The earlier blog post on multi-threaded I/O generated several questions on synchronous writes in OneFS. So this seemed like a useful topic to explore in a bit more detail.
OneFS natively provides a caching mechanism for synchronous writes – or writes that require a stable write acknowledgement to be returned to a client. This functionality is known as the Endurant Cache, or EC.
The EC operates in conjunction with the OneFS write cache, or coalescer, to ingest, protect and aggregate small, synchronous NFS writes. The incoming write blocks are staged to NVRAM, ensuring the integrity of the write, even during the unlikely event of a node’s power loss. Furthermore, EC also creates multiple mirrored copies of the data, further guaranteeing protection from single node and, if desired, multiple node failures.
EC improves the latency associated with synchronous writes by reducing the time to acknowledgement back to the client. This process removes the Read-Modify-Write (R-M-W) operations from the acknowledgement latency path, while also leveraging the coalescer to optimize writes to disk. EC is also tightly coupled with OneFS’ multi-threaded I/O (Multi-writer) process, to support concurrent writes from multiple client writer threads to the same file. And the design of EC ensures that the cached writes do not impact snapshot performance.
The endurant cache uses write logging to combine and protect small writes at random offsets into 8KB linear writes. To achieve this, the writes go to special mirrored files, or ‘Logstores’. The response to a stable write request can be sent once the data is committed to the logstore. Logstores can be written to by several threads from the same node, and are highly optimized to enable low-latency concurrent writes.
Note that if a write uses the EC, the coalescer must also be used. If the coalescer is disabled on a file, but EC is enabled, the coalescer will still be active with all data backed by the EC.
So what exactly does an endurant cache write sequence look like?
Say an NFS client wishes to write a file to an Isilon cluster over NFS with the O_SYNC flag set, requiring a confirmed or synchronous write acknowledgement. Here is the sequence of events that occur to facilitate a stable write.
1) A client, connected to node 3, begins the write process sending protocol level blocks. 4K is the optimal block size for the endurant cache.
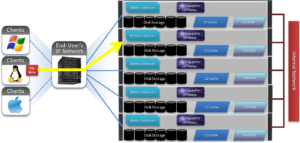
2) The NFS client’s writes are temporarily stored in the write coalescer portion of node 3’s RAM. The Write Coalescer aggregates uncommitted blocks so that the OneFS can, ideally, write out full protection groups where possible, reducing latency over protocols that allow “unstable” writes. Writing to RAM has far less latency that writing directly to disk.
3) Once in the write coalescer, the endurant cache log-writer process writes mirrored copies of the data blocks in parallel to the EC Log Files.
The protection level of the mirrored EC log files is the same as that of the data being written by the NFS client.
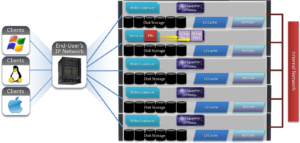
4) When the data copies are received into the EC Log Files, a stable write exists and a write acknowledgement (ACK) is returned to the NFS client confirming the stable write has occurred. The client assumes the write is completed and can close the write session.
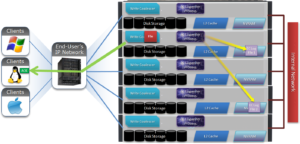
5) The write coalescer then processes the file just like a non-EC write at this point. The write coalescer fills and is routinely flushed as required as an asynchronous write via to the block allocation manager (BAM) and the BAM safe write (BSW) path processes.
6) The file is split into 128K data stripe units (DSUs), parity protection (FEC) is calculated and FEC stripe units (FSUs) are created.
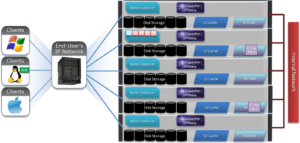
7) The layout and write plan is then determined, and the stripe units are written to their corresponding nodes’ L2 Cache and NVRAM. The EC logfiles are cleared from NVRAM at this point. OneFS uses a Fast Invalid Path process to de-allocate the EC Log Files from NVRAM.
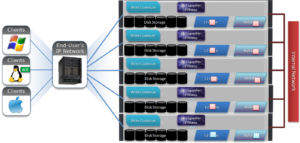
8) Stripe Units are then flushed to physical disk.
9) Once written to physical disk, the data stripe Unit (DSU) and FEC stripe unit (FSU) copies created during the write are cleared from NVRAM but remain in L2 cache until flushed to make room for more recently accessed data.
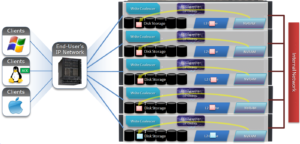
As far as protection goes, the number of logfile mirrors created by EC is always one more than the on-disk protection level of the file. For example:
| File Protection Level | Number of EC Mirrored Copies |
| +1n | 2 |
| 2x | 3 |
| +2n | 3 |
| +2d:1n | 3 |
| +3n | 4 |
| +3d:1n | 4 |
| +4n | 5 |
The EC mirrors are only used if the initiator node is lost. In the unlikely event that this occurs, the participant nodes replay their EC journals and complete the writes.
If the write is an EC candidate, the data remains in the coalescer, an EC write is constructed, and the appropriate coalescer region is marked as EC. The EC write is a write into a logstore (hidden mirrored file) and the data is placed into the journal.
Assuming the journal is sufficiently empty, the write is held there (cached) and only flushed to disk when the journal is full, thereby saving additional disk activity.
An optimal workload for EC involves small-block synchronous, sequential writes – something like an audit or redo log, for example. In that case, the coalescer will accumulate a full protection group’s worth of data and be able to perform an efficient FEC write.
The happy medium is a synchronous small block type load, particularly where the I/O rate is low and the client is latency-sensitive. In this case, the latency will be reduced and, if the I/O rate is low enough, it won’t create serious pressure.
The undesirable scenario is when the cluster is already spindle-bound and the workload is such that it generates a lot of journal pressure. In this case, EC is just going to aggravate things.
So how exactly do you configure the endurant cache?
Although on by default, setting the efs.bam.ec.mode sysctl to value ‘1’ will enable the Endurant Cache:
# isi_sysctl_cluster efs.bam.ec.mode=1
EC can also be enabled & disabled per directory:
# isi set -c [on|off|endurant_all|coal_only] <directory_name>
To enable the coalescer but switch of EC, run:
# isi set -c coal_only
And to disable the endurant cache completely:
# isi_for_array –s isi_sysctl_cluster efs.bam.ec.mode=0
A return value of zero on each node from the following command will verify that EC is disabled across the cluster:
# isi_for_array –s sysctl efs.bam.ec.stats.write_blocks efs.bam.ec.stats.write_blocks: 0
If the output to this command is incrementing, EC is delivering stable writes.
Be aware that if the Endurant Cache is disabled on a cluster the sysctl efs.bam.ec.stats.write_blocks output on each node will not return to zero, since this sysctl is a counter, not a rate. These counters won’t reset until the node is rebooted.
As mentioned previously, EC applies to stable writes. Namely:
- Writes with O_SYNC and/or O_DIRECT flags set
- Files on synchronous NFS mounts
When it comes to analyzing any performance issues involving EC workloads, consider the following:
- What changed with the workload?
- If upgrading OneFS, did the prior version also have EC enable?
- If the workload has moved to new cluster hardware:
- Does the performance issue occur during periods of high CPU utilization?
- Which part of the workload is creating a deluge of stable writes?
- Was there a large change in spindle or node count?
- Has the OneFS protection level changed?
- Is the SSD strategy the same?
Disabling EC is typically done cluster-wide and this can adversely impact certain workflow elements. If the EC load is localized to a subset of the files being written, an alternative way to reduce the EC heat might be to disable the coalescer buffers for some particular target directories, which would be a more targeted adjustment. This can be configured via the isi set –c off command.
One of the more likely causes of performance degradation is from applications aggressively flushing over-writes and, as a result, generating a flurry of ‘commit’ operations. This can generate heavy read/modify/write (r-m-w) cycles, inflating the average disk queue depth, and resulting in significantly slower random reads. The isi statistics protocol CLI command output will indicate whether the ‘commit’ rate is high.
It’s worth noting that synchronous writes do not require using the NFS ‘sync’ mount option. Any programmer who is concerned with write persistence can simply specify an O_FSYNC or O_DIRECT flag on the open() operation to force synchronous write semantics for that fie handle. With Linux, writes using O_DIRECT will be separately accounted-for in the Linux ‘mountstats’ output. Although it’s almost exclusively associated with NFS, the EC code is actually protocol-agnostic. If writes are synchronous (write-through) and are either misaligned or smaller than 8k, they have the potential to trigger EC, regardless of the protocol.
The endurant cache can provide a significant latency benefit for small (eg. 4K), random synchronous writes – albeit at a cost of some additional work for the system.
However, it’s worth bearing the following caveats in mind:
- EC is not intended for more general purpose I/O.
- There is a finite amount of EC available. As load increases, EC can potentially ‘fall behind’ and end up being a bottleneck.
- Endurant Cache does not improve read performance, since it’s strictly part of the write process.
- EC will not increase performance of asynchronous writes – only synchronous writes.