The NFSv4.1 spec introduced several new features and functions to the NFSv4 protocol standard, as defined in RFC-5661 and covered in Section 1.8 of the RFC. Certain features are listed as ‘required’, which indicates that they must be implemented in or supported by the NFS server to claim RFC standard compliance. Other features are denoted as ‘recommended’ or ‘optional’ and are supported ad hoc by the NFS server, but are not required to claim RFC compliance.
OneFS 9.3 introduces support for both NFSv4.1 and NFSv4.2. This is achieved by implementing all the ‘required’ features defined in RFC-5661, with the exception of the Secret State Verifier (SSV). SSV is currently not supported by any open source Linux distributions, plus most server implementations also do not support SSV.
The following chart illustrates the supported NFS operations in the new OneFS 9.3 release:

Both NFSv4.1 and v4.2 use the existing OneFS NFSv4.0 I/O stack, and NFSv4.2 is a superset of NFSv4.1, with all of the new features being optional.
Note that NFSv4.2 is a true minor version and does not make any changes to handshake, mount, or caching mechanisms. Therefore an unfeatured NFSv4.2 mount is functionally equivalent to an NFSv4.1 mount. As such, OneFS enables clients to mount exports and access data via NFSv4.2, even though the 4.2 operations have yet to be implemented.
Architecturally, the new NFSv4.1 features center around a new handshake mechanism and cache state, which is created around connections and connection management.
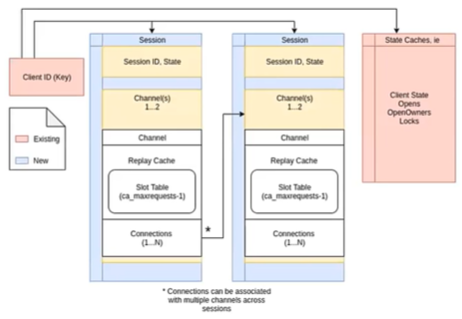
NFSv4.1 formalizes the notion of a replay cache, which is one-to-one with a channel. This reply cache, or duplicate request cache, tracks recent transactions, and resends the cached response rather than performing the operation again. As such, performance can also benefit from the avoidance of unnecessary work.
Existing NFSv4.0 I/O routines are used alongside new NFSv4.1 handshake and state management routines such as EXCHANGEID, CREATESESSION and DESTROYSESSION, while deprecating some of the older handshake mechanisms like SETCLIENTID and SETCLIDENTIDCONFIRM.
In NFSv4.1, explicit client disconnect allows a client to request that a server that it would like to disconnect and destroy all of its state. By contrast, in 4.0 client disconnect is implied and requires on timeouts.
While the idea of a lock reclamation grace period was implied in NFSv4.0, the NFSv4.1 and 4.2 RFC explicitly defines lock failover. So if a client attaches to a server that it does not recognize or have a prior connection to, it will automatically attempt to reclaim locks using the LKF protocol lock grace period mechanism.
Connection tracking is also implemented in NFSv4.1 allow a server to keep track of its connections under each session channel, which is required for trunking.
Performance-wise, NFSv4.0 and NFSv4.1 are very similar across a single TCP connection. However, with NFSv4.1, Linux clients can now utilize trunking to enjoy the performance advantages of multiplexing. We’ll be taking a closer look at session and client ID trunking in the next blog article in this series.
The NFS service is disabled by default in OneFS, but can be easily started and configured from either the CLI or WebUI. Linux clients will automatically mount the highest available version available, and because of this NFSv4.1 and NFSv4.2 are disabled by default on install or upgrade to OneFS 9.3, so environments will not be impacted. If it’s desired to use particular NFS version(s), this should be specified in the mount syntax.
The NFSv4.1 or v4.2 protocol versions can be easily enabled from the OneFS CLI, for example:
# isi services nfs enable
# isi nfs settings global modify --nfsv41-enabled=true --nfsv42-enabled=true
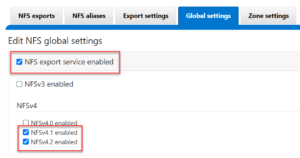
Or from the WebUI, by navigating to Protocols > NFS > Global Settings and checking both the service enablement box and the desired protocol versions:
Create an NFS export with WebUI or CLI command.
# isi nfs exports create --paths=/ifs/data
When using NFSv4.x, the domain name should be uniform both the cluster and client(s). The NFSv4.x domain is presented as user@doamin or group@domain pairs in ‘getattr’ and ‘setattr’ operations, for example. If the domain is does not match, new and existing files appear owned by user ‘nobody’ user on the cluster. The cluster’s NFSv4.x domain can be configured via the CLI using the ‘isi nfs settings zone modify’ command as follows:
# isi nfs settings zone modify --nfsv4-domain=nfs41test --zone=System
Or from the WebUI by navigating to Protocols > NFS > Zone settings.
On the Linux client side, the NFSv4 domain can be configured by editing the /etc/idmapd.conf file:
# cat /etc/idmapd.conf [General] Verbosity = 0 Pipefs-Directory = /run/rpc_pipefs # set your own domain here, if it differs from FQDN minus hostname Domain = nfs41test [Mapping] Nobody-User = nobody Nobody-Group = nogroup
NFSv4.x clients use the nfsidmap daemon for the NFSv4.x ID <-> name mapping translation, so ensure the daemon is running correctly after configuring the NFSv4.x domain. The following CLI commands will restart the nfs-idmapd daemon and confirm that it’s happily running:
# systemctl restart nfs-idmapd
# systemctl status nfs-idmapd nfs-idmapd.service - NFSv4 ID-name mapping service Loaded: loaded (/lib/systemd/system/nfs-idmapd.service; static) Active: active (running) since Thurs 2021-11-18 19:47:01 PDT; 6s ago Process: 2611 ExecStart=/usr/sbin/rpc.idmapd $RPCIDMAPDARGS (code=exited, status=0/SUCCESS) Main PID: 2612 (rpc.idmapd) Tasks: 1 (limit: 4595) Memory: 316.0K CGroup: /system.slice/nfs-idmapd.service └─2612 /usr/sbin/rpc.idmapd Nov 18 19:47:01 ubuntu systemd[1]: Starting NFSv4 ID-name mapping service... Nov 18 25 19:47:01 ubuntu systemd[1]: Started NFSv4 ID-name mapping service.
The domain value can also be checked by running the nfsidmap command as follows:.
# sudo nfsidmap -d nfs41test
Next, mount the NFS export via NFSv4.1 or NFSv4.2, or both versions, as desired:
# sudo mount -t nfs -vo nfsvers=4.1 10.1.128.131.10:/ifs/data /mnt/nfs41/
Netstat can be used as follows to verify the established NFS TCP connection and its associated port.
# netstat -ant4 | grep 2049 tcp 0 0 0.0.0.0:2049 0.0.0.0:* LISTEN tcp 0 0 10.1.128.131.131:996 10.1.128.131.10:2049 ESTABLISHED
From the cluster’s CLI, the NFS connections can be checked with ‘isi_nfs4mgmt’. The isi_nfs4mgmt CLI tool has been enhanced in OneFS 9.3, and new functionality includes:
- Expanded reporting. includes sessions, channels, and connections
- Nfs4mgmt summary reports the version of each client connection
- Nfs4mgmt enables a cluster admin to open or lock a session,
- Allows cache state to be viewed without creating a coredump
When used with the ‘list’ flag, the ‘isi_nfs4mgmt’ command output includes the client ID, NFS version, session ID, etc.
# isi_nfs4mgmt –list ID Vers Conn SessionId Client Address Port O-Owners Opens Handles L-Owners 605157838779675654 4.1 n/a 2 912.168.198.131 959 0 0 0 0 can be found at /var/isi_nfs4mgmt/nfs_clients.dump_2021-11-18T15:25:18
In summary, OneFS 9.3 adds support for both NFSv4.1 and v4.2, implements new functionality, lays the groundworks for addition future functionaility, and delivers NFS trunking, which we’ll explore in the next article.