Heterogeneous PowerScale clusters can be built with a wide variety of node styles and capacities, in order to meet the needs of a varied data set and wide spectrum of workloads. Isilon nodes are broken into several classes, or tiers, according to their functionality. These node styles encompass several hardware generations, and fall loosely into four main tiers:
OneFS neighborhoods add another level of resilience into the OneFS failure domain concept.

As we saw in the previous article, disk pools represent the smallest unit within the storage pools hierarchy. OneFS provisioning works on the premise of dividing similar nodes’ drives into sets, or disk pools, with each pool representing a separate failure domain. These are protected by default at +2d:1n (or the ability to withstand two disk or one entire node failure). In Gen6 chassis, disk pools are laid out across all five sleds in each nod.. For example, a node with three drives per sled will have the following disk pool configuration:
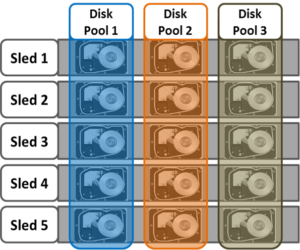
Node pools are groups of disk pools, spread across similar, or compatible, OneFS storage nodes. Multiple groups of different node types can work together in a single, heterogeneous cluster.
In OneFS, a failure domain is the portion of a dataset that can be negatively impacted by a specific component failure. A disk pool comprises a group of drives spread across multiple compatible nodes, and a node usually has drives in multiple disk pools which share the same node boundaries. Since each piece of data or metadata is fully contained within a single disk pool, OneFS considers the disk pool as its failure domain.
PowerScale chassis-based hybrid and archive nodes utilize sled protection, where each drive in a sled is automatically located in a different disk pool. This ensures that if a sled is removed, rather than a failure domain losing four drives, the affected failure domains each only lose one drive.
OneFS neighborhoods help organize and limit the width of a disk pool. Neighborhoods also contain all the disk pools within a certain node boundary, aligned with the disk pools’ node boundaries. As such, a node will often have drives in multiple disk pools, but a node will only be in a single neighborhood. Fundamentally, neighborhoods, node pools, and tiers are all layers on top of disk pools, and node pools and tiers are used for organizing neighborhoods and disk pools.
So the primary function of neighborhoods is to improve OneFS reliability in general, and guard against data unavailability. With the PowerScale all-flash F-series nodes, OneFS has an ideal size of 20 nodes per node pool, and a maximum size of 39 nodes. On the addition of the 40th node, the nodes automatically divide, or split, into two neighborhoods of twenty nodes.
| Neighborhood | F-series Nodes | H-series and A-series Nodes |
| Smallest Size | 3 | 4 |
| Ideal Size | 20 | 10 |
| Maximum Size | 39 | 19 |
In contrast, the Gen6 chassis based platforms, such as the PowerScale H-series and A-series, have an ideal neighborhood size of 10 nodes per node pool, and an automatic split occurs on the addition of the 20th node, or 5th chassis. This smaller neighborhood size helps the Gen6 hardware protect against simultaneous node-pair journal failures and full chassis failures. With the Gen6 platform and partner node protection, where possible, nodes will be placed in different neighborhoods – and hence different failure domains. Partner node protection is possible once the cluster reaches five full chassis (20 nodes) when, after the first neighborhood split, OneFS places partner nodes in different neighborhoods:
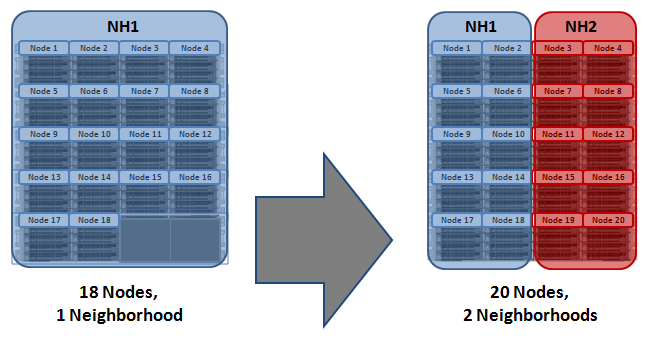
Partner node protection increases reliability because if both nodes go down, they are in different failure domains, so their failure domains only suffer the loss of a single node.
With chassis-level protection, when possible, each of the four nodes within a chassis will be placed in a separate neighborhood. Chassis protection becomes possible at 40 nodes, as the neighborhood split at 40 nodes enables every node in a chassis to be placed in a different neighborhood. As such, when a 38 node Gen6 cluster is expanded to 40 nodes, the two existing neighborhoods will be split into four 10-node neighborhoods:
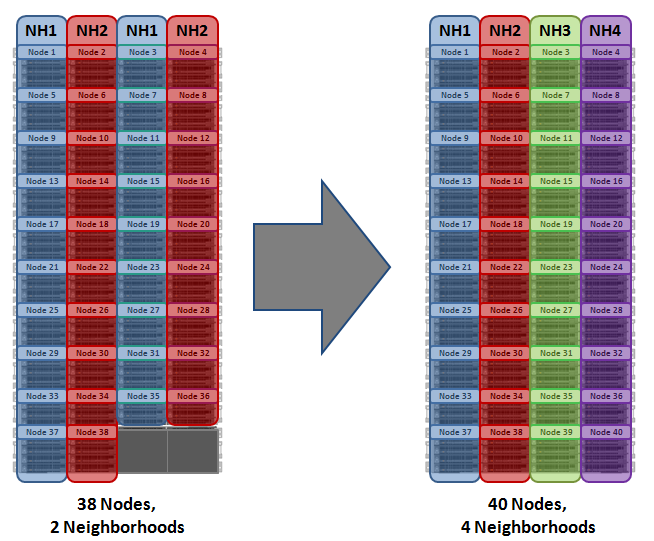
Chassis-level protection ensures that if an entire chassis failed, each failure domain would only lose one node.
The distribution of nodes and drives in pools is governed by gconfig values, such as the ‘pool_ideal_size’ parameter which indicates the preferred number of nodes in a pool. For example:
# isi_gconfig smartpools | grep -i ideal smartpools.diskpools.pool_ideal_size (int) = 20
The most common causes of a neighborhood split are:
- Nodes were added to the node pool and the neighborhood must be split to accommodate them, for example the nodepool went from 39 to 40 (20+20) or from 59 to 60 (20+20+20).
- Nodes were removed from a nodepool into a manual nodepool.
- Compatibility settings were changed, which made some existing nodes incompatible.
After a split, typically the Smartpools/SetProtectPlus and AutoBalance jobs run, restriping files so that the new disk pools are balanced.
The following CLI command can be used to identify the correlation between the cluster’s nodes and OneFS neighborhoods, or failure domains:
# sysctl efs.lin.lock.initiator.coordinator_weights
The command output reports the node composition of each neighborhood (failure_domain), as well as the active nodes (up_nodes) in each, and their relative weighting (weights).
With larger clusters, neighborhoods also help facilitate OneFS’ parallel cluster upgrade option. Parallel upgrade provides upgrade efficiency within node pools on larger clusters, allowing the simultaneous upgrading of a node per neighborhood until the pool is complete . By doing this, the upgrade duration is dramatically reduced, while ensuring that end-users still continue to have full access to their data.
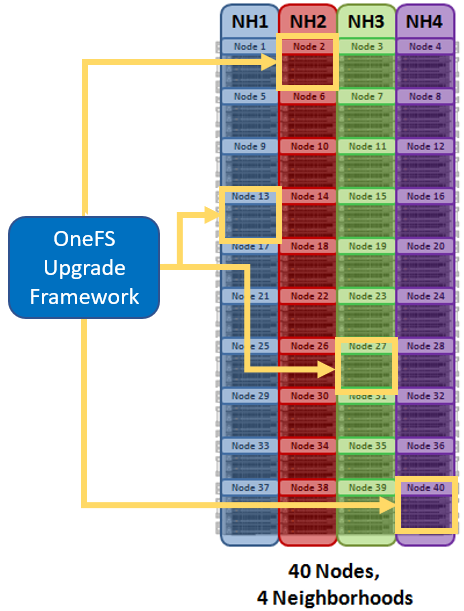
During a parallel upgrade, the upgrade framework selects one node from each neighborhood, to run the upgrade job on simultaneously. So in this case, node 13 from neighborhood 1, node 2 from neighborhood 2, node 27 from neighborhood 3 and node 40 from neighborhood 4 will be upgraded at the same time. Considering they are all in different neighborhoods or failure domains, it will not impact the current running workload. After the first pass completes, the upgrade framework will select another node from each neighborhood and upgrade them, and so on until the cluster is fully upgraded.
For example, consider a hundred node PowerScale H700 cluster. With an ideal layout, there would be 10 neighborhoods, each containing ten nodes. The equation for estimating upgrade a parallel completion time is as follows:
𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 = (𝑝𝑒𝑟 𝑛𝑜𝑑𝑒 𝑢𝑝𝑔𝑟𝑎𝑑𝑒 𝑑𝑢𝑟𝑎𝑡𝑖𝑜𝑛) × (max 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑛𝑜𝑑𝑒𝑠 𝑝𝑒𝑟 𝑛𝑒𝑖𝑔ℎ𝑏𝑜𝑟ℎ𝑜𝑜𝑑)
Assuming an upgrade time of 20 minutes per node, this would be:
20 × 10 = 200 𝑚𝑖𝑛𝑢𝑡𝑒𝑠
So the estimated duration of the hundred node parallel upgrade is 200 minutes, or just under 3 ½ hours. This is in contrast to a rolling upgrade, which would be an order of magnitude greater at 2000 minutes, or almost a day and a half.