Got asked the following question from the field recently:
“I kicked off a job on my cluster which seemed to be running happily. When I went back into the UI to check it had stopped and was marked waiting and wouldn’t restart.”
Situations like this occur when a running lower priority job is trumped by higher priority job(s). Since the OneFS Job Engine only allows up to three jobs to be run simultaneously, if a fourth job with a higher priority is started, the lowest of the currently executing jobs will be paused. For example:
# isi job start fsanalyze Started job [583] # isi job status The job engine is running. Running and queued jobs: ID Type State Impact Pri Phase Running Time --------------------------------------------------------- 578 SmartPools Running Low 6 1/2 11s 581 Collect Running Low 4 1/3 16s 583 FSAnalyze Running Low 5 1/10 1s --------------------------------------------------------- Total: 3
In this case, we have three jobs running: SmartPools with a priority of 6, MultiScan with priority 4, and FSAnalyze with priority 5.
Next, we go ahead and start a deduplication job, with a priority value of 4:
# isi job start dedupe Started job [584]
If we now take a look at the cluster’s job status, we can see that SmartPools job has been put into a waiting state (paused), because of its relative priority. A value of ‘1’ indicates the highest priority job level that OneFS supports, with ‘10’ being the lowest.
# isi job status The job engine is running. Running and queued jobs: ID Type State Impact Pri Phase Running Time --------------------------------------------------------- 578 SmartPools Waiting Low 6 1/2 11s 581 Collect Running Low 4 1/3 1m 4s 583 FSAnalyze Running Low 5 9/10 43s 584 Dedupe Running Low 4 1/1 - --------------------------------------------------------- Total: 4
Once the FSAnalyze job has completed, the SmartPools job is automatically restarted again:
# isi job status The job engine is running. Running and queued jobs: ID Type State Impact Pri Phase Running Time --------------------------------------------------------- 578 SmartPools Running Low 6 1/2 23s 581 Collect Running Low 4 1/3 5m 9s 584 Dedupe Running Low 4 1/1 1m 2s --------------------------------------------------------- Total: 3
Let’s look at this in a bit more detail. So the Job Engine’s concurrent job execution is governed by the following criteria:
- Job Priority
- Exclusion Sets – jobs which cannot run together (ie, FlexProtect and AutoBalance)
- Cluster health – most jobs cannot run when the cluster is in a degraded state.
In addition to the per-job impact controls described above, additional impact management is also provided by the notion of job exclusion sets. For multiple concurrent job execution, exclusion sets, or classes of similar jobs, determine which jobs can run simultaneously. A job is not required to be part of any exclusion set, and jobs may also belong to multiple exclusion sets.
Currently, there are two exclusion sets that jobs can be part of: Restriping and Marking:
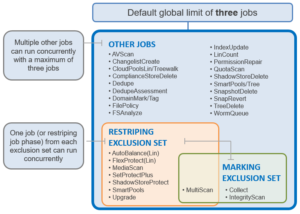
Here’s a list of the basic concurrent job combinations that OneFS supports:
- 1 Restripe Job + 1 Mark Job + 1 Other Job
- 1 Restripe Job + 2 Other Jobs
- 1 Mark Job + 2 Other Jobs
- 1 Mark and Restripe Job + 2 Other Jobs
- 3 Other Jobs
OneFS marks blocks that are actually in use by the file system. IntegrityScan, for example, traverses the live file system, marking every block of every LIN in the cluster to proactively detect and resolve any issues with the structure of data in a cluster. The jobs that comprise the marking exclusion set are:
- Collect
- IntegrityScan
- MultiScan
OneFS protects data by writing file blocks across multiple drives on different nodes in a process known as ‘restriping’. The Job Engine defines a restripe exclusion set that contains these jobs which involve file system management, protection and on-disk layout. The restripe exclusion set contains the following jobs:
- AutoBalance
- AutoBalanceLin
- FlexProtect
- FlexProtectLin
- MediaScan
- MultiScan
- SetProtectPlus
- ShadowStoreProtect
- SmartPools
- Upgrade
The restriping exclusion set is per-phase instead of per job. This helps to more efficiently parallelize restripe jobs when they don’t need to lock down resources.
Restriping jobs only block each other when the current phase may perform restriping. This is most evident with MultiScan, whose final phase only sweeps rather than restripes. Similarly, MediaScan, which rarely ever restripes, is usually able to run to completion more without contending with other restriping jobs.
For example, below the two restripe jobs, MediaScan and AutoBalanceLin, are both running their respective first job phases. ShadowStoreProtect, also a restriping job, is in a ‘waiting’ state, blocked by AutoBalanceLin.
Running and queued jobs: ID Type State Impact Pri Phase Running Time ---------------------------------------------------------------------- 26850 AutoBalanceLin Running Low 4 1/3 20d 18h 19m 26910 ShadowStoreProtect Waiting Low 6 1/1 - 28133 MediaScan Running Low 8 1/8 1d 15h 37m ----------------------------------------------------------------------
MediaScan restripes in phases 3 and 5 of the job, and only if there are disk errors (ECCs) which require data reprotection. If MediaScan reaches phase 3 with ECCs, it will pause until AutoBalanceLin is no longer running. If MediaScan’s priority were in the range 1-3, it would cause AutoBalanceLin to pause instead.
If two jobs happen to reach their restriping phases simultaneously and the jobs have different priorities, the higher priority job (ie. priority value closer to “1”) will continue to run, and the other will pause. If the two jobs have the same priority, the one already in its restriping phase will continue to run, and the one newly entering its restriping phase will pause.
Jobs may also belong to both exclusion sets. An example of this is MultiScan, since it includes both AutoBalance and Collect.
The majority of the jobs do not belong to an exclusion set, as illustrated in the following graphic. These are typically the feature support jobs, as described above, and they can coexist and contend with any of the other jobs.
Exclusion sets do not change the scope of the individual jobs themselves, so any runtime improvements via parallel job execution are the result of job management and impact control. The Job Engine monitors node CPU load and drive I/O activity per worker thread every twenty seconds to ensure that maintenance jobs do not cause cluster performance problems.
If a job affects overall system performance, Job Engine reduces the activity of maintenance jobs and yields resources to clients. Impact policies limit the system resources that a job can consume and when a job can run. You can associate jobs with impact policies, ensuring that certain vital jobs always have access to system resources.
Looking at our previous example again, where the SmartPools job is paused when FSAnalyze is running:
# isi job list ID Type State Impact Pri Phase Running Time --------------------------------------------------------- 578 SmartPools Waiting Low 6 1/2 15s 581 Collect Running Low 4 1/3 37m 584 Dedupe Running Low 4 1/1 33m 586 FSAnalyze Running Low 5 1/10 9s --------------------------------------------------------- Total: 4
If this is undesirable, FSAnalyze can be manually paused, to allow SmartPools to run unimpeded:
# isi job pause FSAnalyze # isi job list ID Type State Impact Pri Phase Running Time ------------------------------------------------------------- 578 SmartPools Waiting Low 6 1/2 15s 581 Collect Running Low 4 1/4 38m 584 Dedupe Running Low 4 1/1 34m 586 FSAnalyze User Paused Low 5 1/10 20s ------------------------------------------------------------- Total: 4
Alternatively, the priority of the SmartPools job can also be elevated to value ‘4’ (or the priority of FSAnalyze lowered to value ‘7’) to permanently prioritize it over the FSAnalyze job. For example:
# isi job types modify SmartPools --priority 4 Are you sure you want to modify the job type SmartPools? (yes/[no]): yes # isi job types view SmartPools ID: SmartPools Description: Enforce SmartPools file policies. This job requires a SmartPools license. Enabled: Yes Policy: LOW Schedule: every day at 22:00 Priority: 4
Or, via the WebUI:
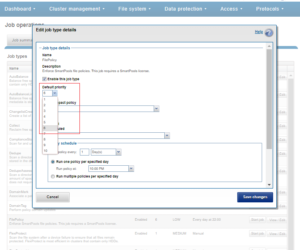
Navigate to Job Operations > Job Type and configure the desired priority value edit the appropriate job type’s details: