When it comes to updating the OneFS version on a cluster, there are three primary options:
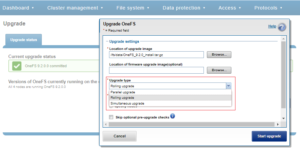
Of these, the simultaneous reboot is fast but disruptive, in that all the cluster’s nodes are upgraded and restarted in unison.
The other two options, rolling and parallel, are non-disruptive upgrades (NDUs), which allow a storage admin to upgrade a cluster while their end users continue to access data.
During the rolling upgrade process, one node at a time is updated to the new code, and the active clients attached to it are automatically migrated to other nodes in the cluster. Partial upgrade is also permitted, whereby a subset of cluster nodes can be upgraded, and the subset of nodes may also be grown during the upgrade. OneFS also allows an upgrade to be paused and resumed enabling customers to span upgrades over multiple smaller Maintenance Windows.
However, for larger clusters, OneFS also offers a parallel upgrade option. Parallel upgrade provides upgrade efficiency within node pools on clusters with multiple neighborhoods (availability zones), allowing the simultaneous upgrading of a node per neighborhood until the pool is complete . By doing this, the upgrade duration is dramatically reduced, while ensuring that end-users still continue to have full access to their data.
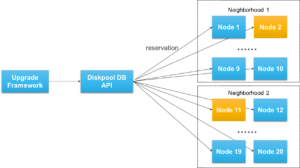
The parallel upgrade option avoids rebooting nodes unless a Diskpools DB reservation can be taken on that node. Each node runs the pre-upgrade optional and mandatory steps in lockstep. Nodes will not proceed to the MarkUpgrading state until the pre-upgrade checks have run successfully on all nodes. Once a node has reached the MarkUpgrading state, it will proceed through the upgrade hooks without regard for the completion state of hook on other nodes (ie not in lockstep).
Given that OneFS’ parallel upgrade option can dramatically improve the OneFS upgrade efficiency without impacting the data availability, the following formula can be used to estimate the duration of the parallel upgrade:
𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 = (𝑝𝑒𝑟 𝑛𝑜𝑑𝑒 𝑢𝑝𝑔𝑟𝑎𝑑𝑒 𝑑𝑢𝑟𝑎𝑡𝑖𝑜𝑛) × (ℎ𝑖𝑔ℎ𝑒𝑠𝑡 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑛𝑜𝑑𝑒𝑠 𝑝𝑒𝑟 𝑛𝑒𝑖𝑔ℎ𝑏𝑜𝑟ℎ𝑜𝑜𝑑)
In the above formula:
- The first parameter – per node upgrade duration – is around 20 minutes on average.
- The second parameter – the highest number of nodes per neighborhood – can be obtained by running the following CLI command:
# sysctl efs.lin.lock.initiator.coordinator_weights
For example, consider a 150 node OneFS cluster. In an ideal layout, there would be 15 neighborhoods, each containing ten nodes. Neighborhood 1 would comprise nodes 1 to 10, neighborhood 2, nodes 11 to 20, and so on and so forth.
During the parallel upgrade, the upgrade framework will pick at most one node from each neighborhood, to run the upgrading job simultaneously. So in this case, node 1 from neighborhood 1st, node 11 from neighborhood 2nd, node 21 from neighborhood 3rd and etc will be upgraded at the same time. Considering, they are all in different neighborhoods or failure domain, it will not impact the current running workload. After the first pass completes, it will go to the 2nd pass and then 3rd and etc.
So, in the 150 node example above, the estimated duration of the parallel upgrade is 200 minutes:
𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 = (𝑝𝑒𝑟 𝑛𝑜𝑑𝑒 𝑢𝑝𝑔𝑟𝑎𝑑𝑒 𝑑𝑢𝑟𝑎𝑡𝑖𝑜𝑛) × (ℎ𝑖𝑔ℎ𝑒𝑠𝑡 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑛𝑜𝑑𝑒𝑠 𝑝𝑒𝑟 𝑛𝑒𝑖𝑔ℎ𝑏𝑜𝑟ℎ𝑜𝑜𝑑) = 20 × 10 = 200 𝑚𝑖𝑛𝑢𝑡𝑒𝑠
Under the hood, the OneFS non-disruptive upgrade system consists an UpgradeAgent and UpgradeSupervisor components.
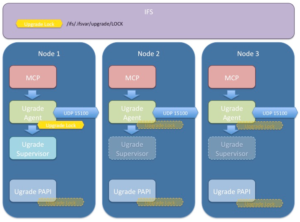
The UpgradeAgent is a daemon that runs on every node. The UpgradeAgent’s role is to continually attempt to advance the upgrade process through to completion. It accomplishes this doing two things:
- Ensuring that an UpgradeSupervisoris running somewhere on the cluster by (a) checking to see if an upgrade is in progress and (b) waiting for its time slot, grabbing a lock file and then attempting to launch a supervisor.
- Receiving messages from any actively running UpgradeSupervisorand taking action on those messages.
The UpgradeSupervisor is a short-lived process which assesses the current state of the cluster and then takes action to advance the progress of the upgrade. The UpgradeSupervisor is stateless. It collects the persistent state of each node from that node’s UpgradeAgent using a status message. It also collects any information persistent on a cluster-wide basis. After reconstructing the current state of the upgrade process, it will then take action to affect the progress of the upgrade by dispatching an action message to the appropriate UpgradeAgent.
Since isi upgrade is an asynchronous process, the nodes in the cluster take turns running the controlling process. As such, the process that starts the upgrade does not run the upgrade but only sets it up. So when an ‘isi upgrade’ CLI command is run it will return fairly quickly. This also means that can’t stop the upgrade by stopping one process. Instead, a stop and restart option is provided using the ‘isi upgrade pause’ and ‘isi upgrade resume’ CLI commands.
Parallel upgrades are easily configured from the OneFS CLI by navigating to Cluster Management > Upgrade, and selecting ‘Parallel upgrade’ from the Upgrade type drop-down menu:
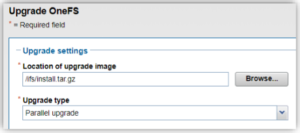
This can also be kicked-off from the OneFS command line using the following CLI syntax:
# isi upgrade start --parallel <upgrade_image>
Similarly, to start a rolling upgrade, which is the default, run:
# isi upgrade cluster start <upgrade_image>
The following CLI syntax will initiate a simultaneous upgrade:
# isi upgrade cluster start --simultaneous <upgrade_image>
Note that the upgrade framework always defaults to a rolling upgrade. Caution is advised when using the CLI to perform a simultaneous upgrade and the scheduling ‘type’ must be specified, i.e., –rolling, –simultaneous or –parallel
For example:
# isi upgrade cluster start /ifs/install.tar isi upgrade cluster start <code_path>
Since OneFS supports the ability to roll back to the previous version, in-order to complete an upgrade it must be committed.
isi upgrade cluster commit
Up until the time an upgrade is committed, an upgrade can be rolled back to the prior version as follows.
isi upgrade cluster rollback
The isi upgrade view CLI command can be used to monitor how the upgrade is progressing:
# isi upgrade viewisi upgrade view -i/--interactive
The following command will provide more detailed/verbose output:
# isi_upgrade_status
A faster, simpler version of isi_upgrade_status is also available:
# isi_upgrade_node_state-a (aggregate the latest hook update for each node)-devid=<X,Y,E-F> (filter and display by devid)-lnn=<X-Y,A,C> (filter and display by LNN)-ts (time sort entries)
If the end of a maintenance window is reached but the cluster is not fully upgraded, the upgrade process can be quiesced and then restarted using the following CLI commands:
# isi upgrade pause # isi upgrade resume
For example:
# isi upgrade pause You are about to pause the running process, are you sure? (yes/[no]): yes
The process will be paused once the current step completes.
The current operation can be resumed with the command:
# isi upgrade resume
Note that pausing is not immediate: The upgrade will remain in a “Pausing” state until the currently
upgrading node is completed. Additional nodes will not be upgraded until the upgrade process is resumed.
The ‘pausing’ state can be viewed with the following commands: ‘isi upgrade view’ and ‘isi_upgrade_status’. Note that a rollback can be initiated either during ‘Pausing’ or ‘Paused’ states. Also, be aware that the ‘isi upgrade pause’ command has no effect when performing a simultaneous OneFS upgrade.
A rolling reboot can be initiated from the CLI on a subset of cluster nodes using the ‘isi upgrade rolling-reboot’ syntax and the ‘–nodes’ flag specifying the desired LNNs for upgrade:
# isi upgrade rolling-reboot --help
Description:
Perform a Rolling Reboot of cluster.
Required Privileges:
ISI_PRIV_SYS_UPGRADE
Usage:
isi upgrade cluster rolling-reboot
[--nodes <integer_range_list>]
[--force]
[{--help | -h}]
Options:
--nodes <integer_range_list>
List of comma (1,3,7) or dash (1-7) specified node LNNs to select. "all"
can also be used to select all the cluster nodes at any given time.
Display Options:
--force
Do not ask confirmation.
--help | -h
Display help for this command.
This ‘isi upgrade view’ syntax provides better visibility, status and progress of the rolling reboot process. For example:
# isi upgrade view Upgrade Status: Current Upgrade Activity: RollingReboot Cluster Upgrade State: committed Upgrade Process State: Not started Current OS Version: 9.2.0.0 Upgrade OS Version: N/A Percent Complete: 0% Nodes Progress: Total Cluster Nodes: 3 Nodes On Older OS: 3 Nodes Upgraded: 0 Nodes Transitioning/Down: 0 LNN Progress Version Status --------------------------------- 1 100% 9.2.0.0 committed 2 rebooting Unknown non-responsive 3 0% 9.2.0.0 committed
Due to the duration of OneFS upgrades on larger clusters, it can sometimes be unclear if an OS upgrade is actually progressing or has stalled. To address this, if an upgrade is not making progress after fifteen minutes, the upgrade framework automatically sends a SW_UPGRADE_NODE_NON_RESPONSIVE alert via CELOG. For example:
# isi event events list ID Occurred Sev Lnn Eventgroup ID Message --------------------------------------------------------------------------------------------------------------- 2.1805 06/14 04:33 C 2 1087 Excessive Time executing a Hook on Node: 3
# isi status ... Critical Events: Time LNN Event --------------- ---- ------------------------------ 06/14 05:16:30 2 Excessive Time executing a ... ...
The isi_upgrade_logs command also provides detailed upgrade tracking and debugging data.
Usage: isi_upgrade_logs [-a|--assessment][--lnn][--process {process name}][--level {start level,end level][--time {start time,end time][--guid {guid} | --devid {devid}]
+ No parameter this utility will pull error logs for the current upgrade process
+ -a or --assessment - will interrogate the last upgrade assessment run and display the results
The following arguments enable filtering to help extract the desired upgrade information:
| Filter CMD Flag | Description |
| –guid | dump the logs for the node with the supplied guid |
| –devid | dump the logs for the node/s with the supplied devid/s |
| –lnn | dump the logs for the node/s with the supplied lnn/s |
| –process | dump the logs for the node with the supplied process name |
| –level | dump the logs for the supplied level range |
| –time | dump the logs for the supplied time range |
| –metadata | dump the logs matching the supplied regex |
For example, to display all of the logs generated by isi_upgrade_agent_d on the node with LNN1:
# isi_upgrade_logs --lnn 1 --process /usr/sbin/isi_upgrade_agent_d … 1 2021-06-14T18:06:15 /usr/sbin/isi_upgrade_agent_d Debug Starting /usr/share/upgrade/event-actions/pre-upgrade-optional/read_only_node_check.py 1 2021-06-14T23:59:59 /usr/sbin/isi_upgrade_agent_d Debug Starting /usr/share/upgrade/event-actions/pre-upgrade-optional/isi_upgrade_checker 1 2021-06-14T18:06:15 /usr/sbin/isi_upgrade_agent_d Debug Starting /usr/share/upgrade/event-actions/pre-upgrade-optional/volcopy_check 1 2021-06-14T18:06:15 /usr/sbin/isi_upgrade_agent_d Debug Starting /usr/share/upgrade/event-actions/pre-upgrade-optional/empty 1 2021-06-14T18:06:15 /usr/sbin/isi_upgrade_agent_d Debug Starting Hook [/usr/share/upgrade/event-actions/pre-upgrade-optional/read_only_node_check.py] …
Note that the ‘–process’ flag requires the full name including path to be specified, as it is displayed in the logs.
For example, the following CLI syntax displays a list all of the Upgrade-related process names that have logged to LNN 1:
# isi_upgrade_logs --lnn 1 | awk ‘{print $3}’ | sort | uniq
These process names can then be added to the ‘–process’ argument.