Short Description
Explore Hive LLAP by using Horontworks Testbench to generate data and run queries with LLAP enabled using HiveServer2 Interactive JDBC URL.
Article
The latest release of Isilon OneFS 8.1.2 delivers new capabilities and support like Apache Hadoop 3, Isilon Ambari Management pack, Apache Hive LLAP, Apache Ranger with SSL and WebHDFS. In this article, we shall explore Apache Hive LLAP using Horontworks Hive Testbench which supports LLAP. The Hive Testbench consists of a data generator and a standard set of queries typically used for benchmarking hive performance. This article describes how to generate data and run a query in beeline, with LLAP enabled.
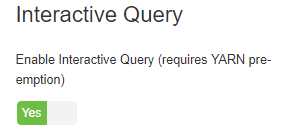
If you don’t have a cluster already configured for LLAP, set up new HDP2.6 on Isilon OneFS from here and enable Interactive query under Ambari Server UI –> Hive –> Configs as below.
Hive Testbench setup
1. Log into the HDP client node where HIVE is installed.
2. Install and Setup Hive testbench
3. Generate 5GB of test data: [Here we shall use TPC-H Testbench]
/If GCC not install/ yum install -y gcc
/If javac not found/ export JAVA_HOME=/usr/jdk64/jdk1.8.**** ; export PATH=$JAVA_HOME/bin:$PATH
cd hive-testbench-hdp3/ sudo ./tpch-build.sh ./tpch-setup.sh 5
4. A MapReduce job runs to create the data and load the data into hive. This will take some time to complete. The last line in the script is:
Data loaded into database tpch_******.
Make sure all the below prerequisites are met before proceeding ahead.
1. HDP cluster up and running
2. YARN all services, Hive all services are up and running
3. Uid/gid parity and necessary directory structure maintained between HDP and OneFS
4. Interactive Query enabled.
5. Hive Testbench TPC-H database setup and data loaded.
Connecting to Interactive Service and running queries
Through Command Line
1. Log into the HDP client node where HIVE is installed and Hive Testbench setup.
2. Change to the directory where Hive Testbench is placed and into the sample-queries-tpch.
3. From Ambari Server Web UI –> HIVE Service –> Summary page, copy the “HiveServer2 Interactive JDBC URL”

4. Run beeline with HiveServer2 Interactive JDBC URL with credential hive/hive.
beeline -n hive -p hive -u "jdbc:hive2://hawkeye03.kanagawa.demo:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-hive2"

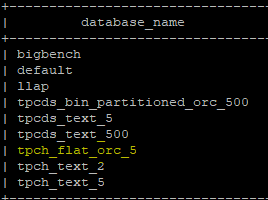
5. Run show databases command to check the tpch databases created during HIVE Testbench setup.
0: jdbc:hive2://hawkeye03.kanagawa.demo:2181/> show databases;
6. Switch to the tpch_flat_orc_5 databases
0: jdbc:hive2://hawkeye03.kanagawa.demo:2181/> use tpch_flat_orc_5;
7. Run the query7.sql by issuing run command as below and note down the execution time, let’s call this 1st run.
0: jdbc:hive2://hawkeye03.kanagawa.demo:2181/> !run query7.sql

To monitor LLAP functioning open HiveServer2 Interactive UI from the Ambari Server web UI –> Hive service –> Summary –> Quick Links –> HiveServer2 Interactive UI
Figure :: HiveServer2 Interactive UI
Now click on Running Instances Web URL(highlighted in above image) to go to LLAP Monitor page
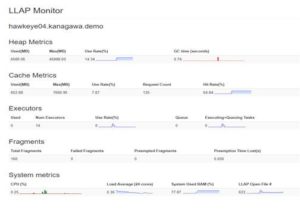
On this LLAP Monitor UI, metrics to watch are Cache (use rate, Request count, Hit Rate) and System (LLAP open Files).
8. Immediate after step 7, which was 1st time query7.sql run, let us run the same query7.sql again and call it 2nd run. Monitor execution time, LLAP cache Metrics and System metrics.

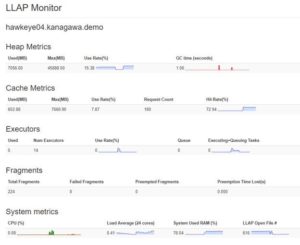
Notice the drastic reduction in the execution time, with increase in Cache metrics.
9. Let us run the same query7.sql again, 3rd time.

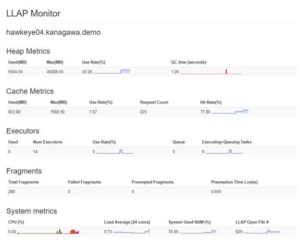
Notice that the 2nd and 3rd run of the query7.sql completes much more quickly, this is because the LLAP cache fills with data, queries respond more quickly.
Summary
Hive LLAP combines persistent query servers and intelligent in-memory caching to deliver blazing-fast SQL queries without sacrificing the scalability Hive and Hadoop are known for. With OneFS 8.1.2 support for Hive LLAP the Hadoop cluster installed on OneFS benefit with LLAP feature for fast and interactive SQL on Hadoop with Hive LLAP. So benefits of Hive LLAP include LLAP uses persistent query servers to avoid long startup times and deliver fast SQL. Shares its in-memory cache among all SQL users, maximizing the use of this scarce resource. LLAP has fine-grained resource management and preemption, making it great for highly concurrent access across many users. LLAP is 100% compatible with existing Hive SQL and Hive tools.