OneFS run equally across all the nodes in a cluster such that no one node controls the cluster and all nodes are true peers. Looking from a high-level at the components within each node, the I/O stack is split into a top layer, or initiator, and a bottom layer, or participant. This division is used as a logical model for the analysis of OneFS’ read and write paths.
At a physical-level, CPUs and memory cache in the nodes are simultaneously handling initiator and participant tasks for I/O taking place throughout the cluster. There are caches and a distributed lock manager that are excluded from the diagram below for simplicity’s sake.
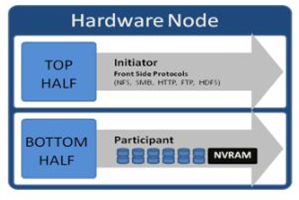
When a client connects to a node to write a file, it is connecting to the top half or initiator of that node. Files are broken into smaller logical chunks called stripes before being written to the bottom half or participant of a node (disk). Failure-safe buffering using a write coalescer is used to ensure that writes are efficient and read-modify-write operations are avoided. The size of each file chunk is referred to as the stripe unit size. OneFS stripes data across all nodes and protects the files, directories and associated metadata via software erasure-code or mirroring.
OneFS determines the appropriate data layout to optimize for storage efficiency and performance. When a client connects to a node, that node’s initiator acts as the ‘captain’ for the write data layout of that file. Data, erasure code (FEC) protection, metadata and inodes are all distributed on multiple nodes, and spread across multiple drives within nodes. The following illustration shows a file write occurring across all nodes in a three node cluster.
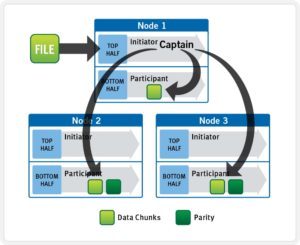
OneFS uses a cluster’s Ethernet or Infiniband back-end network to allocate and automatically stripe data across all nodes . As data is written, it’s also protected at the specified level.
When writes take place, OneFS divides data out into atomic units called protection groups. Redundancy is built into protection groups, such that if every protection group is safe, then the entire file is safe. For files protected by FEC, a protection group consists of a series of data blocks as well as a set of parity blocks for reconstruction of the data blocks in the event of drive or node failure. For mirrored files, a protection group consists of all of the mirrors of a set of blocks.
OneFS is capable of switching the type of protection group used in a file dynamically, as it is writing. This allows the cluster to continue without blocking in situations when temporary node failure prevents the desired level of parity protection from being applied. In this case, mirroring can be used temporarily to allow writes to continue. When nodes are restored to the cluster, these mirrored protection groups are automatically converted back to FEC protected.
During a write, data is broken into stripe units and these are spread across multiple nodes as a protection group. As data is being laid out across the cluster, erasure codes or mirrors, as required, are distributed within each protection group to ensure that files are protected at all times.
One of the key functions of the OneFS AutoBalance job is to reallocate and balance data and, where possible, make storage space more usable and efficient. In most cases, the stripe width of larger files can be increased to take advantage of new free space, as nodes are added, and to make the on-disk layout more efficient.
The initiator top half of the ‘captain’ node uses a modified two-phase commit (2PC) transaction to safely distribute writes across the cluster, as follows:
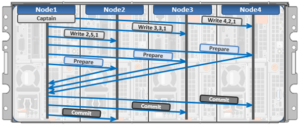
Every node that owns blocks in a particular write operation is involved in a two-phase commit mechanism, which relies on NVRAM for journaling all the transactions that are occurring across every node in the storage cluster. Using multiple nodes’ NVRAM in parallel allows for high-throughput writes, while maintaining data safety against all manner of failure conditions, including power failures. In the event that a node should fail mid-transaction, the transaction is restarted instantly without that node involved. When the node returns, it simply replays its journal from NVRAM.
In a write operation, the initiator also orchestrates the layout of data and metadata, the creation of erasure codes, and lock management and permissions control. OneFS can also optimize layout decisions made by to better suit the workflow. These access patterns, which can be configured at a per-file or directory level, include:
- Concurrency: Optimizes for current load on the cluster, featuring many simultaneous clients.
- Streaming: Optimizes for high-speed streaming of a single file, for example to enable very fast reading with a single client.
- Random: Optimizes for unpredictable access to the file, by adjusting striping and disabling the use of prefetch.