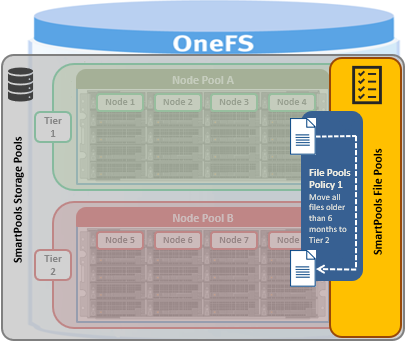
SmartPools is the OneFS tiering engine, and it enables multiple levels of performance, protection, and storage density to co-exist within a PowerScale cluster. SmartPools allows a cluster admin to define the value of a cluster’s data, and automatically align it with the appropriate price/performance tier over time. Data movement is seamless, and with file-level granularity and control via automated policies, you can easily tune performance and layout, storage tier alignment, and protection settings – with minimal impact to a cluster’s end-users. But first, we’ll run through its taxonomy.
At its core, SmartPools is logically separated into two areas: storage pools and file pools.
Heterogeneous PowerScale clusters can be built with a wide variety of node styles and capacities, in order to meet the needs of a varied data set and wide spectrum of workloads. These node styles fall loosely into three main categories or tiers.
- F-series, all-flash nodes, typically for high performance, low latency workloads
- H-series hybrid nodes, containing a mixture of SSD and hard drives, great for concurrency and streaming workloads.
- A-series active archive nodes, capacity optimized and using large SATA drives.
Storage pools in OneFS provide the ability to define hardware tiers within a single cluster, allowing file layout to be aligned with specific sets of nodes by configuring storage pool policies.
The notion of Storage pools is an abstraction that includes disk pools, node pools, and tiers.

Disk pools are the smallest unit within the storage pools hierarchy. OneFS provisioning works on the premise of dividing the hard drives and SSDs in similar node types into sets, with each pool representing a separate failure domain.
These disk pools are typically protected by default at +2d:1n (or the ability to withstand two disk or one entire node failure) and span a neighborhood from three to forty standalone F-series nodes, or a neighborhood of four to twenty chassis-based H and A series nodes – where each chassis contains four compute modules (one per node), and five drive containers, or ‘sleds’, per node.
Each drive belongs to one disk pool and data protection stripes or mirrors typically don’t extend across pools. Disk pools are managed by OneFS and are generally not user configurable.

Node pools are groups of disk pools, spread across similar storage nodes. Multiple node pools of differing types can coexist in a single, heterogeneous cluster, and this is the lowest level of pool that general SmartPools configuration targets. Say, for example: one node pool of all-flash F-Series nodes for HPC, one node pool of H-Series nodes, for home directories and file shares, and one node pool of A-series nodes, for archive data.
This allows OneFS to present a single storage resource pool, comprising multiple flash and spinning drive media types – NVMe, high speed SAS, large capacity SATA – providing a range of different performance, protection, and capacity characteristics. This heterogeneous storage pools in turn can support a diverse range of applications and workloads with a single, unified namespace and point of management. It also enables the mixing of older and newer hardware, allowing for simple investment protection even across product generations, and seamless hardware refreshes.
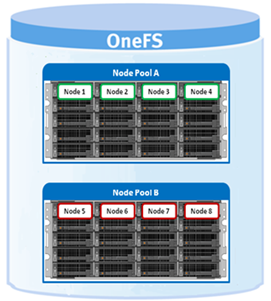
Each node pool only contains disk pools from the same type of storage nodes, and a disk pool may belong to exactly one node pool. For example, all-flash F-series nodes would be in one node pool, whereas A-series nodes with high capacity SATA drives would be in another. Today, a minimum of 4 nodes, or one chassis, are required per node pool for Gen6 modular chassis-based hardware, or three PowerScale F-series nodes per node pool.
Nodes are not associated with each other, or provisioned, until at least three nodes from the same compatibility class are assigned in a node pool. If nodes are removed from a pool, that node pool becomes under-provisioned. In this situation, if two like-nodes remain, they are still writable. If only one remains, it is automatically set to read-only.
Once node pools are created, they can be easily modified to adapt to changing requirements. Individual nodes can be reassigned from one node pool to another, if necessary. Node pool associations can also be discarded, releasing member nodes so they can be added to new or existing pools. Node pools can also be renamed at any time without changing any other settings in the node pool configuration.
When new nodes are added to a cluster, they’re automatically allocated to a node pool, and then subdivided into disk pools without any additional configuration steps – and they inherit the SmartPools configuration properties of that node pool. This means the configuration of a pool’s data protection, layout ,and cache settings only needs to be done once, at the time the node pool is first created. Automatic allocation is determined by the shared attributes of the new nodes with the closest matching node pool. If the new node is not a close match to the nodes of any existing pool, it remains un-provisioned until the minimum node pool membership for like-nodes is met.
When a new node pool is created, and nodes are added, SmartPools associates those nodes with a pool ID. This ID is also used in file pool policies and file attributes to dictate file placement within a specific disk pool.
By default, a file which is not covered by a specific file pool policy will go to the configured ‘default’ node pool, identified during set up. If no default is specified, SmartPools will typically write that data to the pool with the most available capacity.
Tiers are groups of node pools combined into a logical superset to optimize data storage, typically according to OneFS platform type.
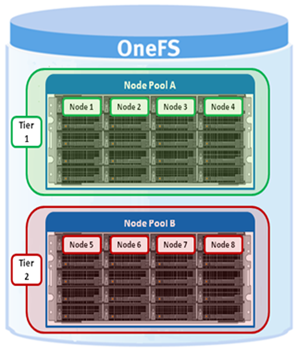
For example, similar ‘archive’ node pools are often consolidated into a single tier, which could incorporate different styles of archive node pools into a single, logical container. For example, PowerScale A300s with 12TB SATA drives and PowerScale A3000s with 16TB SATA drives logically combined into a single active archive tier. This is a significant benefit to customers who consistently purchase the highest capacity nodes available, to consolidate a variety of node styles within a single tier and manage them as one logical group.
Note, however, that a storage efficiency cost may be incurred if the node pools in a tier are too small. For example, in a six node cluster with two separate three-node pools (different drive sizes), each pool has a 33% protection overhead. This is compared to a six node cluster with single six-node pool (same drive size), protection overhead drops to 16% (at the default +2d:1n protection).
SmartPools users frequently deploy 2 to 4 tiers, with the fastest tier typically containing all-flash nodes for the most performance demanding portions of a workflow, and the lowest, capacity-biased tier comprising high capacity SATA drive nodes.
SmartPools allows nodes of any type supported by the particular OneFS version, to be combined within the same cluster. The like-nodes are provisioned into different node pools according to their physical attributes:
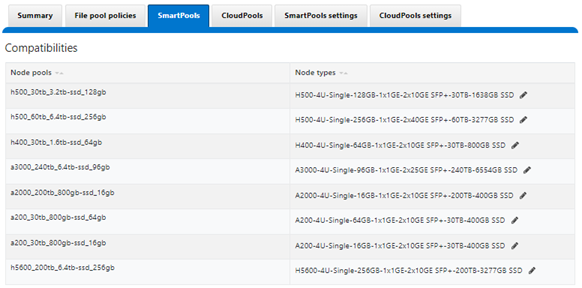
These node compatibility classes are fairly stringent. This is in order to avoid disproportionate amounts of work being directed towards a subset of cluster resources, which could result in bullying of the lower powered nodes.
However, cluster administrators can safely target specific data to broader classes of storage by creating tiers. For example, if a cluster includes two different varieties of H nodes, such as H700s and H7000s, these will automatically be provisioned into two different node pools. These two node pools can be logically combined into a tier, and file placement targeted to it, resulting in automatic balancing across the node pools.
SmartPools separates hardware by node type and creates a separate node pool for each distinct hardware variant. To reside in the same node pool, nodes must have a set of core attributes in common, and node compatibilities can be defined to allow nodes with the same drive types, quantities and capacities and compatible RAM configurations, to be provisioned into the same pools.
That said, due to significant architectural differences, there are no node compatibilities between the chassis-based all-flash F800 or F810s, and the self-contained all-flash nodes like the F600 or F900.
OneFS also contains an SSD compatibility option, which allows nodes with dissimilar flash capacity to be provisioned to a single node pool. When creating this SSD compatibility, OneFS automatically checks that the two pools to be merged have the same number of SSDs, tier, requested protection, and the same SSD strategy or L3 cache setting.
If a node pool fills up, writes to that pool will automatically spill over to the next pool. This default behavior ensures that work can continue, even if one type of capacity is full. There are some circumstances in which spillover is undesirable, for example when different business units within an organization purchase separate pools, or data location has security or protection implications. In these circumstances, spillover can simply be disabled. Disabling spillover ensures a file exists in one pool and will not move to another.
From a data protection and layout efficiency point of view, SmartPools subdivides large numbers of like nodes into smaller, more efficiently protected disk pools – automatically calculating and grouping the cluster into pools of disks, that are optimized for both Mean Time to Data Loss (MTTDL) and efficient space utilization. This means that protection level decisions are not left to the cluster admin, unless desired.
With Automatic Provisioning, every set of equivalent node hardware is automatically split up into disk pools, node pools and neighborhoods. These pools are protected by default against up to two drive or one node failure per disk pool. By subdividing a node’s disks into multiple, separately protected disk pools, nodes are significantly more resilient to multiple disk failures.
If the automatically provisioned node pools that OneFS creates are not appropriate for an environment, they can be manually reconfigured. This is done by creating a manual node pool and moving nodes from an existing node pool to the newly created one. However, the strong recommendation is to use the default, automatically provisioned node pools. Manually assigned pools may not provide the same level of performance and storage efficiency as automatically assigned pools.
Unlike hardware RAID, OneFS has no requirement for dedicated hot spare drives. Instead, it simply borrows from the available free space in the file system in order to recover from failures; this technique is called virtual hot spare, or VHS.
SmartPools Virtual Hot Spare helps ensure that node pools maintain enough free space to successfully re-protect data in the event of drive failure. Though configured globally, VHS actually operates at the disk pool level so that nodes with different size drives reserve the appropriate VHS space. This helps ensure that, while data may move from one disk pool to another during repair, it remains on the same class of storage.
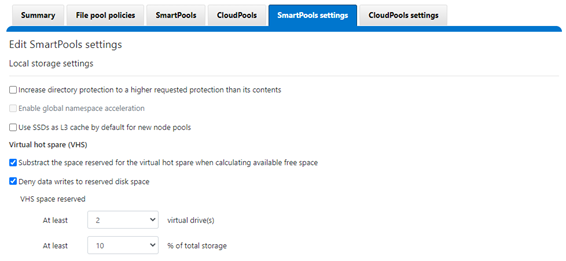
VHS reservations are cluster wide and configurable as either a percentage of total storage, up to 20%, or from 1 to 4 virtual drives. This reservation works by allocating a fraction of the node pool’s VHS space in each of its constituent disk pools.
Keep in mind that reservations for virtual hot sparing will affect spillover – if, for example, VHS is configured to reserve 10% of a pool’s capacity, spillover will occur at 90% full.