Within OneFS, the shadow store is a class of system file that contains blocks which can be referenced by different file – thereby providing a mechanism that allows multiple files to share common data. Shadow stores were first introduced in OneFS 7.0, initially supporting Isilon file clones, and indeed there are many overlaps between cloning and deduplicating files. As we will see, a variant of shadow store is also used as a container for file packing in OneFS SFSE (Small File Storage Efficiency), often used in archive workflows such as healthcare’s PACS.
Architecturally, each shadow store can contain up to 256 blocks, with each block able to be referenced by 32,000 files. If this 32KB reference limit is exceeded, a new shadow store is created. Additionally, shadow stores do not reference other shadow stores. All blocks within a shadow store must be either sparse or point at an actual data block. And snapshots of shadow stores are not allowed, since shadow stores have no hard links.
Shadow stores contain the physical addresses and protection for data blocks, just like normal file data. However, a fundamental difference between a shadow stores and a regular file is that the former doesn’t contain all the metadata typically associated with traditional file inodes. In particular, time-based attributes (creation time, modification time, etc) are explicitly not maintained.
Consider the shadow store information for a regular, undeduped file (file.orig):
# isi get -DDD file.orig | grep –i shadow * Shadow refs: 0 zero=36 shadow=0 ditto=0 prealloc=0 block=28
A second copy of this file (file.dup) is then created and then deduplicated:
# isi get -DDD file.* | grep -i shadow * Shadow refs: 28 zero=36 shadow=28 ditto=0 prealloc=0 block=0 * Shadow refs: 28 zero=36 shadow=28 ditto=0 prealloc=0 block=0
As we can see, the block count of the original file has now become zero and the shadow count for both the original file and its copy is incremented to ‘28′. Additionally, if another file copy is added and deduplicated, the same shadow store info and count is reported for all three files. It’s worth noting that even if the duplicate file(s) are removed, the original file will still retain the shadow store layout.
Each shadow store has a unique identifier called a shadow inode number (SIN). But, before we get into more detail, here’s a table of useful terms and their descriptions:
| Element | Description |
| Inode | Data structure that keeps track of all data and metadata (attributes, metatree blocks, etc.) for files and directories in OneFS |
| LIN | Logical Inode Number uniquely identifies each regular file in the filesystem. |
| LBN | Logical Block Number identifies the block offset for each block in a file |
| IFM Tree or Metatree | Encapsulates the on-disk and in-memory format of the inode. File data blocks are indexed by LBN in the IFM B-tree, or file metatree. This B-tree stores protection group (PG) records keyed by the first LBN. To retrieve the record for a particular LBN, the first key before the requested LBN is read. The retried record may or may not contain actual data block pointers. |
| IDI | Isi Data Integrity checksum. IDI checkcodes help avoid data integrity issues which can occur when hardware provides the wrong data, for example. Hence IDI is focused on the path to and from the drive and checkcodes are implemented per OneFS block. |
| Protection Group (PG) | A protection group encompasses the data and redundancy associated with a particular region of file data. The file data space is broken up into sections of 16 x 8KB blocks called stripe units. These correspond to the N in N+M notation; there are N+M stripe units in a protection group. |
| Protection Group Record | Record containing block addresses for a data stripe .There are five types of PG records: sparse, ditto, classic, shadow, and mixed. The IFM B-tree uses the B-tree flag bits, the record size, and an inline field to identify the five types of records. |
| BSIN | Base Shadow Store, containing cloned or deduped data |
| CSIN | Container Shadow Store, containing packed data (container or files). |
| SIN | Shadow Inode Number is a LIN for a Shadow Store, containing blocks that are referenced by different files; refers to a Shadow Store |
| Shadow Extent | Shadow extents contain a Shadow Inode Number (SIN), an offset, and a count.
Shadow extents are not included in the FEC calculation since protection is provided by the shadow store. |
Blocks in a shadow store are identified with a SIN and LBN (logical block number).
# isi get -DD /ifs/data/file.dup | fgrep –A 4 –i “protection group” PROTECTION GROUPS lbn 0: 4+2/2 4000:0001:0067:0009@0#64 0,0,0:8192#32
A SIN is essentially a LIN that is dedicated to a shadow store file, and SINs are allocated from a subset of the LIN range. Just as every standard file is uniquely identified by a LIN, every shadow store is uniquely identified by a SIN. It is easy to tell if you are dealing with a shadow store because the SIN will begin with 4000. For example, in the output above:
4000:0001:0067:0009
Correspondingly, in the protection group (PG) they are represented as:
- SIN
- Block size
- LBN
- Run
The referencing protection group will not contain valid IDI data (this is with the file itself). FEC parity, if required, will be computed assuming a zero block.
When a file references data in a shadow store, it contains meta-tree records that point to the shadow store. This meta-tree record contains a shadow reference, which comprises a SIN and LBN pair that uniquely identifies a block in a shadow store.
A set of extension blocks within the shadow store holds the reference count for each shadow store data block. The reference count for a block is adjusted each time a reference is created or deleted from any other file to that block. If a shadow store block’s reference count drop to zero, it is marked as deleted, and the ShadowStoreDelete job, which runs periodically, deallocates the block.
Be aware that shadow stores are not directly exposed in the filesystem namespace. However, shadow stores and relevant statistics can be viewed using the ‘isi dedupe stats’, ‘isi_sstore list’ and ‘isi_sstore stats’ command line utilities.
Cloning
In OneFS, files can easily be cloned using the ‘cp –c’ command line utility. Shadow store(s) are created during the file cloning process, where the ownership of the data blocks is transferred from the source to the shadow store.
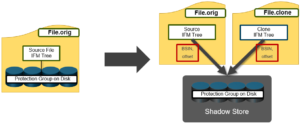
In some instances, data may be copied directly from the source to the newly created shadow stores. Cloning uses logical references to shadow stores, and the source and the destination data blocks refer to an offset in a shadow store. The source file’s protection group(s) are moved to a shadow store, and the PG is now referenced by both the source file and destination clone file. After cloning a file, both the source and the destination data blocks refer to an offset in a shadow store.
Dedupe
Shadow Stores are also used for both OneFS in-line deduplication and post-process SmartDedupe. The principle difference with dedupe, as compared to cloning, is the process by which duplicate blocks are detected.
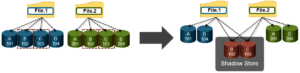
Since in-line dedupe and SmartDedupe use different hashing algorithms, the indexes for each are not shared directly. However, the work performed by each dedupe solution can be leveraged by each other. For instance, if SmartDedupe writes data to a shadow store, when those blocks are read, the read hashing component of inline dedupe will see those blocks and index them.
SmartDedupe post process dedupe is compatible with in-line data reduction and vice versa. In-line compression is able to compress OneFS shadow stores. However, for SmartDedupe to process compressed data, the SmartDedupe job will have to decompress it first in order to perform deduplication, which is an addition resource overhead.
Currently neither SmartDedupe nor in-line dedupe are immediately aware of the duplicate matches that each other finds. Both in-line dedupe and SmartDedupe could dedupe blocks containing the same data to different shadow store locations, but OneFS is unable to consolidate the shadow blocks together. When blocks are read from a shadow store into L1 cache, they are hashed and added into the in-memory index where they can be used by in-line dedupe.
Unlike SmartDedupe, in-line dedupe can deduplicate a run of consecutive blocks to a single block in a shadow store. In contrast, the SmartDedupe job also has to spend more effort to ensure that contiguous file blocks are generally stored in adjacent blocks in the shadow store. If not, both read and degraded read performance may be impacted.
Small File Storage Efficiency
A class of specialized shadow stores are also used as containers for storage efficiency, allowing packing of small file into larger structures that can be FEC protected.
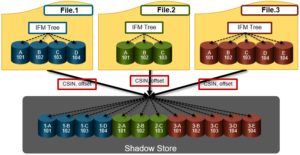
These shadow stores differ from regular shadow stores in that they are deployed as single-reference stores. Additionally, container shadow stores are also optimized to isolate fragmentation, support tiering, and live in a separate subset of ID space from regular shadow stores. (4080:xxxx:xxxx:xxxx).