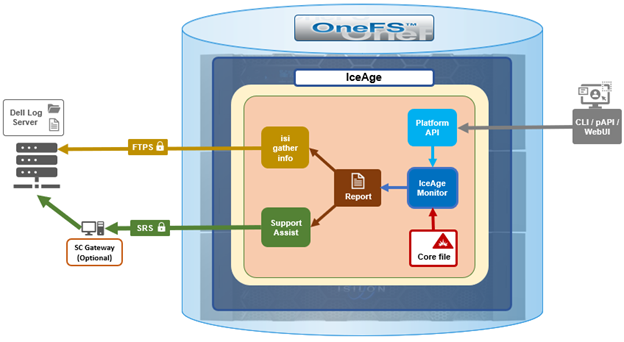
In addition to the OneFS WebUI and CLI administrative management interfaces, a PowerScale cluster can also be accessed, queried and configured via a representative state transfer (RESTful) API. This API includes a superset of the Web and CLI interfaces and provides the additional benefit of being easily programmable. As such, it allows most of the cluster’s administrative tasks to be scripted and automated.
RESTful APIs are web based (HTTP or HTTPS) interfaces that use the HTTP methods, combined with the URL (uniform resource locator), to undertake a predefined action. The URL can describe either a collection of objects (eg. ‘https://papi.isln.com:8080/<resources>/’) or an individual object from a collection (eg. ‘https://papi.isln.com:8080/<resources>/<object>’).
There are typically six principal HTTP operations, or ‘methods’:
| Method | Object | Collection |
| Get | Retrieve a representation of the addressed member of the collection. | List the URIs and (optionally) additional details of a collection’s members. |
| Put | Replace or create the addressed member of a collection. | Replace the entire collection with another collection. |
| Post | Infrequently used to promote an element to a collection in its own right, creating a new object within it. | Create a new entry in the collection. The new entry’s URI is typically automatically assigned and usually returned by the operation. |
| Patch | Update the addressed member of a collection. | Rarely used. |
| Delete | Delete the addressed member of a collection. | Delete an entire collection. |
| Head | Returns response header metadata without the response body content. | Returns response header metadata without the response body content. |
For a given application programming interface (API), its path component typically conveys specific meaning, or ‘representative state’, to the RESTful spec. The ‘human readability’ of a RESTful endpoint can be seen, for example, by looking at a request for a cluster’s SMB shares information:

As shown above, the URL is clearly comprised of distinct parts:
| Component | Description |
| Scheme | Essentially the HTTP protocol version |
| Authority | IP address (<cluster_ip>) and TCP port (<port>) of the cluster. |
| Path | HTTP path to the endpoint |
| Query | The specific endpoint and data requested. |
| Fragment | Occasionally the query is subdivided, such as ‘query#fragment’. |
Additionally, OneFS also uses the following API definitions, which are worth understanding:
| Item | Description |
| Access point | Root path of the URL to the file system. An access point can be defined for any directory in the file system. |
| Collection | Group of objects of a similar type. For example, all the user-defined quotas on a cluster make up a collection of quotas. |
| Data object | An object that contains content data, such as a file on the system |
| Endpoint | Point of access to a resource, comprising a path, query, and sometimes fragment(s). |
| Namespace | The file system structure on the cluster. |
| Object | Containers or data objects. Also known as system configuration data that a user creates, or a global setting on the system.
· user-created object: snapshot, quota, share, export, replication policy, etc. · global settings: default share settings, HTTP settings, snapshot settings, etc. |
| Platform | Indicates pAPI and the OneFS configuration hierarchy. |
| Resource | An object, collection, or function that you can access by a URI. |
| Version | The version of the OneFS API. It is an optional component, as OneFS automatically uses the latest API. |
At a high level, the overall OneFS API is divided into two distinct sections:
| Section | API | Description |
| Namespace | RAN | Enables operations on files and directories on the cluster. |
| Platform | pAPI | Provides endpoints for cluster configuration, management, and monitoring functionality. |
As such, the general topology is as follows:
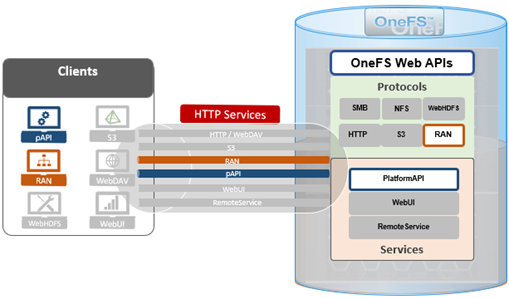
The Platform API (pAPI) provides a variety of endpoints for managing the administrative aspects of a PowerScale cluster. Indeed, the OneFS CLI and WebUI both use these pAPI handlers to facilitate their cluster config and management functionality, so pAPI represents a superset of both user interfaces.
For file system configuration API requests, the resource URI is composed of the following components:
https://<cluster_ip>:<port>/<api><version>/<path>/<query>
For example, a GET request sent to the following platform URI will return all the SMB shares on a cluster. Where ‘platform’ indicates pAPI, ’17’ is the API version, ‘protocols’ is the configuration area, ‘SMB’ is the collection name, and ‘shares’ is the object ID:
GET https://10.1.10.20:8080/platform/17/protocols/smb/shares
By way of contrast, file system access APIs requests are served by the RESTful Access to Namespace (RAN) API. RAN uses resource URIs, which are composed of the following components:
https://<cluster_ip>:<port>/<access_point>/<resource_path>
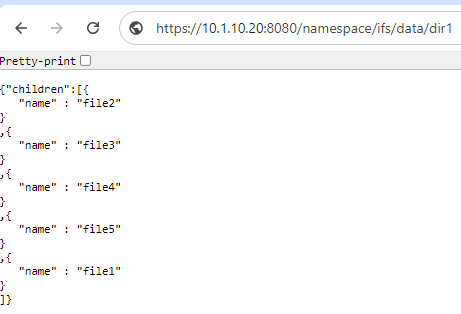
For example, a GET request to the following RAN URI will return the files that are stored within the namespace under /ifs/data/dir1:
GET https://10.1.10.20:8080/namespace/ifs/data/dir1
The response will look something like the following:
In the next couple of articles in this series we’ll dig into the architecture and details of the platform (pAPI) and namespace (RAN) APIs in more depth.