As we’ve seen throughout the recent file system maintenance job articles, OneFS utilizes file system scans to perform such tasks as detecting and repairing drive errors, reclaiming freed blocks, etc. Since these scans typically involve complex sequences of operations, they are implemented via syscalls and coordinated by the Job Engine. These jobs are generally intended to run as minimally disruptive background tasks in the cluster, using spare or reserved capacity.
| FS Maintenance Job | Description |
| AutoBalance | Restores node and drive free space balance |
| Collect | Reclaims leaked blocks |
| FlexProtect | Replaces the traditional RAID rebuild process |
| MediaScan | Scrub disks for media-level errors |
| MultiScan | Run AutoBalance and Collect jobs concurrently |
In this final article of the series, we’ll turn our attention to MultiScan. This job is a combination of both the of the AutoBalance job, which rebalances data across drives, and the Collect job, which recovers leaked blocks from the filesystem. In addition to reclaiming unused capacity as a result of drive replacements, snapshot and data deletes, etc, MultiScan also helps expose and remediate any filesystem inconsistencies.
The OneFS job engine defines two exclusion sets that govern which jobs can execute concurrently on a cluster. MultiScan straddles both of the job engine’s exclusion sets, with AutoBalance (and AutoBalanceLin) in the restripe set, and Collect in the mark set.
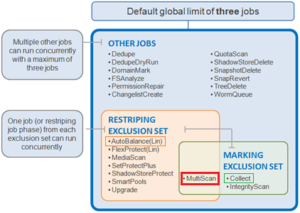
The restriping exclusion set is per-phase instead of per job, which helps to more efficiently parallelize restripe jobs when they don’t need to lock down resources. However, with the marking exclusion set, OneFS can only accommodate a single marking job at any point in time.
MultiScan is an unscheduled job that runs by default at ‘LOW’ impact and executes AutoBalance and Collect simultaneously. It is triggered by cluster group change events, which include node boot, shutdown, reboot, drive replacement, etc. While AutoBalance will execute each time the MultiScan job is triggered, Collect typically won’t be run more often that once every 2 weeks. AutoBalance and/or Collect are typically only run manually if MultiScan has been disabled.
When a new node or drive is added to the cluster, its blocks are almost entirely free, whereas the rest of the cluster is usually considerably more full, capacity-wise. AutoBalance restores the balance of free blocks in the cluster. As such, AutoBalance runs if a cluster’s nodes have a greater than 5% imbalance in capacity utilization. In addition, AutoBalance also fixes recovered writes that occurred due to transient unavailability and also addresses fragmentation.
If the cluster’s nodes contain SSDs, AutoBalanceLin (as opposed to the regular AutoBalance job) runs most efficiently by performing a LIN scan using a flash-backed metadata mirror. When a cluster is unbalanced, there is not an obvious subset of files to filter, since the files to be restriped are the ones which are not using the node or drive with less free space. In the case of an added node or drive, no files will be using it. As a result, almost any file scanned is enumerated for restripe.
As mentioned, the Collect job reclaims leaked blocks using a mark and sweep process. In traditional UNIX systems this function is typically performed by the ‘fsck’ utility. With OneFS, however, the other traditional functions of fsck are not required, since the transaction system keeps the file system consistent. Leaks only affect free space.
Collect’s ‘mark and sweep’ gets its name from the in-memory garbage collection algorithm. First, the in-use blocks and any new allocations are marked with the current generation in the Mark phase. When this is complete, the drives are swept of any blocks which don’t have the current generation in the Sweep phase.
In addition to automatic job execution following a group change event, Multiscan can also be initiated on demand. The following CLI syntax will kick off a manual job run:
# isi job start multiscan Started job [209] # isi job list ID Type State Impact Pri Phase Running Time -------------------------------------------------------- 209 MultiScan Running Low 4 1/4 1s -------------------------------------------------------- Total: 1
The Multiscan job’s progress can be tracked via a CLI command as follows:
# isi job jobs view 209 ID: 209 Type: MultiScan State: Running Impact: Low Policy: LOW Pri: 4 Phase: 1/4 Start Time: 2021-01-03T20:15:16 Running Time: 34s Participants: 1, 2, 3 Progress: Collect: 225 LINs, 0 errors AutoBalance: 225 LINs, 0 errors LIN Estimate based on LIN count of 2793 done on Jan 04 20:02:57 2021 LIN Based Estimate: 3m 2s Remaining (8% Complete) Block Based Estimate: 5m 48s Remaining (4% Complete) 0 errors total Waiting on job ID: - Description: Collect, AutoBalance
The LIN (logical inode) statistics above include both files and directories.
Be aware that the estimated LIN percentage can occasionally be misleading/anomalous. If concerned, verify that the stated total LIN count is roughly in line with the file count for the cluster’s dataset. Even if the LIN count is in doubt, the estimated block progress metric should always be accurate and meaningful.
If the job is in its early stages and no estimation can be given (yet), isi job will instead report its progress as “Started”. Note that all progress is reported per phase, with MultiScan phase 1 being the one where the lion’s share of the work is done. By comparison, phases 2-4 of the job are comparatively short.
A job’s resource usage can be traced from the CLI as such:
# isi job statistics view Job ID: 209 Phase: 1 CPU Avg.: 11.46% Memory Avg. Virtual: 301.06M Physical: 28.71M I/O Ops: 3513425 Bytes: 26.760G
Finally, upon completion, the Multiscan job report, detailing all four stages, can be viewed by using the following CLI command with the job ID as the argument:
# isi job reports view 209 MultiScan[209] phase 1 (2021-01-03T20:02:57) -------------------------------------------- Elapsed time 307 seconds (5m7s) Working time 307 seconds (5m7s) Errors 0 Rebalance/LINs 2793 Rebalance/Files 2416 Rebalance/Directories 377 Rebalance/Errors 0 Rebalance/Bytes 372607773184 bytes (347.018G) Collect/LINs 2788 Collect/Files 2411 Collect/Directories 377 Collect/Errors 0 Collect/Bytes 130187742208 bytes (121.247G) MultiScan[209] phase 2 (2021-01-03T20:02:57) -------------------------------------------- Elapsed time 0 seconds Working time 0 seconds Errors 0 LINs traversed 0 LINs processed 0 SINs traversed 0 SINs processed 0 Files seen 0 Directories seen 0 Total bytes 0 bytes MultiScan[209] phase 3 (2021-01-03T20:02:58) -------------------------------------------- Elapsed time 1 seconds Working time 1 seconds Errors 0 Rebalance/SINs 0 Rebalance/Files 0 Rebalance/Directories 0 Rebalance/Errors 0 Rebalance/Bytes 0 bytes Collect/SINs 0 Collect/Files 0 Collect/Directories 0 Collect/Errors 0 Collect/Bytes 0 bytes Unbalanced diskpools Pool_Name = h600_18tb_3.2tb-ssd_256gb:2, free_blocks = 8693136159, total_blocks = 8715355092 Pool_Name = h600_18tb_3.2tb-ssd_256gb:3, free_blocks = 7259260440, total_blocks = 7262795910 MultiScan[209] phase 4 (2021-01-03T20:03:17) -------------------------------------------- Elapsed time 19 seconds Working time 19 seconds Errors 0 Drives swept 33 LINs freed 0 Inodes freed 128359 Bytes freed 80022503424 bytes (74.527G) Keys freed 0 Inodes lost 0