Received a couple of recent questions from the field around the what’s and why’s of OneFS automatic replacement recognition and thought it would make a useful blog article topic.
OneFS Automatic Replacement Recognition (ARR) helps simplify node drive replacements and management by integrating drive discovery and formatting into a single, seamless workflow.
When a node in a cluster experiences a drive failure, it needs to be replaced by either the customer or a field service tech. Automatic replacement recognition (ARR) helps streamline this process, which previously required requires significantly more than simply physically replace the failed drive, necessitating access to the cluster’s serial console, CLI, or WebUI.
ARR simplifies the drive replacement process so that, for many of the common drive failure scenarios, the user no longer needs to manually issue a series of commands to bring the drive into use by the filesystem. Instead, ARR keeps the expander port (PHY) on so the SAS controller can easily discover whether a new drive has been inserted into a particular bay.
As we will see, OneFS has an enhanced range of cluster (CELOG) events and alerts, plus a drive fault LED sequence to guide the replacement process
Note: Automated drive replacement is limited to data drives. Boot drives, including those in bootflash chassis (IMDD) and accelerator nodes, are not supported.
ARR is enabled by default for PowerScale and Isilon Gen 6 nodes. Additionally, it also covers several previous generation nodes, including S210, X210, NL410, and HD400.
With the exception of a PHY storm, for example, expander ports are left enabled for most common drive failure scenarios to allow the SAS controller to discover new drive upon insertion. However, other drive failure scenarios may be more serious, such as the ones due to hardware failures. Certain types of hardware failures will require the cluster administrator to explicitly override the default system behavior to enable the PHY for drive replacement.
ARR also identifies and screens the various types of replacement drive. For example, some replacement drives may have come from another cluster or from a different node within the same cluster. These previously used drives cannot be automatically brought into use by the filesystem without the potential risk of losing existing data. Other replacement drives may have been previously failed and so not qualify for automatic drive re-format and filesystem join.
At its core, ARR supports automatic discovery of a new drives to simplify and automate drive replacement wherever it makes sense to do so. In order for the OneFS drive daemon, drive_d, to act autonomously with minimal user intervention, it must:
- Enhance expander port management to leave PHY enabled (where the severity of the error is considered non-critical).
- Filter the drive replacement type to guard against potential data loss due to drive format.
- Log events and fire alerts, especially when the system encounters an error.
ARR automatically detects the replacement drive’s state in order to take the appropriate action. These actions include:
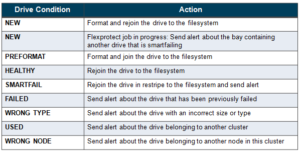
Part of automating the drive replacement process is to qualify drives that can be readily formatted and added to the filesystem. The detection of a drive insertion is driven by the “bay change” event where the bay transitions from having no drive or having some drive to having a different drive.
During a node’s initialization boot, newfs_efs is run initially to ‘preformat’ all the data drives. Next, mount identifies these preformatted drives and assigns each of them a drive GUID and a logical drive number (LNUM). The mount daemon then formats each drive and writes its GUID and LNUM pairing to the drive config, (drives.xml).
ARR is enabled by default but can be easily disabled if desired. To configure this from the WebUI, navigate to Cluster Management -> Automatic Replacement Recognition and select ‘Disable ARR’.
This ARR parameter can also be viewed or modified via the “isi devices config” CLI command:
# isi devices config view --node-lnn all | egrep "Lnn|Automatic Replacement Recognition" -A1 | egrep -v "Stall|--" | more Lnn: 1 Instant Secure Erase: Automatic Replacement Recognition: Enabled : True Lnn: 2 Instant Secure Erase: Automatic Replacement Recognition: Enabled : True Lnn: 3 Instant Secure Erase: Automatic Replacement Recognition: Enabled : True Lnn: 4 Instant Secure Erase: Automatic Replacement Recognition: Enabled : True
For an ARR enabled cluster, the CLI command ‘isi devices drive add <bay>’ both formats and brings the new drive into use by the filesystem.
This is in contrast to previous releases, where the cluster administrator had to issue a series of CLI or WebUI commands to achieve this (e.g. ‘isi devices drive add <bay> and ‘isi devices drive format <bay>’.
ARR is also configurable via the corresponding platformAPI URLs:
- GET “platform/5/cluster/nodes”
- GET/PUT “platform/5/cluster/nodes/<lnn>”
- GET/PUT “platform/5/cluster/nodes/<lnn>/driveconfig”
Alerts are a mechanism for the cluster to notify the user of critical events. It is essential to provide clear guidance to the user on how to proceed with drive replacement under these different scenarios. Several new alerts warn the user about potential problems with the replacement drive where the resolution requires manual intervention beyond simply replacing the drive.
The following CELOG events are generated for drive state alerts:
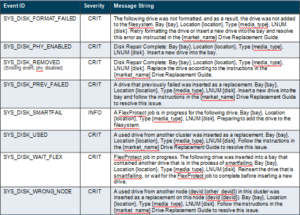
For the SYS_DISK_SMARTFAIL and SYS_DISK_PHY_ENABLED scenarios, the alert will only be issued if ARR is enabled. More specifically, the SYS_DISK_SMARTFAIL scenario arises when an ARR-initiated filesystem join takes place. This alert will not be triggered by a user-driven process, such as when the user runs a stopfail CLI command. For the SYS_DISK_PHY_DISABLED scenario, the alert will be generated every time a drive failure occurs in a way that would render the phy disabled, regardless of ARR status.
As mentioned previously, ARR can be switched on or off anytime. Disabling ARR involves replacing the SYS_DISK_PHY_ENABLED alert with a SYS_DISK_PHY_DISABLED one.
For information and troubleshooting purposes, in addition to events and alerts, there is also an isi_drive_d.log and isi_drive_history.log under /var/log on each node.
For example, these log messages indicate that drive da10 is being smartfailed:
isi_drive_d.log:2020-07-20T17:23:02-04:00 <3.3> h500-1 isi_drive_d[18656]: Smartfailing drive da10: RPC request @ Mon Jul 3 17:23:02 2020 isi_drive_history.log:2020-07-21T17:23:02-04:00 <16.5> h500-1 isi_drive_d[18656]: smartfail RPC request bay:5 unit:10 dev:da10 Lnum:6 seq:6 model:'ST8000NM0045-1RL112' FW:UG05 SN:ZA11DEMC WWN:5000c5009129d2ff blocks:1953506646 GUID:794902d73fb958a9593560bc0007a21b usr:ACTIVE present:1 drv:OK sf:0 purpose:STORAGE
The command ‘isi devices drive view’ confirms the details and smartfail status of this drive:
h500-1# isi devices drive view B2 Lnn: 1 Location: Bay A2 Lnum: 6 Device: /dev/da10 Baynum: 5 Handle: 348 Serial: ZA11DEMC Model: ST2000NM0045-1RL112 Tech: SATA Media: HDD Blocks: 1953506646 Logical Block Length: 4096 Physical Block Length: 4096 WWN: 5000C5009129D2FF State: SMARTFAIL Purpose: STORAGE Purpose Description: A drive used for normal data storage operation Present: Yes Percent Formatted: 100
Similarly, the following log message indicates that ARR is enabled and the drive da10 is being automatically added:
isi_drive_d.log:2020-07-20T17:16:57-04:00 <3.6> h500-1 isi_drive_d[4638]: /b/mnt/src/isilon/bin/isi_drive_d/drive_state.c:drive_event_start_add:248: Proceeding to add drive da10: bay=A2, in_purpose=STORAGE, dd_phase=1, conf.arr.enabled=1
There are two general situations where a failed drive is encountered:
- A drive fails due to hardware failure
- A previously failed drive is re-inserted into the bay as a replacement drive.
For both of these situations, an alert message is generated.
For self-encrypting drives (SEDs), extra steps are required to check replacement drives, but the general procedure applies to regular storage drives as well. For every drive that has ever been successfully formatted and assigned a LNUM, store its serial number (SN) and worldwide name (WWN) along with its LNUM and bay number in an XML file (i.e. ‘isi drive history.xml’).
Each entry is time-stamped to allow chronological search, in case there are multiple entries with the same SN and WWN, but different LNUM or bay number. The primary key to these entries is LNUM, with the maximum number of entries being 250 (the current OneFS logical drive number limit.
When a replacement drive is being presented for formatting, drive_d checks the drive’s SN and WWN against the history and look for the most recent entry. If a match is found, drive_d should do a reverse look up on drives.xml based on the entry’s LNUM to check the last known drive state. If the last known drive state is ok, the replacement drive can be automatically formatted and joined to the filesystem. Otherwise, the user will be alerted to take manual, corrective action.
A previously used drive is one that has an unknown drive GUID in the superblock of the drive’s data partition. In particular, an unknown drive GUID is one that does not match either the preformat GUID or one of the drive GUIDs listed in /etc/ifs/drives.xml. The drives.xml file contains a record of all the drives that are local to the node and can be used to ascertain whether a replacement drive has been previously used by the node.
A used drive can come from one of two origins:
- From a different node within the same cluster or
- From a different cluster.
To distinguish between these two origins, the cluster GUID from the drive’s superblock is compared against the cluster GUID from /etc/ifs/array.xml order to distinguish between the two cases above. If a match is found, a used drive from the same cluster will be identified by a WRONG_NODE user state. Otherwise, a used drive from a foreign cluster will be tagged with the USED user state. If for some reason, array.xml is not available, the user state of the used drive of an unknown origin will default to USED.
The amber disk failure LEDs on a node’s drive bays (and on each of a Gen6 node’s five drive sleds) indicate when, and in which bay, it is safe to replace the failed drive. The behavior of the failure LEDs for the drive replacement is as such:
- drive_d enables the failure LED when restripe completes.
- drive_d clears the failure LED upon insertion of a replacement drive into the bay.
- If ARR is enabled:
- The failure LED is lit if drive_d detects an unusable drive during the drive discovery phase but before auto format starts. Unusable drives include WRONG_NODE drives, used drives, previously failed drives, and drives of the wrong type.
- The failure LED is also lit if drive_d encounters any format error.
- The failure LED stays off if nothing goes wrong.
- If ARR is disabled: the failure LED will remain off until the user chooses to manually format the drive.