Archive applications such as next generation healthcare Picture Archiving and Communication Systems (PACS) are increasingly moving away from housing large archive file formats (such as tar and zip files) to storing the smaller files individually. To directly address this trend, OneFS now includes a Small File Storage Efficiency (SFSE) component. This feature maximizes the space utilization of a cluster by decreasing the amount of physical storage required to house the small files that often comprise an archive, such as a typical healthcare DICOM dataset.
Efficiency is achieved by scanning the on-disk data for small files and packing them into larger OneFS data structures, known as shadow stores. These shadow stores are then parity protected using erasure coding, and typically provide storage efficiency of 80% or greater.
OneFS Storage Efficiency for is specifically designed for infrequently modified, archive datasets. As such, it trades a small read latency performance penalty for improved storage utilization. Files obviously remain writable, since archive applications are assumed to periodically need to update at least some of the small file data.
Small File Storage Efficiency is predicated on the notion of containerization of files, and comprises six main components:
- File pool configuration policy
- SmartPools Job
- Shadow Store
- Configuration control path
- File packing and data layout infrastructure
- Defragmenter
The way data is laid out across the nodes and their respective disks in a cluster is fundamental to OneFS functionality. OneFS is a single file system providing one vast, scalable namespace—free from multiple volume concatenations or single points of failure. As such, a cluster can support data sets with hundreds of billions of small files all within the same file system.
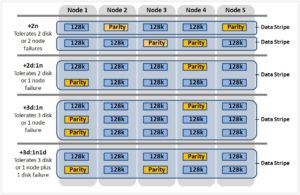
OneFS lays data out across multiple nodes allowing files to benefit from the resources (spindles and cache) of up to twenty nodes. Reed-Solomon erasure coding is used to protecting at the file-level, enabling the cluster to recover data quickly and efficiently, and providing exceptional levels storage utilization. OneFS provides protection against up to four simultaneous component failures respectively. A single failure can be as little as an individual disk or an entire node.
A variety of mirroring options are also available, and OneFS typically uses these to protect metadata and small files. Striped, distributed metadata coupled with continuous auto-balancing affords OneFS near linear performance characteristics, regardless of the capacity utilization of the system. Both metadata and file data are spread across the entire cluster keeping the cluster balanced at all times.
The OneFS file system employs a native block size of 8KB, and sixteen of these blocks are combined to create a 128KB stripe unit. Files larger than 128K are protected with error-correcting code parity blocks (FEC) and striped across nodes. This allows files to use the combined resources of up to twenty nodes, based on per-file policies.
Files smaller than 128KB are unable to fill a stripe unit, so are mirrored rather than FEC protected, resulting in a less efficient on-disk footprint. For most data sets, this is rarely an issue, since the presence of a smaller number of larger FEC protected files offsets the mirroring of the small files.
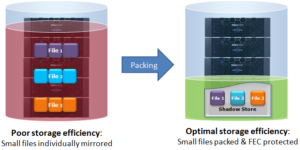
For example, if a file is 24KB in size, it will occupy three 8KB blocks. If it has two mirrors for protection, there will be a total of nine 8KB blocks, or 72KB, that will be needed to protect and store it on disk. Clearly, being able to pack several of these small files into a larger, striped and parity protected container will provide a great space benefit.
Additionally, files in the 150KB to 300KB range typically see utilization of around 50%, as compared to 80% or better when containerized with the OneFS Small File Storage Efficiency feature.
Under the hood, the OneFS small file packing has similarities to the OneFS file cloning process, and both operations utilize the same underlying infrastructure – the shadow store.
Shadow stores are similar to regular files, but don’t contain all the metadata typically associated with regular file inodes. In particular, time-based attributes (creation time, modification time, etc.) are explicitly not maintained. The shadow stores for storage efficiency differ from existing shadow stores in a few ways in order to isolate fragmentation, to support tiering, and to support future optimizations which will be specific to single-reference stores.
Containerization is managed by the SmartPools job. This job typically runs by default on a cluster with a 10pm nightly schedule and a low impact management setting but can also be run manually on-demand. Additionally, the SmartPoolsTree job, isi filepool apply, and the isi set command are also able to perform file packing.
File attributes indicate each file’s pack state:
packing_policy: container or native. This indicates whether the file meets the criteria set by your file pool policies and is eligible for packing. Container indicates that the file is eligible to be packed; native indicates that the file is not eligible to be packed. Your file pool policies determine this value. The value is updated by the SmartPools job.
packing_target: container or native. This is how the system evaluates a file’s eligibility for packing based on additional criteria such as file size, type, and age. Container indicates that the file should reside in a container shadow store. Native indicates that the file should not be containerized.
packing_complete: complete or incomplete. This field establishes whether or not the target is satisfied. Complete indicates that the target is satisfied, and the file is packed. Incomplete indicates that the target is not satisfied, and the packing operation is not finished.
It’s worth noting that several healthcare archive applications can natively perform file containerization. In these cases, the benefits of OneFS small file efficiency will be negated.
Before configuring small file storage efficiency on a cluster, make sure that the following pre-requisites are met:
- Only enable on an archive workflow: This is strictly an archive solution. An active dataset, particularly one involving overwrites and deletes of containerized files, can generate fragmentation which impacts performance and storage efficiency.
- The majority of the archived data comprises small files. By default, the threshold target file size is from 0-1 MB.
- SmartPools software is licensed and active on the cluster.
Additionally, it’s highly recommended to have InsightIQ software licensed on the cluster. This enables the file systems analysis (FSAnalyze) job to be run, which provides enhanced storage efficiency reporting statistics.
The first step in configuring small file storage efficiency on a cluster is to enable the packing process. To do so, run the following command from the OneFS CLI:
# isi_packing –-enabled=true
Once the isi_packing variable is set, and the licensing agreement is confirmed, configuration is done via a filepool policy. The following CLI example will containerize data under the cluster directory /ifs/data/dicom.
# isi filepool policies create dicom --enable-packing=true --begin-filter --path=/ifs/data/pacs --end-filter
The SmartPools configuration for the resulting ‘dicom’ filepool can be verified with the following command:
# isi filepool policies view dicom Name: dicom Description: - State: OK State Details: Apply Order: 1 File Matching Pattern: Birth Time > 1D AND Path == dicom (begins with) Set Requested Protection: - Data Access Pattern: - Enable Coalescer: - Enable Packing: Yes ...
Note: There is no dedicated WebUI for OneFS small file storage efficiency, so configuration is performed via the CLI.
The isi_packing command will also confirm that packing has been enabled:
# isi_packing –-ls Enabled: Yes Enable ADS: No Enable snapshots: No Enable mirror containers: No Enable mirror translation: No Unpack recently modified: No Unpack snapshots: No Avoid deduped files: Yes Maximum file size: 1016.0k SIN cache cutoff size: 8.00M Minimum age before packing: 0s Directory hint maximum entries: 16 Container minimum size: 1016.0k Container maximum size: 1.000G
While the defaults will work for most use cases, the two values you may wish to adjust are maximum file size (–max-size <bytes>) and minimum age for packing (–min-age <seconds>).
Files are then containerized in the background via the SmartPools job, which can be run on-demand, or via the nightly schedule.
# isi job jobs start SmartPools Started job [1016]
After enabling a new filepool policy, the SmartPools job may take a relatively long time due to packing work. However, subsequent job runs should be significantly faster.
Small file storage efficiency reporting can be viewed via the SmartPools job reports, which detail the number of files packed. For example:
# isi job reports view –v 1016
For clusters with a valid InsightIQ license, if the FSA (file system analytics) job has run, a limited efficiency report will be available. This can be viewed via the following command:
# isi_packing -–fsa
For clusters using CloudPools software, you cannot containerize stubbed files. SyncIQ data will be unpacked, so packing will need to be configured on the target cluster.
To unpack previously packed, or containerized, files, in this case from the ‘dicom’ filepool policy, run the following command from the OneFS CLI:
# isi filepool policies modify dicom -–enable-packing=false
Before performing any unpacking, ensure there’s sufficient free space on the cluster. Also, be aware that any data in a snapshot won’t be packed – only HEAD file data will be containerized.
A threshold is provided, which prevents very recently modified files from being containerized. The default value for this is 24 hours, but this can be reconfigured via the isi_packing –min-age <seconds> command, if desired. This threshold guards against accidental misconfiguration within a filepool policy, which could potentially lead to containerization of files which are actively being modified, which could result in container fragmentation.