Received several comments on the previous post requesting more background information on the Job Engine. So, over the next few blog articles, we’ll try to remedy this by delving into its architecture, idiosyncrasies, and operation.
The OneFS Job Engine runs across the entire cluster and is responsible for dividing and conquering large storage management and protection tasks. To achieve this, it reduces a task into smaller work items and then allocates, or maps, these portions of the overall job to multiple worker threads on each node. Progress is tracked and reported on throughout job execution and a detailed report and status is presented upon completion or termination.
Job Engine includes a comprehensive check-pointing system which allows jobs to be paused and resumed, in addition to stopped and started. It also includes an adaptive impact management system, CPU and drive-sensitive impact control, and the ability to run multiple jobs at once.
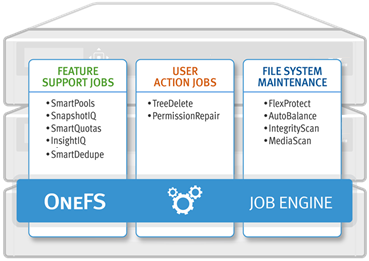
The Job Engine typically executes jobs as background tasks across the cluster, using spare or especially reserved capacity and resources. The jobs themselves can be categorized into three primary classes:
| Category | Description |
| File System Maintenance Jobs | These jobs perform background file system maintenance, and typically require access to all nodes. These jobs are required to run in default configurations, and often in degraded cluster conditions. Examples include file system protection and drive rebuilds. |
| Feature Support Jobs | The feature support jobs perform work that facilitates some extended storage management function, and typically only run when the feature has been configured. Examples include deduplication and anti-virus scanning. |
| User Action Jobs | These jobs are run directly by the storage administrator to accomplish some data management goal. Examples include parallel tree deletes and permissions maintenance. |
Although the file system maintenance jobs are run by default, either on a schedule or in reaction to a particular file system event, any Job Engine job can be managed by configuring both its priority-level (in relation to other jobs) and its impact policy. These are covered in more detail below.
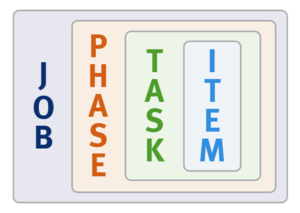
Job Engine jobs often comprise several phases, each of which are executed in a pre-defined sequence. These run the gamut from jobs like TreeDelete, which have just a single phase, to complex jobs like FlexProtect and MediaScan that have multiple distinct phases.
A job phase must be completed in entirety before the job can progress to the next phase. If any errors occur during execution, the job is marked “failed” at the end of that particular phase and the job is terminated.
Each job phase is composed of a number of work chunks, or Tasks. Tasks, which are comprised of multiple individual work items, are divided up and load balanced across the nodes within the cluster. Successful execution of a work item produces an item result, which might contain a count of the number of retries required to repair a file, plus any errors that occurred during processing.
When a Job Engine job needs to work on a large portion of the file system, there are four main methods available to accomplish this:
- Inode (LIN) Scan
- Tree Walk
- Drive Scan
- Changelist
The most straightforward access method is via metadata, using a Logical Inode (LIN) Scan. In addition to being simple to access in parallel, LINs also provide a useful way of accurately determining the amount of work required.
A directory tree walk is the traditional access method since it works similarly to common UNIX utilities, such as find – albeit in a far more distributed way. For parallel execution, the various job tasks are each assigned a separate subdirectory tree. Unlike LIN scans, tree walks may prove to be heavily unbalanced, due to varying sub-directory depths and file counts.
Disk drives provide excellent linear read access, so a drive scan can deliver orders of magnitude better performance than a directory tree walk or LIN scan for jobs that don’t require insight into file system structure. As such, drive scans are ideal for jobs like MediaScan, which linearly traverses each node’s disks looking for bad disk sectors.
A fourth class of Job Engine jobs utilize a ‘changelist’, rather than LIN-based scanning. The changelist approach analyzes two snapshots to find the LINs which changed (delta) between the snapshots, and then dives in to determine the exact changes.
The following table provides a comprehensive list of the exposed jobs and operations that the OneFS Job Engine performs, and their file system access methods:
| Job Name | Job Description | Access Method |
| AutoBalance | Balances free space in the cluster. | Drive + LIN |
| AutoBalanceLin | Balances free space in the cluster. | LIN |
| AVScan | Virus scanning job that antivirus server(s) run. | Tree |
| ChangelistCreate | Create a list of changes between two consecutive SyncIQ snapshots | Changelist |
| CloudPoolsLin | Archives data out to a cloud provider according to a file pool policy. | LIN |
| CloudPoolsTreewalk | Archives data out to a cloud provider according to a file pool policy. | Tree |
| Collect | Reclaims disk space that could not be freed due to a node or drive being unavailable while they suffer from various failure conditions. | Drive + LIN |
| ComplianceStoreDelete | SmartLock Compliance mode garbage collection job. | Tree |
| Dedupe | Deduplicates identical blocks in the file system. | Tree |
| DedupeAssessment | Dry run assessment of the benefits of deduplication. | Tree |
| DomainMark | Associates a path and its contents with a domain. | Tree |
| DomainTag | Associates a path and its contents with a domain. | Tree |
| EsrsMftDownload | ESRS managed file transfer job for license files. | |
| FilePolicy | Efficient SmartPools file pool policy job. | Changelist |
| FlexProtect | Rebuilds and re-protects the file system to recover from a failure scenario. | Drive + LIN |
| FlexProtectLin | Re-protects the file system. | LIN |
| FSAnalyze | Gathers file system analytics data that is used in conjunction with InsightIQ. | Changelist |
| IndexUpdate | Creates and updates an efficient file system index for FilePolicy and FSAnalyze jobs, | Changelist |
| IntegrityScan | Performs online verification and correction of any file system inconsistencies. | LIN |
| LinCount | Scans and counts the file system logical inodes (LINs). | LIN |
| MediaScan | Scans drives for media-level errors. | Drive + LIN |
| MultiScan | Runs Collect and AutoBalance jobs concurrently. | LIN |
| PermissionRepair | Correct permissions of files and directories. | Tree |
| QuotaScan | Updates quota accounting for domains created on an existing directory path. | Tree |
| SetProtectPlus | Applies the default file policy. This job is disabled if SmartPools is activated on the cluster. | LIN |
| ShadowStoreDelete | Frees space associated with a shadow store. | LIN |
| ShadowStoreProtect | Protect shadow stores which are referenced by a LIN with higher requested protection. | LIN |
| ShadowStoreRepair | Repair shadow stores. | LIN |
| SmartPools | Job that runs and moves data between the tiers of nodes within the same cluster. Also executes the CloudPools functionality if licensed and configured. | LIN |
| SmartPoolsTree | Enforce SmartPools file policies on a subtree. | Tree |
| SnapRevert | Reverts an entire snapshot back to head. | LIN |
| SnapshotDelete | Frees disk space that is associated with deleted snapshots. | LIN |
| TreeDelete | Deletes a path in the file system directly from the cluster itself. | Tree |
| Undedupe | Removes deduplication of identical blocks in the file system. | Tree |
| Upgrade | Upgrades cluster on a later OneFS release. | Tree |
| WormQueue | Scan the SmartLock LIN queue | LIN |
Note that there are also a few background Job Engine jobs, such as the Upgrade job, which are not exposed to administrative control.
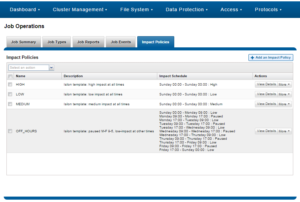
A job impact policy can consist of one or many impact intervals, which are blocks of time within a given week. Each impact interval can be configured to use a single, pre-defined impact-level which specifies the amount of cluster resources to use for a particular cluster operation. The available impact-levels are:
- Paused
- Low
- Medium
- High
This degree of granularity allows impact intervals and levels to be configured per job, in order to ensure smooth cluster operation. And the resulting impact policies dictate when a job runs and the resources that a job can consume. The following default job engine impact policies are provided:
| Impact policy | Schedule | Impact Level |
| LOW | Any time of day | Low |
| MEDIUM | Any time of day | Medium |
| HIGH | Any time of day | High |
| OFF_HOURS | Outside of business hours (9AM to 5PM, Mon to Fri), paused during business hours | Low |
Be aware that these default impact policies cannot be modified or deleted.
However, new impact policies can be created, either via the “Add an Impact Policy” WebUI button, or by cloning a default policy and then modifying its settings as appropriate.
A mix of jobs with different impact levels will result in resource sharing. Each job cannot exceed the impact levels set for it, and the aggregate impact level cannot exceed the highest level of the individual jobs.
For example:
- Job A (HIGH), job B (LOW).
The impact level of job A is HIGH.
The impact level of job B is LOW.
The total impact level of the two jobs combined is HIGH.
- Job A (MEDIUM), job B (LOW), job C (MEDIUM).
The impact level of job A is MEDIUM.
The impact level of job B is LOW.
The impact level of job C is MEDIUM.
The total impact level of the three jobs combined is MEDIUM.
- Job A (LOW), job B (LOW), job C (LOW), job D (LOW).
The impact level of job A is LOW.
The impact level of job B is LOW.
The impact level of job C is LOW.
The impact level of job D is LOW.
The job that was most recently queued/paused, or has the highest job ID value, will be paused.
The total impact level of the three running jobs, and one paused job, combined is LOW.
A best practice is to keep the default impact and priority settings, where possible, unless there’s a valid reason to change them.
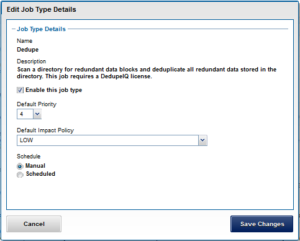
The majority of Job Engine jobs are intended to run with “LOW” impact and execute in the background. Notable exceptions are the FlexProtect jobs, which by default are set at “medium” impact. This allows FlexProtect to quickly and efficiently re-protect data, without critically impacting other user activities.
Job Engine jobs are prioritized on a scale of one to ten, with a lower value signifying a higher priority. This is similar in concept to the UNIX scheduling utility, ‘nice’.
Higher priority jobs always cause lower-priority jobs to be paused, and, if a job is paused, it is returned to the back of the Job Engine priority queue. When the job reaches the front of the priority queue again, it resumes from where it left off. If the system schedules two jobs of the same type and priority level to run simultaneously, the job that was queued first is run first.
Priority takes effect when two or more queued jobs belong to the same exclusion set, or when, if exclusion sets are not a factor, four or more jobs are queued. The fourth queued job may be paused, if it has a lower priority than the three other running jobs.
In contrast to priority, job impact policy only comes into play once a job is running and determines the amount of resources a job can utilize across the cluster. As such, a job’s priority and impact policy are orthogonal to one another.
The FlexProtect(LIN) and IntegrityScan jobs both have the highest job engine priority level of 1, by default. Of these, FlexProtect is the most important, because of its core role in re-protecting data.
All the Job Engine jobs’ priorities are configurable by the cluster administrator. The default priority settings are strongly recommended, particularly for the highest priority jobs mentioned above.
As we saw in the previous blog article, the OneFS Job Engine allows up to three jobs to be run simultaneously. This concurrent job execution is governed by the following criteria:
- Job Priority
- Exclusion Sets – jobs which cannot run together (ie, FlexProtect and AutoBalance)
- Cluster health – most jobs cannot run when the cluster is in a degraded state.