In the previous blog article, we looked at the mechanism by which OneFS enables non-disruptive upgrades. For NFS users, rolling node upgrades is typically a pretty seamless event since client connections can be dynamically moved and rebalanced across the other nodes. However, for SMB clients, rolling upgrades can be more impactful.
During an upgrade workflow, nodes will reboot, and the SMB protocol service must be stopped temporarily. This results in a brief disruption for Windows clients connected to the rebooting node. To solve this, OneFS 9.2 introduces a drain-based upgrade feature, which provides a mechanism by which nodes are prevented from rebooting or restarting protocol services until all SMB clients have disconnected from the node. A single SMB client that does not disconnect can cause the upgrade to be delayed indefinitely, so the cluster administrator is provided with options to reboot the node despite persisting clients.
The drain-based upgrade supports both OneFS, firmware and combined upgrades, and can be configured and managed via the OneFS WebUI, CLI, and RESTful platform API.
- SMB protocol
- OneFS upgrades
- Firmware upgrades
- Cluster reboots
- Combined upgrades (OneFS and Firmware)
Drain-based upgrade is predicated upon the parallel upgrade workflow, covered in a previous article, and which offers accelerated upgrades for large clusters by working across OneFS neighborhoods, or fault domains. By concurrently upgrading a node per neighborhood, the more node neighborhoods there are within a cluster the more parallel activity can occur.
For simplicities sake, assume a PowerScale cluster comprising five H700 chassis, divided into two neighborhoods, each containing ten nodes.
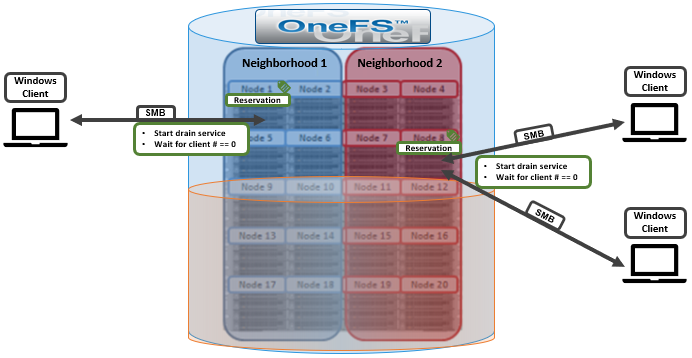
The following CLI command can be used to identify the correlation between the cluster’s nodes and OneFS neighborhoods, or failure domains:
# sysctl efs.lin.lock.initiator.coordinator_weights
Once the drain-based upgrade is started, a maximum of one node from each neighborhood will get the reservation which allows the nodes to upgrade simultaneously. OneFS will not reboot these nodes until the number of SMB clients is “0”. In this example Node 1 and Node 8 get the reservation for upgrading at the same time. However, there is one SMB connection to Node 1 and two SMB connections to Node 8. Neither of these nodes will be able to reboot until their SMB connection count gets to “0”. At this point, there are three options available:
| Drain Action | Description |
| Wait | Wait until the SMB connection count reaches “0” or it hits the drain timeout value. The drain timeout value isa configurable parameter for each upgrade process. It is the maximum waiting period. If drain timeout is set to “0”, it means wait forever. |
| Delay drain | Add the node into the delay list to delay client draining. The upgrade process will continue on another node in this neighborhood. After all the non-delayed nodes are upgraded, OneFS will rewind to the node in the delay list. |
| Skip drain | Stop waiting for clients to migrate away from the draining node and reboot immediately. |
The following CLI command can be used to confirm whether there are any active SMB connections. In this case, node 1 has one connected Windows client:
# isi statistics query current --keys=node.clientstats.connected.smb Node node.clientstats.connected.smb ------------------------------------- 1 1 -------------------------------------
The ‘isi upgrade’ CLI command syntax can be used to perform the drain-based upgrade, and now includes flags for configuring drain-timeout and alert-timeout. In this example setting each to value 60 minutes and 45 minutes respectively. As such, if there is still an SMB connection after 45 minutes, a CELOG alert will be triggered to notify the cluster administrator. And after an hour, any remaining SMB connections will be dropped and the node upgrade reboot will continue.
# isi upgrade start --parallel --skip-optional --install-image-path=/ifs /data/<installation-file-name> --drain-timeout=60m --alert-timeout=45m
From the OneFS WebUI, the same can be achieved by navigating to Upgrade under Cluster management. In the example below, the WebUI indicates that node 1 is waiting for a draining SMB client. The response can be either to Skip or Delay.
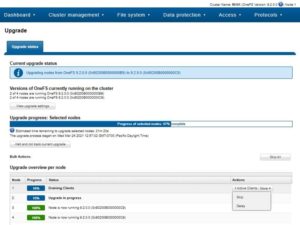
If ‘Delay’ is selected, node one pauses to allow the remaining active client connection to drain:
After ‘Skip’ is chosen, the active client count is reduced to 0 and upgrade continues:
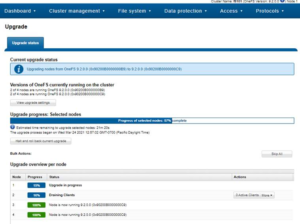
Here, the WebUI reports that node 2 has completed upgraded and is in the process of rebooting:
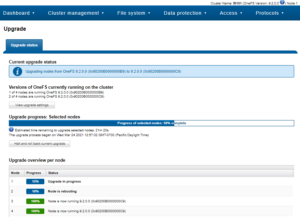
Once all nodes have completed, the upgrade can be committed by running the following command:
# isi upgrade cluster commit
Or from the WebUI:
Finally, confirm that the current version of OneFS is correct by running the following command:
# isi version