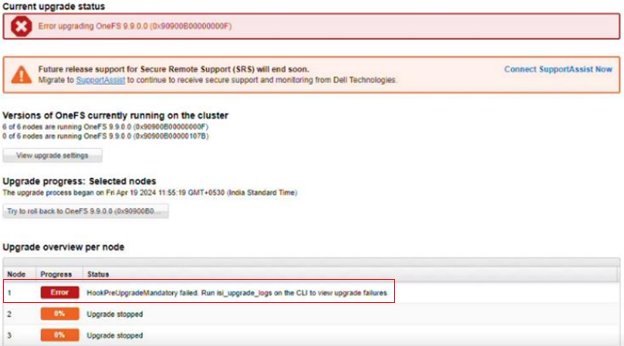
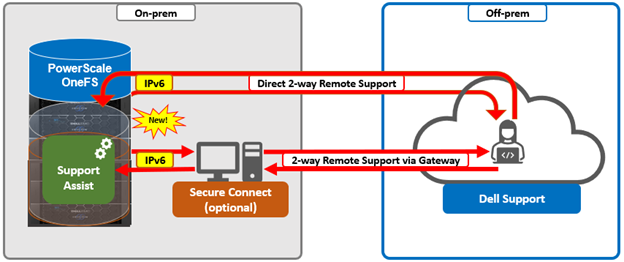
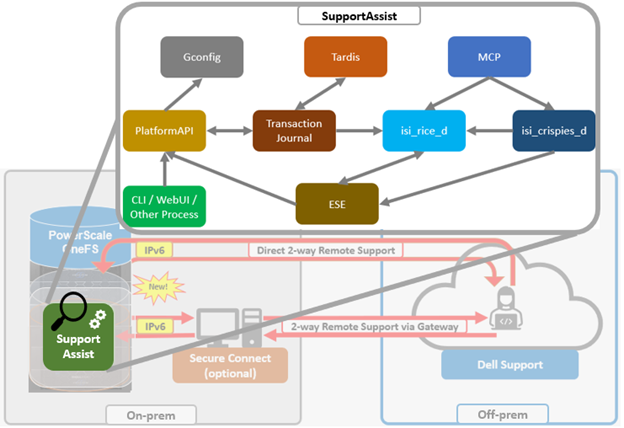
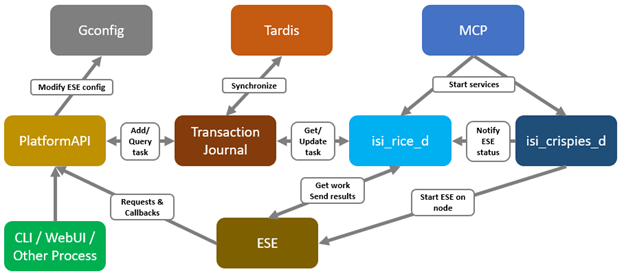
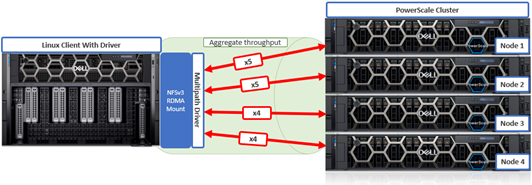
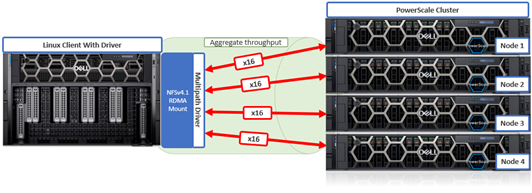
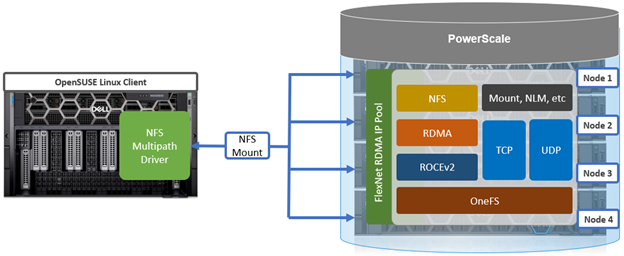
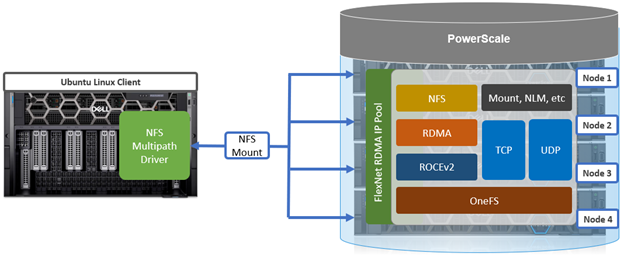
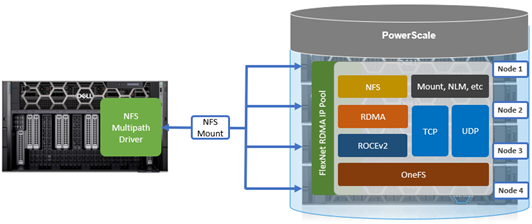
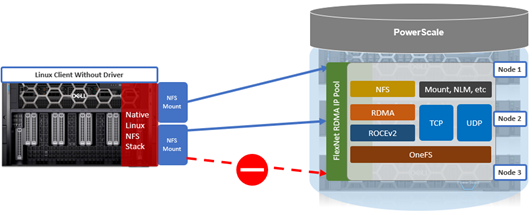
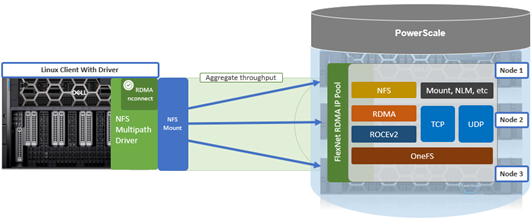
As mentioned in the first article in this series, the PowerScale multipath client driver driver is able to aggregate the performance of multiple PowerScale nodes through a single NFS mount point to one or more Linux clients.
The driver itself is a kernel module, and that means it needs to be installed alongside a corresponding kernel version to that which it was built on. Version matching is strict, right down to the minor build version.
There are two installation options provided for the PowerScale multipath client driver:
- As a pre-built binary installation package for each of the supported Linux distribution versions listed below.
- Or via source code under the GPL 2 open source license, which can be compiled at a customer site.
This article covers the first option, and outlines the steps involved with the installation of the pre-built binary driver package for the following, currently supported Linux versions:
| Linux distribution |
Kernel version |
Upstream driver version (minimum) |
Multipath driver version |
Package
available |
| OpenSUSE 15.4 |
5.14.x |
4.x |
1.x |
ü |
| Ubuntu 20.04 |
5.4.x |
4.x |
1.x |
ü |
| Ubuntu 22.04 |
5.15.x |
4.x |
1.x |
ü |
Package installation is typically handled best by the client Linux distro’s native package manager. Since it’s a kernel module, installing and updating the driver typically requires a reboot. PowerScale engineering anticipate periodically releasing updated driver packages to keep up with Linux on the supported platforms list, as well as fix bugs and add additional functionality.
This multipath client driver runs on both physical and virtual machines, and both x86 CPU architectures and GPU-based platforms, such as the NVIDIA DGX range, are supported.
While there is no specific NFS or OneFS core configuration required on the PowerScale cluster side when using Linux clients with the Dell multipath driver, there are a couple of basic prerequisites. The following OneFS support matrix on the top right of this slide lays out which driver functionality is available in what release, from OneFS 9.5 to current.
| Version |
NFSv3, NFSv4.1 TCP |
NFSv3 RDMA |
NFSv4.1 RDMA |
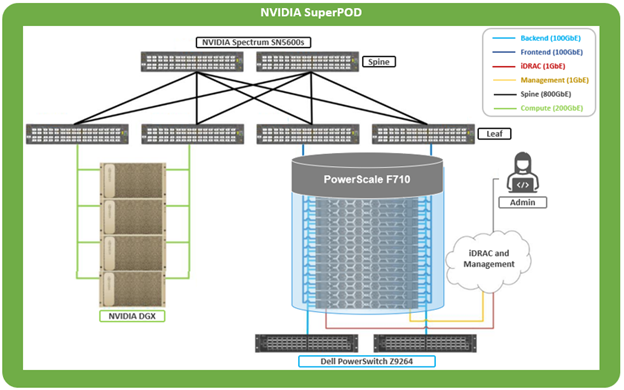
NVIDIA SuperPOD |
| OneFS 9.5 |
Yes |
Yes |
No |
No |
| OneFS 9.7 |
Yes |
Yes |
Yes |
No |
| OneFS 9.9 |
Yes |
Yes |
Yes |
Yes |
Also note that OneFS 9.9 is required for any NVIDIA SuperPOD deployments, because there are some performance optimizations in 9.9 specifically for that platform.
The following CLI commands can be run on the PowerScale cluster to verify its compatibility. The cluster’s current OneFS version can be easily determined using the following CLI command:
# uname -or
Isilon OneFS 9.9.0.0
Also, to confirm RDMA is supported and enabled:
# isi nfs settings global view | grep -i RDMA
NFS RDMA Enabled: Yes
Additionally, both the dynamic and static network pools can be configured on the cluster for use with the multipath driver. If F710 nodes are being deployed in the cluster, OneFS 9.7 or later is required.
Note that when deploying an NVIDIA SuperPOD or BasePOD solution, the reference architecture mandates a PowerScale cluster composed of F710 all-flash nodes running OneFS 9.9 or later.
For a Linux client to successfully connect to a PowerScale cluster using the multipath driver, there are a few prerequisites that must be met, in addition to running one of the Linux versions listed above. These include:
- If RDMA is being configured, the client must contain an RDMA-capable Ethernet NIC, such as the Mellanox CX series.
- The Linux client should have the ‘trace-cmd’ package installed, along with NFS client related packages.
For example, on an Ubuntu system:
# sudo apt install trace-cmd nfs-common
The following CLI commands can be used to verify the kernel version, and other pertinent details, of a Linux client:
# uname -a
Similarly, depending on the flavor of Linux, the following commands will show the details of the particular distribution:
# lsb_release -a
Or:
# cat /etc/os-release
The multipath client driver is available for download on the Dell Support Site to any customer that has OneFS entitlement: For security purposes, the download files are signed with SHA256. Using Debian linux as an example, the driver components can be accessed as follows:
- Verify the SHA256 Checksum Manually
The downloaded driver package’s authenticity can be manually verified via its SHA256 checksum as follows:
First, calculate the checksum on the signed driver package:
# sha256sum dellnfs-modules_4.0.24-Dell-Technologies.kver.5.4.0-190-generic_amd64.deb.signed
Then compare the output with the value in the accompanying checksum file.
- Extract the Signed Package
First, if not already available, install the necessary extraction tools:
# sudo apt-get install ar
Next, extract the signed driver file:
# ar x dellnfs-modules_4.0.24-Dell-Technologies.kver.5.4.0-190-generic_amd64.deb.signed
This should yield multiple extracted files, including the following:
control.tar.xz, data.tar.xz, and debian-binary.
- Repackage the File
If needed, the extracted contents can be repackaged into a standard ‘.deb’ package file:
# ar rcs dellnfs-modules_4.0.24-Dell-Technologies.kver.5.4.0-190-generic_amd64.deb debian-binary control.tar.xz data.tar.xz
- Install the Repackaged Debian File
Once repackaged, you can install the Debian package using the ‘dpkg’ utility. For example:
# sudo dpkg -i dellnfs-modules_4.0.24-Dell-Technologies.kver.5.4.0-190-generic_amd64.deb
Package installation is handled using the native package manager, and each of the supported Linux distributions uses the following format and package installation utility:
| Linux Distribution |
Package Manager |
Package Utility |
| OpenSUSE |
RPM |
Zipper |
| Ubuntu |
Deb |
apt-get / dpkg |
The RPM and DEB packages can either be obtained from the Dell download site or built manually at the customer site.
The multipath client driver is provided as a pre-built binary installation package for each of the supported Linux distribution versions. The process for package installation varies slightly across the different Linux versions, but the basic process is as follows:

Note that the multipath driver installation does require a reboot of the Linux system.
For Ubuntu, the following procedure describes how to install the multipath driver package:

- Download the DEB package.
- Verify that DEB package and Kernel Version Match.
Compare the package version and the kernel version to ensure they are an exact match. If they are not an exact match, do not install the package. Instead, build the driver from source according to the instructions in the “Building and Installing the Driver’ section later in this document.
- Install the DEB package.
# sudo apt-get install ./dist/dellnfs-modules_*-generic_amd64.deb
- Check package is installed correctly.
# dpkg -l | grep dellnfs-modules
dellnfs-modules 2:4.0.22-dell.kver.5.4.0-150-generic amd64 NFS RDMA kernel modules
# dpkg -S /lib/modules/`uname -r`/updates/bundle/net/sunrpc/xprtrdma/rpcrdma.ko
dellnfs-modules: /lib/modules/5.4.0-150-generic/updates/bundle/net/sunrpc/xprtrdma/rpcrdma.ko
Regenerate the running kernel image.
# sudo update-initramfs -u -k `uname -r`
- Reboot the Linux client.
# reboot
- Confirm the module and services are running.
# dellnfs-ctl status
version: 4.0.22-dell
kernel modules: sunrpc rpcrdma compat_nfs_ssc lockd nfs_acl nfs nfsv3
services: rpcbind.socket rpcbind rpc-gssdrpc_pipefs: /run/rpc_pipefs
If the services are not up, run the ‘dellnfs-ctl reload’ command to start the services.
- Verify an NFS mount
Attempt a mount, since NFS occasionally needs to create a symlink to rpc.statd. For example:
# mount -t nfs -o proto=rdma,port=20049,rsize=1048576,wsize=1048576,vers=3,nconnect=32,remoteports=10.231.180.95-10.231.180.98,remoteports_offset=1 10.231.180.95:/ifs/data/fio /mnt/test/
Created symlink /run/systemd/system/remote-fs.target.wants/rpc-statd.service → /lib/systemd/system/rpc-statd.service.
In the above, a symlink created on the first mount. Perform a reload to confirm the service is running correctly. For example:
# dellnfs-ctl reload
dellnfs-ctl: stopping service rpcbind.socket
dellnfs-ctl: umounting fs /run/rpc_pipefs
dellnfs-ctl: unloading kmod nfsv3
dellnfs-ctl: unloading kmod nfs
dellnfs-ctl: unloading kmod nfs_acl
dellnfs-ctl: unloading kmod lockd
dellnfs-ctl: unloading kmod compat_nfs_ssc
dellnfs-ctl: unloading kmod rpcrdma
dellnfs-ctl: unloading kmod sunrpc
dellnfs-ctl: loading kmod sunrpc
dellnfs-ctl: loading kmod rpcrdma
dellnfs-ctl: loading kmod compat_nfs_ssc
dellnfs-ctl: loading kmod lockd
dellnfs-ctl: loading kmod nfs_acl
dellnfs-ctl: loading kmod nfs
dellnfs-ctl: loading kmod nfsv3
dellnfs-ctl: mounting fs /run/rpc_pipefs
dellnfs-ctl: starting service rpcbind.socket
dellnfs-ctl: starting service rpcbind
Similarly, for OpenSUSE and SLES, the driver package installation steps are as follows:

- Download the driver RPM package.
- Verify that RPM package and Kernel Version Match.
Compare the package version and the kernel version to ensure they are an exact match. If they are not an exact match, do not install the package. Instead, build the driver from source according to the instructions in the “Building and Installing the Driver’ section later in this document.
- Install the downloaded RPM package.
# zypper in ./dist/dellnfs-4.0.22-kernel_5.14.21_150400.24.97_default.x86_64.rpm
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following NEW package is going to be installed:
dellnfs
1 new package to install.
- Check the installed files.
# rpm -qa | grep dell
dellnfs-4.0.22-kernel_5.14.21_150400.24.100_default.x86_64
- Reboot the Linux client.
# reboot
- Verify the services are started.
# systemctl start rpcbind
# systemctl start nfs
# systemctl status nfs
nfs.service - Alias for NFS client
Loaded: loaded (/usr/lib/systemd/system/nfs.service; disabled; vendor preset: disabled)
Active: active (exited) since Wed 2023-12-13 15:11:09 PST; 2s ago
Process: 15577 ExecStart=/bin/true (code=exited, status=0/SUCCESS)
Main PID: 15577 (code=exited, status=0/SUCCESS)
- Verify the client driver is loaded with ‘dellnfs-ctl’ script.
# dellnfs-ctl status
version: 4.0.22
kernel modules: sunrpc
services: rpcbind.socket rpcbind
rpc_pipefs: /var/lib/nfs/rpc_pipefs
- Verify an NFS mount
Attempt a mount, since NFS occasionally needs to create a symlink to rpc.statd. For example:
# mount -t nfs -o proto=rdma,port=20049,rsize=1048576,wsize=1048576,vers=3,nconnect=32,remoteports=10.231.180.95-10.231.180.98,remoteports_offset=1 10.231.180.95:/ifs/data/fio /mnt/test/
Created symlink /run/systemd/system/remote-fs.target.wants/rpc-statd.service → /lib/systemd/system/rpc-statd.service.
In the above, a symlink is created on the first mount. Next, perform a reload to confirm the service is running correctly. For example:
# dellnfs-ctl reload
dellnfs-ctl: stopping service rpcbind.socket
dellnfs-ctl: umounting fs /run/rpc_pipefs
dellnfs-ctl: unloading kmod nfsv3
dellnfs-ctl: unloading kmod nfs
dellnfs-ctl: unloading kmod nfs_acl
dellnfs-ctl: unloading kmod lockd
dellnfs-ctl: unloading kmod compat_nfs_ssc
dellnfs-ctl: unloading kmod rpcrdma
dellnfs-ctl: unloading kmod sunrpc
dellnfs-ctl: loading kmod sunrpc
dellnfs-ctl: loading kmod rpcrdma
dellnfs-ctl: loading kmod compat_nfs_ssc
dellnfs-ctl: loading kmod lockd
dellnfs-ctl: loading kmod nfs_acl
dellnfs-ctl: loading kmod nfs
dellnfs-ctl: loading kmod nfsv3
dellnfs-ctl: mounting fs /run/rpc_pipefs
dellnfs-ctl: starting service rpcbind.socket
dellnfs-ctl: starting service rpcbind
Unlike installing the driver, removing it does not typically require a client reboot, and can also be performed via the appropriate package manager for the Linux flavor.
Also, be aware that there are no upgrade or patching systems for the driver. This means that if a client’s kernel version is updated, the module must be re-built or a matching package re-installed. And correspondingly, if there is an update to the dellnfs package, the module must be re-installed.
# sudo update-initramfs -u -k `uname -r`
Next, perform a reload to confirm the service is running correctly. For example:
# dellnfs-ctl reload
dellnfs-ctl: stopping service rpcbind.socket
dellnfs-ctl: umounting fs /run/rpc_pipefs
dellnfs-ctl: unloading kmod nfsv3
dellnfs-ctl: unloading kmod nfs
dellnfs-ctl: unloading kmod nfs_acl
dellnfs-ctl: unloading kmod lockd
dellnfs-ctl: unloading kmod compat_nfs_ssc
dellnfs-ctl: unloading kmod rpcrdma
dellnfs-ctl: unloading kmod sunrpc
dellnfs-ctl: loading kmod sunrpc
dellnfs-ctl: loading kmod rpcrdma
dellnfs-ctl: loading kmod compat_nfs_ssc
dellnfs-ctl: loading kmod lockd
dellnfs-ctl: loading kmod nfs_acl
dellnfs-ctl: loading kmod nfs
dellnfs-ctl: loading kmod nfsv3
dellnfs-ctl: mounting fs /run/rpc_pipefs
dellnfs-ctl: starting service rpcbind.socket
dellnfs-ctl: starting service rpcbind
Note that there are no upgrade or patching systems available for the ‘dellnfs’ multipath driver module. If a Linux client’s kernel version is updated, the module must be rebuilt or a matching package reinstalled. Similarly, if there is an update to the ‘dellnfs’ package, the module must be reinstalled.
Uninstalling the multipath client driver does not require a reboot and can be performed using the standard package manager for the pertinent Linux distribution. This unloads the loaded module and then removes the files. As such, uninstallation is a fairly trivial process.
The package manager commands for each Linux version to remove a package are as follows:
| OS |
Package removal command |
| Ubuntu |
sudo apt-get autoremove <package_name> |
| OpenSUSE/SLES |
zypper remove -u <package_name> |
In the next article in this series, we’ll take a look at the specifics of multipath driver binary package installation.