There have been a couple of recent inquiries from the field about the SnapRevert job.
For context, SnapRevert is one of three main methods for restoring data from a OneFS snapshot. The options are:
| Method | Description |
| Copy | Copying specific files and directories directly from the snapshot |
| Clone | Cloning a file from the snapshot |
| Revert | Reverting the entire snapshot via the SnapRevert job |
Copying a file from a snapshot duplicates that file, which roughly doubles the amount of storage space it consumes. Even if the original file is deleted from HEAD, the copy of that file will remain in the snapshot. Cloning a file from a snapshot also duplicates that file. Unlike a copy, however, a clone does not consume any additional space on the cluster – unless either the original file or clone is modified.
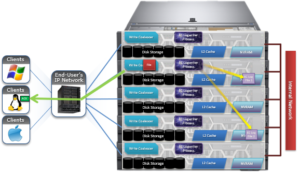
However, the most efficient of these approaches is the SnapRevert job, which automates the restoration of an entire snapshot to its top level directory. This allows for quickly reverting to a previous, known-good recovery point – for example in the event of virus outbreak. The SnapRevert job can be run from the Job Engine WebUI, and requires adding the desired snapshot ID.
There are two main components to SnapRevert:
- The file system domain that the objects are put into.
- The job that reverts everything back to what’s in a snapshot.
So what exactly is a SnapRevert domain? At a high level, a domain defines a set of behaviors for a collection of files under a specified directory tree. The SnapRevert domain is described as a ‘restricted writer’ domain, in OneFS parlance. Essentially, this is a piece of extra filesystem metadata and associated locking that prevents a domain’s files being written to while restoring a last known good snapshot.
Because the SnapRevert domain is essentially just a metadata attribute placed onto a file/directory, a best practice is to create the domain before there is data. This avoids having to wait for DomainMark (the aptly named job that marks a domain’s files) to walk the entire tree, setting that attribute on every file and directory within it.
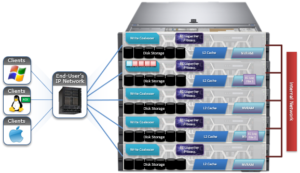
The SnapRevert job itself actually uses a local SyncIQ policy to copy data out of the snapshot, discarding any changes to the original directory. When the SnapRevert job completes, the original data is left in the directory tree. In other words, after the job completes, the file system (HEAD) is exactly as it was at the point in time that the snapshot was taken. The LINs for the files/directories don’t change, because what’s there is not a copy.
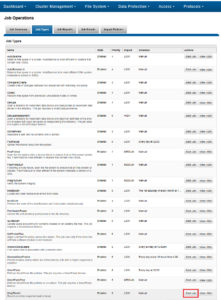
SnapRevert can be manually run from the OneFS WebUI by navigating to Cluster Management > Job Operations > Job Types > SnapRevert and clicking the ‘Start Job’ button.
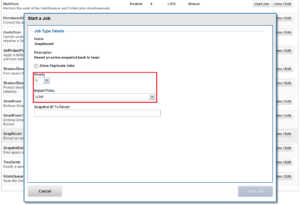
Additionally, the job’s impact policy and relative priority can also be adjusted, if desired:
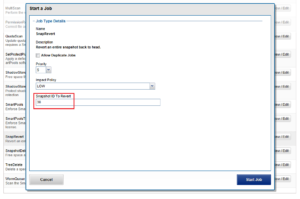
Before a snapshot is reverted, SnapshotIQ creates a point-in-time copy of the data that is being replaced. This enables the snapshot revert to be undone later, if necessary.
Additionally, individual files, rather than entire snapshots, can also be restored in place using the isi_file_revert command line utility.
# isi_file_revert usage: isi_file_revert -l lin -s snapid isi_file_revert -p path -s snapid -d (debug output) -f (force, no confirmation)
This can help drastically simplify virtual machine management and recovery, for example.
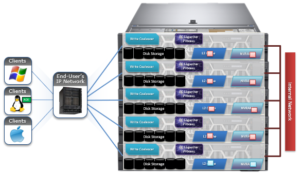
Before creating snapshots, it’s worth considering that reverting a snapshot requires that a SnapRevert domain exist for the directory that is being restored. As such, it is recommended that you create SnapRevert domains for those directories while the directories are empty. Creating a domain for an empty (or sparsely populated) directory takes considerably less time.
Files may belong to multiple domains. Each file stores a set of domain IDs indicating which domain they belong to in their inode’s extended attributes table. Files inherit this set of domain IDs from their parent directories when they are created or moved. The domain IDs refer to domain settings themselves, which are stored in a separate system B-tree. These B-tree entries describe the type of the domain (flags), and various other attributes.
As mentioned, a Restricted-Write domain prevents writes to any files except by threads that are granted permission to do so. A SnapRevert domain that does not currently enforce Restricted-Write shows up as “(Writable)” in the CLI domain listing.
Occasionally, a domain will be marked as “(Incomplete)”. This means that the domain will not enforce its specified behavior. Domains created by job engine are incomplete if not all of the files that are part of the domain are marked as being members of that domain. Since each file contains a list of domains of which it is a member, that list must be kept up to date for each file. The domain is incomplete until each file’s domain list is correct.
In addition to SnapRevert, OneFS also currently uses domains for SyncIQ replication and SnapLock immutable archiving.
A SnapRevert domain needs to be created on a directory before it can be reverted to a particular point in time snapshot. As mentioned before, the recommendation is to create SnapRevert domains for a directory while the directory is empty.
The root path of the SnapRevert domain must be the same root path of the snapshot. For example, a domain with a root path of /ifs/data/marketing cannot be used to revert a snapshot with a root path of /ifs/data/marketing/archive.
For example, for snaphsot DailyBackup_04-27-2021_12:00 which is rooted at /ifs/data/marketing/archive:
- First, set the SnapRevert domain by running the DomainMark job (which marks all the files):
# isi job jobs start domainmark --root /ifs/data/marketing --dm-type SnapRevert
- Verify that the domain has been created:
# isi_classic domain list –l
In order to restore a directory back to the state it was in at the point in time when a snapshot was taken, you need to:
- Create a SnapRevert domain for the directory.
- Create a snapshot of a directory.
To accomplish this:
- First, identify the ID of the snapshot you want to revert by running the isi snapshot snapshots view command and picking your PIT (point in time).
For example:
# isi snapshot snapshots view DailyBackup_04-27-2021_12:00 ID: 38 Name: DailyBackup_04-27-2021_12:00 Path: /ifs/data/marketing Has Locks: No Schedule: daily Alias: - Created: 2021-04-27T12:00:05 Expires: 2021-08-26T12:00:00 Size: 0b Shadow Bytes: 0b % Reserve: 0.00% % Filesystem: 0.00% State: active
- Revert to a snapshot by running the isi job jobs start command. The following command reverts to snapshot ID 38 named DailyBackup_04-27-2021_12:00:
# isi job jobs start snaprevert --snapid 38
This can also be done from the WebUI, by navigating to Cluster Management > Job Operations > Job Types > SnapRevert and clicking the ‘Start Job’ button.
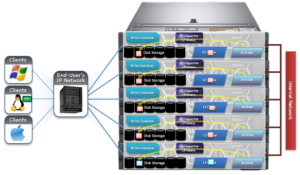
OneFS automatically creates a snapshot right before the SnapRevert process reverts the specified directory tree. The naming convention for these snapshots is of the form: <snapshot_name>.pre_revert.*
# isi snap snap list | grep pre_revert 39 DailyBackup_04-27-2021_12:00.pre_revert.1655328160 /ifs/data/marketing
This allows for an easy roll-back of a SnapRevert if the desired results are not achieved.
Note that, if a domain is currently preventing the modification or deletion of a file, a protection domain cannot be created on a
directory that contains that file. For example, if files under /ifs/data/smartlock are set to a WORM state by a
SmartLock domain, OneFS will not allow a SnapRevert domain to be created on /ifs/data/.
If a SnapRevert job fails with the error “Error locating ready snapshot revert domain”, this indicates that a DomainMark job has not yet been run on the affected directory. Additionally, the SnapRevert job error “Directory/file may still have open file handles or pending async delete… check efs.bam.busy_vnodes.” can often be resolved by running the ‘isi_for_array isi_flush’ CLI command.
If desired or required, SnapRevert domains can also be deleted using the job engine CLI. For example, to delete the SnapRevert domain at /ifs/data/marketing:
# isi job jobs start domainmark --root /ifs/data/marketing --dm-type SnapRevert --delete