There have been several discussion recently around the effects of high capacity utilization on cluster performance. Capacity management is a vital part of OneFS system administration and would seem to warrant a blog article.
Because OneFS is a single, scalable file system, unencumbered by underlying volume management requirements, it can lead to reduce vigilance on cluster capacity utilization. While the cluster will fire alerts before things become critical, not all sites have additional nodes on hand, sitting around waiting for cluster expansion. The reality is there’s a lead time between ordering and taking delivery of new hardware. As such, it pays to be proactive when it comes to cluster capacity management.
When a cluster, or any of its nodepools, becomes more than 90% full, OneFS can experience slower performance and possible workflow interruptions in high-transaction or write-speed-critical operations. Furthermore, when a cluster or pool approaches full capacity (ie. over 95% full), the following issues can arise:
- Substantially slower performance
- Workflow disruptions – failed file operations and inability to write data
- Inability to make configuration changes or run commands to delete data and free up space
Allowing a cluster or pool to fill can put the cluster into a non-operational state that can take significant time (hours, or even days) to correct. Therefore, it is important to keep your cluster or pool from becoming full. To ensure that a cluster or its constituent pools do not run out of space:
- Add new nodes to existing clusters or pools
- Replace smaller-capacity nodes with larger-capacity nodes
- Create more clusters.
OneFS will notify when cluster capacity starts to reach levels of concern. If the warning events and alerts are not heeded, the following error messages can be displayed when attempting to write to a full, or nearly full, cluster or pool:
| Error Message | Where Error is Displayed |
| The operation can’t be completed because the disk “<share name>” is full. | OneFS WebUI, or the command line interface on an NFS client. |
| No space left on device. | OneFS WebUI, or the command line interface on an NFS client, etc. |
| No available space. | OneFS WebUI, or the command line interface on a Windows or SMB client. |
| ENOSPC (error code) | Written to the cluster’s /var/log/messages file. This error code will be embedded in another message. |
| Failed to satisfy layout preference. | Written to the cluster’s /var/log/messages file |
| Disk Quota Exceeded. | Cluster command line interface, or an NFS client when you encounter a Snapshot Reserve limitation. |
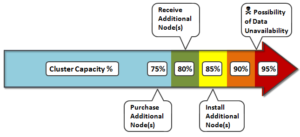
When deciding to add new nodes to an existing cluster or pool, contact your sales team to order the nodes well in advance of the cluster or pool running short on space. The recommendation is to start planning for additional capacity when the cluster or pool reaches 75% full. This will allow sufficient time to receive and install the new hardware, while still maintaining sufficient free space.
Here’s the recommended timeline for cluster capacity planning purposes:
If your data availability and protection SLA varies across different data categories (for example, home directories, file services, etc), ensure that any snapshot, replication and backup schedules are configured accordingly to meet the required availability and recovery objectives, and fit within the overall capacity plan.
Consider configuring a separate accounting quota for /ifs/home and /ifs/data directories (or wherever data and home directories are provisioned) to monitor aggregate disk space usage and issue administrative alerts as necessary to avoid running low on overall capacity.
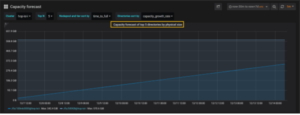
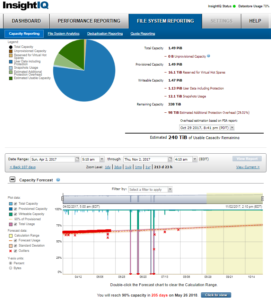
DataIQ and InsightIQ both provide detailed monitoring and trending functionality to help with capacity consumption projections and usage forecasting.
![]()
For optimal performance in any size cluster, the recommendation is to maintain at least 10% free space in each pool of a cluster.
To better protect smaller clusters (containing 3 to 7 nodes) the recommendation is to maintain 15 to 20% free space. A full smartfail of a node in smaller clusters may require more than one node’s worth of space. Keeping 15 to 20% free space can allow the cluster to continue to operate while support assists with recovery plans.
Also, it pays to plan for contingencies: Having a fully updated backup of your data can limit the risk of data loss if a node fails.
Maintaining appropriate protection levels
Ensure your cluster and pools are protected at the appropriate level. Every time you add nodes, re-evaluate protection levels. OneFS includes a ‘suggested protection’ function that calculates a recommended protection level based on cluster configuration, and alerts you if the cluster falls below this suggested level
OneFS supports several protection schemes. These include the ubiquitous +2d:1n, which protects against two drive failures or one node failure. Use the recommended protection level for a particular cluster configuration. This recommended level of protection is clearly marked as ‘suggested’ in the OneFS WebUI storage pools configuration pages, and is typically configured by default.
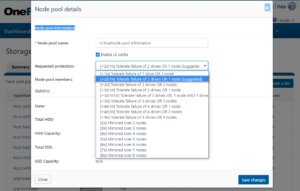
Monitoring cluster capacity
- Configure alerts. Set up event notification rules so that you will be notified when the cluster begins to reach capacity thresholds. Make sure to enter a current email address in order to receive the notifications.
- Monitor alerts. The cluster sends notifications when it has reached 95 percent and 99 percent capacity. On some larger clusters, 5 percent (or even 1 percent) capacity remaining might mean that a lot of space is still available, so you might be inclined to ignore these notifications. However, it is best to pay attention to the alerts, closely monitor the cluster, and have a plan in place to take action when necessary.
- Monitor ingest rate. It’s important to understand the rate at which data is coming in to the cluster or pool. Options to do this include:
- SNMP
- SmartQuotas
- FSAnalyze
- DataIQ/InsightIQ
- Use SmartQuotas to monitor and enforce administrator-defined storage limits. SmartQuotas manages storage use, monitors disk storage, and issues alerts when disk storage limits are exceeded. Although it does not provide the same detail of the file system that FSAnalyze does, SmartQuotas maintains a real-time view of space utilization so that you can quickly obtain the information you need.
- Run FSAnalyze jobs. FSAnalyze is a job-engine job that the system runs to create data for file system analytics tools. FSAnalyze provides details about data properties and space usage within the /ifs directory. Unlike SmartQuotas, FSAnalyze updates its views only when the FSAnalyze job runs. Since FSAnalyze is a fairly low-priority job, it can sometimes be preempted by higher-priority jobs and therefore take a long time to gather all of the data.
Managing data
Regularly archive data that is rarely accessed and delete any unused and unwanted data. Ensure that pools do not become too full by setting up file pool policies to move data to other tiers and pools.
Provisioning additional capacity
To ensure that your cluster or pools do not run out of space, you can create more clusters, replace smaller-capacity nodes with larger-capacity nodes, or add new nodes to existing clusters or pools. If you decide to add new nodes to an existing cluster or pool, contact your sales representative to order the nodes long before the cluster or pool runs out of space. EMC recommends that you begin the ordering process when the cluster or pool reaches 80% used capacity. This will allow enough time to receive and install the new equipment and still maintain enough free space.
Managing snapshots
Sometimes a cluster has many old snapshots that consume significant capacity. Reasons for this include inefficient deletion schedules, degraded cluster preventing job execution, expired SnapshotIQ license, etc. Retaining only the snapshots required to support the data availability and protection SLAs will help guard against unintended capacity utilization.
Ensuring all nodes are supported and compatible
Each version of OneFS supports only certain nodes. Refer to the “OneFS and node compatibility” section of the PowerScale Supportability and Compatibility Guide for a list of which nodes are compatible with each version of OneFS. When upgrading OneFS, make sure that the new version supports your existing nodes. If it does not, you might need to replace the nodes.
Space and performance are optimized when all nodes in a pool are compatible. When new nodes are added to a cluster, OneFS automatically provisions nodes into pools with other nodes of compatible type, hard drive capacity, SSD capacity, and RAM. Occasionally, however, the system might put a node into an unexpected location. If you believe that a node has been placed into a pool incorrectly, contact Dell Technical Support for assistance. Different versions of OneFS have different rules regarding what makes nodes compatible
Enabling Virtual Hot Spare and Spillover
OneFS also provides a Virtual Hot Spare (VHS), who’s purpose is to keep space in reserve in case you need to smartfail drives when the cluster gets close to capacity. Enabling VHS will not give you more free space, but it will help protect your data in the event that space becomes scarce. VHS is enabled by default. It’s strongly recommended that you do not disable VHS unless directed by a Support engineer. If you disable VHS in order to free some space, the space you just freed will probably fill up again very quickly with new writes. At that point, if a drive were to fail, you might not have enough space to smartfail the drive and re-protect its data, potentially leading to data loss. If VHS is disabled and you upgrade OneFS, VHS will remain disabled. If VHS is disabled on your cluster, first check to make sure the cluster has enough free space to safely enable VHS, and then enable it.
Spillover allows data that is being sent to a full pool to be diverted to an alternate pool. Spillover is enabled by default on clusters that have more than one pool. If you have a SmartPools license on the cluster, you can disable Spillover. However, it is recommended that you keep Spillover enabled. If a pool is full and Spillover is disabled, you might get a “no space available” error but still have a large amount of space left on the cluster.
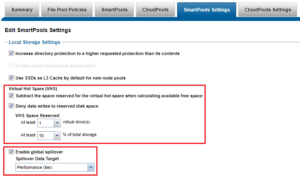
Run OneFS Healthchecks
Regularly run and review the OneFS health checks. These can be easily configured and managed from either the WebUI or CLI:
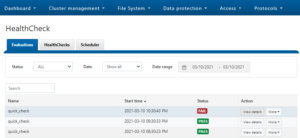
Use OneFS Healthchecks to confirm there are no current cluster issues and that OneFS’ configuration is as expected.