise the DNS request is forwarded to the gateway node.
- When the DNS server or gateway replies, another thread receives the DNS response and matches it to the query on the list. The response is forwarded to the client and the cluster stallset is updated.
Similarly, when a request is forwarded to the gateway node:
- The cbind daemon receives the request, calculates the gateway value of the DNS query using the consistent hash algorithm, and uses the gateway to index the cluster stallset.
- If there is a cache hit, a response is returned to the remote cbind process and the transaction is complete.
- Otherwise, the DNS query is placed in the cluster stallset using the gateway as the index and the request is sent to the external DNS server.
- When the DNS server or gateway returns, another thread receives the DNS response and matches it to the query on the list. The response is forwarded to the calling node and the cluster stallset is updated.
If necessary, cbind DNS caching can be enabled or disabled via the ‘isi network groupnets’ command set, allowing the cache to be managed per groupnet:
# isi network groupnets modify --id=<groupnet-name> --dns-cache-enabled=<true/false>
The global ‘isi network dnscache’ command set can be useful for inspecting the cache configuration and limits:
# isi network dnscache view Cache Entry Limit: 65536 Cluster Timeout: 5 DNS Timeout: 5 Eager Refresh: 0 Testping Delta: 30 TTL Max Noerror: 3600 TTL Min Noerror: 30 TTL Max Nxdomain: 3600 TTL Min Nxdomain: 15 TTL Max Other: 60 TTL Min Other: 0 TTL Max Servfail: 3600 TTL Min Servfail: 300
The following table describes these DNS cache parameters, which can be manually configured if desired.
| Setting | Description |
| TTL No Error Minimum | Specifies the lower boundary on time-to-live for cache hits (default value=30s). |
| TTL No Error Maximum | Specifies the upper boundary on time-to-live for cache hits (default value=3600s). |
| TTL Non-existent Domain Minimum | Specifies the lower boundary on time-to-live for nxdomain (default value=15s). |
| TTL Non-existent Domain Maximum | Specifies the upper boundary on time-to-live for nxdomain (default value=3600s). |
| TTL Other Failures Minimum | Specifies the lower boundary on time-to-live for non-nxdomain failures (default value=0s). |
| TTL Other Failures Maximum | Specifies the upper boundary on time-to-live for non-nxdomain failures (default value=60s). |
| TTL Lower Limit For Server Failures | Specifies the lower boundary on time-to-live for DNS server failures(default value=300s). |
| TTL Upper Limit For Server Failures | Specifies the upper boundary on time-to-live for DNS server failures (default value=3600s). |
| Eager Refresh | Specifies the lead time to refresh cache entries that are nearing expiration (default value=0s). |
| Cache Entry Limit | Specifies the maximum number of entries that the DNS cache can contain (default value=35536 entries). |
| Test Ping Delta | Specifies the delta for checking the cbind cluster health (default value=30s). |
Also, if necessary, the cache can be globally flushed via the following CLI syntax:
# isi network dnscache flush -v Flush complete.
OneFS also provides the ‘isi_cbind’ CLI utility, which can be used to communicate with the cbind daemon. This utility supports both regular CLI syntax, plus an interactive mode where commands are prompted for. Interactive mode can be entered by invoking the utility without an argument, for example:
# isi_cbind cbind: cbind: quit #
The following command options are available:
# isi_cbind help clear - clear server statistics dump - dump internal server state exit - exit interactive mode flush - flush cache quit - exit interactive mode set - change volatile settings show - show server settings or statistics shutdown - orderly server shutdown
An individual groupnet’s cache can be flushed as follows, in this case targeting the ‘client1’ groupnet:
# isi_cbind flush groupnet client1 Flush complete.
Note that all the cache settings are global and, as such, will affect all groupnet DNS caches.
The cache statistics are available via the following CLI syntax, for example:
# isi_cbind show cache Cache: entries: 10 - entries installed in the cache max_entries: 338 - entries allocated, including for I/O and free list expired: 0 - entries that reached TTL and were removed from the cache probes: 508 - count of attempts to match an entry in the cache hits: 498 (98%) - count of times that a match was found updates: 0 - entries in the cache replaced with a new reply response_time: 0.000005 - average turnaround time for cache hits
These cache stats can be cleared as follows:
# isi_cbind clear cache
Similarly, the DNS statistics can be viewed with the ‘show dns’ argument:
# isi_cbind show dns DNS server 1: (dns:10.21.25.10) queries: 862 - queries sent to this DNS server responses: 862 (100%) - responses that matched a pending query spurious: 17315 (2008%) - responses that did not match a pending query dropped: 17315 (2008%) - responses not installed into the cache (error) timeouts: 0 ( 0%) - times no response was received in time response_time: 0.001917 - average turnaround time from request to reply DNS server 2: (dns:10.21.25.11) queries: 861 - queries sent to this DNS server responses: 860 ( 99%) - responses that matched a pending query spurious: 17314 (2010%) - responses that did not match a pending query dropped: 17314 (2010%) - responses not installed into the cache (error) timeouts: 1 ( 0%) - times no response was received in time response_time: 0.001603 - average turnaround time from request to reply
When running isi_cbind_d, the following additional options are available, and can be invoked with the following CLI flags and syntax:
| Option | Flag | Description |
| Debug | -d | Set debug flag(s) to log specific components. The flags are comma separated list from the following components:
all Log all components. cache Log information relating to cache data. cluster Log information relating to cluster data. flow Log information relating to flow data. lock Log information relating to lock data. link Log information relating to link data. memory Log information relating to memory data. network Log information relating to network data. refcount Log information relating to cache object refcount data. timing Log information relating to cache timing data. external Special debug option to provide off-node DNS service. |
| Output | -f | Isi_cbind will not detach from the controlling terminal and will print debugging messages to stderr. |
| Dump to | -D | Target file for isi_cbind dump output. |
| Port | -p | Uses specified port instead of default NS port of 53. |
The isi_cbind_d process logs messages to syslog or to stderr, depending on the daemon’s mode. The log level can be changed by sending it a SIGUSR2 signal, which will toggle the debug flag to maximum or back to the original setting. For example:
# kill -USR2 `cat /var/run/isi_cbind_d.pid`
Also, when troubleshooting cbind, the following files can provide useful information:
| File | Description |
| /var/run/isi_cbind_d.pid | the pid of the currently running process |
| /var/crash/isi_cbind_d.dump | output file for internal state and statistics |
| /var/log/isi_cbind_d.log | syslog output file |
| /etc/gconfig/cbind_config.gc | configuration file |
| /etc/resolv.conf | bind resolver configuration file |
Additionally, the internal state data of isi_cbind_d can be dumped to a file specified with the -D option, described in the table above.
Astute observers will also notice the presence of an additional loopback address at 127.42.0.1:
0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> metric 0 mtu 16384 options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6> inet6 ::1 prefixlen 128 zone 1 inet6 fe80::1%lo0 prefixlen 64 scopeid 0x4 zone 1 inet 127.0.0.1 netmask 0xff000000 zone 1 inet 127.42.0.1 netmask 0xffff0000 zone 1 groups: lo nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
# grep 127 /etc/resolv.conf nameserver 127.42.0.1
# sockstat | grep "127.42.0.1:53" root isi_cbind_ 4078 7 udp4 127.42.0.1:53 *:*
This entry is used to ensure that outbound DNS queries are intercepted by cbind, which then either utilizes its cache or reaches out to the DNS servers based on the groupnet configuration. The standard outbound uses the default groupnet, and Auth is forwarded to the appropriate groupnet DNS.