Introduced in OneFS 9.3, SMB drain support further enhances OneFS non-disruptive upgrades, by allowing for the safe disconnection of SMB clients. In an ideal world, OneFS would be able to seamlessly migrate all SMB clients transparently to non-rebooting nodes. Windows continuous availability (CA) does this natively, but this is not always a viable option given the client SMB3 support requirements, the performance implications of CA, etc.
Because SMB clients may be caching data through the use of oplocks or leases, it is important to ensure that this caching is stopped prior to disconnecting a client. OneFS SMB drain support ensures that, in non-CA cases, an SMB client is able to flush its cache before being disconnected, and, in conjunction with SmartConnect, enables safe migration of SMB clients to non-rebooting nodes in a cluster.
The following diagram illustrates the basic interaction of the SMB server and SmartConnect with the drain service:
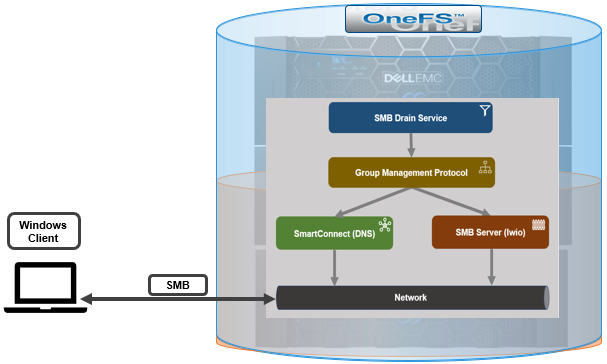
Both SmartConnect and SMB detect when the drain service is running on the local node through the OneFS group management protocol (GMP). When the drain service is active, SmartConnect will no longer include the draining node’s IP address in DNS query responses. Then SMB starts the process of disconnecting clients.
GMP indicates whether the drain service is running on a local node, and, if so, SMB will no longer grant new oplocks or leases. So when a new oplock or lease is requested, the server responds indicating a conflict, which prevents the granting of the lock or lease. SMB then starts the process of breaking existing oplocks and leases, by emulating conflicting access. So, in the case of the lease, OneFS will send a break response to the client, and, depending on the type of lease, will either wait for an acknowledgement of the break or break the lease immediately. The OneFS lwio server continually scans for sessions which have no oplocks or leases, and these sessions can then be drained down and disconnected. Note that an SMB clients with oplocks and leases disabled will automatically be a candidate for disconnection, since no sessions or locks will be detected during the scan. When a session is disconnected, the drain service notes the time of the disconnection and the client’s GUID (in the case of SMB 2 or 3) or its IP address (if SMB1). This information is used to track any reconnecting clients.
Once a Windows client has been disconnected, it typically sends a DNS request and receives a response with an IP address of a non-draining node to connect to. However, not all SMB clients do this. For example, Linux and MacOS SMB clients will often perform a small number of attempts to reconnect to the previous IP address instead (either due to caching or stubborn client behavior), before declaring a network error. This is obviously undesirable since it results in a user-visible event. So OneFS cannot immediately disconnect reconnecting clients. Instead, the client is allowed to reconnect, but the lwio server starts delaying the responses to ‘session setup’ and ‘tree connect’ requests by 8 seconds by default. So this limits what the client can do after reconnect, and the goal is two persuade it to send a DNS request instead and connect to a non-rebooting node. The responses to negotiate request are not delayed because most clients will automatically consider the lack of a response as a network error and will not retry. If the node happens to reboot before the negotiation response is sent, the client will likely report an error to the user, so OneFS does not delay the response to minimize this possibility. The server still will not allow oplocks and leases to be granted, and will eventually disconnect the client again, after a default 20 seconds since the last time the client was disconnected.
No configuration is required for this SMB drain functionality in OneFS 9.3 and later, and, as such, there are no CLI commands to control it, etc. The drain service is started on the local node and the service is going to go through the process of safely disconnecting the clients. However, there is a OneFS registry parameter which, if necessary, can be used to modify or override the SMB drain behavior via the isi_gconfig CLI command.
For example, to disable SMB draining:
# isi_gconfig registry.Services.lwio.Parameters.Drivers.srv.EnableSessionDraining=0 registry.Services.lwio.Parameters.Drivers.srv.EnableSessionDraining (uint32) = 0
The three configurable values are:
| Parameter | Default Value | Description |
| EnableSessionDraining | Default is ‘enabled’. | Global SMB draining on/off switch. |
| DrainDisconnectTimeout | Default is 20 seconds. | Controls the minimum time between disconnecting and reconnecting clients. |
| DrainResponseDelay | Default is 8 seconds. | Controls the delay period for responses to ‘session setup’ and ‘tree connect’ requests. |
Be aware that, unlike DrainDisconnectTimeout which is in seconds, the DrainResponseDelay parameter is expressed in milliseconds (ms):
# isi_gconfig registry.Services.lwio.Parameters.Drivers.srv.DrainResponseDelay registry.Services.lwio.Parameters.Drivers.srv.DrainResponseDelay (uint32) = 8000
SMB safe disconnect works in concert with OneFS’ drain-based upgrade, which was introduced in OneFS 9.2. Drain-based upgrade provides a mechanism by which nodes are prevented from rebooting or restarting protocol services until all SMB clients have disconnected from the node. A single SMB client that does not disconnect can cause the upgrade to be delayed indefinitely, so the cluster administrator is provided with options to reboot the node despite persisting clients.
As a truly non-disruptive upgrade process, drain-based upgrade can be potentially slower, since it is dependent upon client disconnections. The core OneFS protocols are handled as follows:
| Protocol | Action |
| SMB | Wait for clients to drain and disconnect before rebooting node |
| SMB3-CA | Witness, drain service → immediate migration → faster upgrade |
| NFS, HDFS, HTTP, S3 | Assumed resilient to rebooting nodes |
Drain-based upgrades can be configured and managed via the OneFS WebUI, CLI, and RESTful platform API, and the supported operations include:
- OneFS upgrades
- Firmware upgrades
- Cluster reboots
- Combined upgrades (OneFS and Firmware)
Drain-based upgrade is predicated upon the parallel upgrade workflow, which offers accelerated upgrades for large clusters by working across OneFS neighborhoods, or fault domains. By concurrently upgrading a node per neighborhood, the more node neighborhoods there are within a cluster the more parallel activity can occur.
Imagine a PowerScale H700 cluster with five chassis split into two neighborhoods, each containing ten nodes:
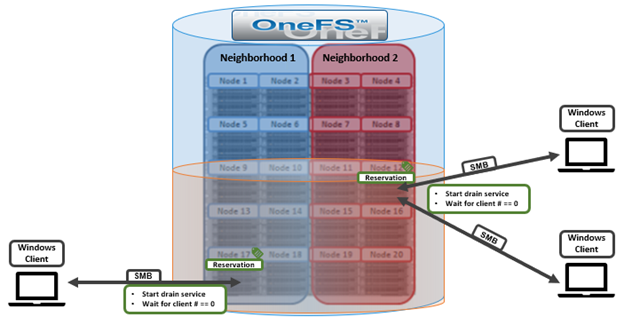
Once the drain-based upgrade is started, a maximum of one node from each neighborhood will get the reservation, which allows the nodes to upgrade simultaneously. OneFS will not reboot these nodes until the number of SMB clients is “0”. Say nodes 12 and 17 get the reservation for upgrading at the same time. However, there is one SMB connection to node 17 and two SMB connections to node 12. Neither of these nodes will be able to reboot until their SMB connection count gets to “0”. At this point, there are three options available:
| Drain Action | Description |
| Wait | Wait until the SMB connection count reaches “0” or it hits the drain timeout value. The drain timeout value is a configurable parameter for each upgrade process. It is the maximum waiting period. If drain timeout is set to “0”, it means wait forever. |
| Delay drain | Add the node into the delay list to delay client draining. The upgrade process will continue on another node in this neighborhood. After all the non-delayed nodes are upgraded, OneFS will rewind to the node in the delay list. |
| Skip drain | Stop waiting for clients to migrate away from the draining node and reboot immediately. |
The ‘isi upgrade cluster drain’ CLI command syntax can be used to manage client draining per-node. For example, to configure node 1 in the cluster to delay draining:
# isi upgrade cluster drain delay add 1
The node(s) will delay draining active SMB client connections (until all nodes in the same neighborhood have finished draining). Are you sure? (yes/[no]): yes
# isi upgrade cluster drain delay list LNN ---- 1
The following CLI syntax can be used to confirm whether there are any active SMB connections. In this case, node 1 has one connected Windows client:
# isi statistics query current --keys=node.clientstats.connected.smb Node node.clientstats.connected.smb ------------------------------------- 1 1 -------------------------------------
The ‘isi upgrade’ CLI command syntax can be used to perform the drain-based upgrade, and now includes flags for configuring drain-timeout and alert-timeout. In this example setting each to value 60 minutes and 45 minutes respectively. As such, if there is still an SMB connection after 45 minutes, a CELOG alert will be triggered to notify the cluster administrator. And after an hour, any remaining SMB connections will be dropped, and the node upgrade reboot will continue.
# isi upgrade start --parallel --skip-optional --install-image-path=/ifs /data/<installation-file-name> --drain-timeout=60m --alert-timeout=45m
From the OneFS WebUI, the same can be achieved by navigating to Upgrade under Cluster management.