A principal benefit of the OneFS distributed file system is its ability to efficiently coordinate operations that happen on separate nodes. File locking enables multiple users or processes to access data concurrently and safely. Since all nodes in an PowerScale cluster operate on the same single-namespace file system simultaneously, it requires mutual exclusion mechanisms to function correctly. For reading data, this is a fairly straightforward process involving shared locks. With writes, however, things become more complex and require exclusive locking, since data must be kept consistent.
Under the hood, the locks OneFS uses to provide consistency inside the file system (internal) are separate from the file locks provided for consistency between applications (external). This allows OneFS to reallocate a file’s metadata and data blocks while the file itself is locked by an application. This is the premise of OneFS autobalance, reprotection and tiering, where restriping is performed behind the scenes in small chunks, in order to minimize disruption.
OneFS has a fully distributed lock manager (DLM) that marshals locks across all the nodes in a cluster. This locking manager allows for multiple lock types to support both file system locks as well as cluster-coherent protocol-level locks, such as SMB share mode locks or NFS advisory-mode locks. The DLM distributes the lock data across all the nodes in the cluster. In a mixed cluster, the DLM will balance the memory utilization so that the lower-power nodes are not bullied.
OneFS includes the following lock domains:
| Lock Domain | Resource | Description |
| Advisory Lock | LIN | The advisory lock domain (advlock) implements local POSIX advisory locks and NFS NLM locks. |
| Anti-virus | LIN, snapID | The AV domain implements locks used by OneFS’ ICAP Antivirus feature. |
| Data | LIN, LBN | The datalock lock domain implements locks on regions of data within a file. By reducing the locking granularity to below the file level, this enables simultaneous writers to multiple sections of a single file. |
| Delete | LIN | The ref lock domain exists to enable POSIX delete-on-close semantics. In a POSIX filesystem, unlinking an open file does not remove the space associated with the file until every thread accessing that file closes the file. |
| ID Map | B-tree key | The idmap database contains mappings between POSIX (uid, gid) and Windows (SID) identities. This lock domain provides concurrency control for the idmap database. |
| LIN | LIN | Every object in the OneFS filesystem (file, directory, internal special LINs) is indexed by a logical inode number (LIN). A LIN provides an extra level of indirection, providing pointers to the mirrored copies of the on-disk inode. This domain is used to provide mutual exclusion around classic BSD vnode operations. Operations that require a stable view of data take a read lock which allows other readers to operate simultaneously but prevents modification. Operations that change data take a write lock that prevents others from accessing that directory while the change is taking place. |
| MDS | Lowest baddr | All metadata in the OneFS filesystem is mirrored for protection. Operations involving read/write of such metadata are protected using locks in the Mirrored Data Structure (MDS) domain. |
| Oplocks | LIN, snapID | The Oplock lock domain implements the underlying support for opportunistic locks and leases. |
| Quota | Quota Domain ID | The Quota domain is used to implement concurrency control to quota domain records. |
| Share mode | LIN, snapID | The share_mode_lock domain is used to implement the Windows share mode locks. |
| SMB byte-range (CBRL) | The cbrl lock domain implements support for byte-range locking. |
Each lock type implements a set of key/value pairs, and can additionally support a ‘byte range’, or a pair of file offsets, and a ‘user data’ block.
In addition to managing locks on files, DLM also orchestrates access to the storage drives, too. Multiple domains, advisory file locks (advlock), mirrored metadata operations (MDS locks), and logical inode number (LIN locks) for operations involving file system objects that have an inode (ie. files or directories) exist within the lock manager. Within these, LIN locks constitute the lion’s share of OneFS locking issues.
Much like OS-level locking, DLM’s operations are typically invisible to end users. That said, DLM sets a maximum time to wait to obtain a lock. When this threshold is exceeded, OneFS automatically triggers a diagnostic information-gathering process, or hang-dump. Note that the triggering of a hang-dump is not necessarily indicative of an issue, but should definitely prompt some further investigation. Hang-dumps will be covered in more depth in a forthcoming blog article in this series.
So what exactly is deadlock? When one or more processes have obtained locks on resources, a point can be reached in which each process prevents another from obtaining a lock, rendering none of the processes able to proceed. This condition is known as a deadlock.
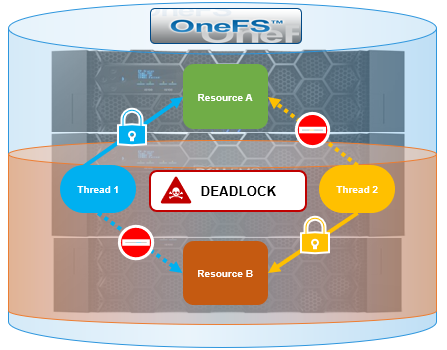
In the image above, thread 1 has an exclusive lock on Resource A, but also requires Resource B in order to complete execution. Since the Resource B lock is unavailable, thread 1 will have to wait for thread 2 to release it’s lock on Resource B. At the same time, thread 2 has obtained an exclusive lock on Resource B, but requires Resource A for finishing execution. Since the Resource A lock is unavailable, if thread 2 attempts to lock Resource A, both processes will wait indefinitely for each other.
Any multi-process file system architecture that involves locking has the potential for deadlocks if any thread needs to acquire more than one lock at the same time. There are typically two general approaches to handling this scenario:
| Option | Description |
| Avoidance | Attempt to ensure the code cannot deadlock. This approach involves mechanisms such as consistently acquiring locks in the same order. This approach is generally challenging, not always practical, and can have adverse performance implications for the fast path code. |
| Acceptance | Acknowledge that deadlocks will occur and develop appropriate handling methods. |
While OneFS ultimately takes the latter approach, it strives to ensure that deadlocks don’t occur. However, under rare conditions, it is more efficient to manage deadlocks by simply breaking and reestablishing the locks.
In OneFS parlance, a ‘hang-dump’ is a cluster event, resulting from a cluster detecting a ‘hang’ condition, during which the isi_hangdump_d service generates a set of log files. This typically occurs as a result of merge lock timeouts and deadlocks, and while hang-dumps are typically triggered automatically, they can also be manually initiated if desired.
OneFS monitors each lock domain and has a built-in ‘soft timeout’ (the amount of time in which OneFS can generally be expected to satisfy a lock request) associated with each. If a thread holding a lock blocks another thread’s attempt to obtain a conflicting lock type for longer than the soft timeout period, a hang-dump is triggered to collect a substantial quantity of system state information for potential diagnostic purposes, including the lock state of each domain, plus the stack traces of every thread on each node in the cluster.
When a thread is blocked for an extended period of time, any client that is waiting for the work that the thread is performing is also blocked. The external symptoms resulting from this can include:
- Open applications stop taking input but do not shut down.
- Open windows or dialogues cannot be closed.
- The system cannot be restarted normally because it does not respond to commands.
- A node does not respond to client requests.
Hang-dumps can occur as a result of the following conditions:
| Type | Description |
| Transient | The time to obtain the lock was long enough to trigger a hang-dump, but the lock is eventually granted. This is the less serious situation. The symptoms are typically general performance degradation, but the cluster is still responsive and able to progress. |
| Persistent | The issue typically requires impactful remedial action, such as node reboots. This is usually indicative of either a defect or bug in OneFS or hardware issue, where a cluster component becomes unresponsive, and OneFS waits indefinitely for it to recover. |
Note that a OneFS hang-dump is not necessarily indicative of a serious issue.