Received a couple of recent enquiries around how to best accommodate big, unstructured datasets and varied workloads, so it seemed like an interesting topic to cover in a blog article.
Essentially, when it comes to designing and scaling large PowerScale clusters for large quantities and growth rates of data, there are some key tenets to bear in mind. These include:
- Strive for simplicity
- Plan ahead
- Just because you can doesn’t necessarily mean you should
Distributed systems tend to be complex by definition, and this is amplified at scale. OneFS does a good job of simplifying cluster administration and management, but a solid architectural design and growth plan is crucial. Because of its single, massive volume and namespace, OneFS is viewed by many as a sort of ‘storage Swiss army knife’. Left unchecked, this methodology can result in unnecessary complexities as a cluster scales. As such, decision making that favors simplicity is key.
Despite OneFS’ extensibility, allowing a PowerScale system to simply grow organically into a large cluster often results in various levels of technical debt. In the worst case, some issues may have grown so large that it becomes impossible to correct the underlying cause. This is particularly true in instances where a small cluster is initially purchased for an archive or low performance workload and with a bias towards cost optimized storage. As the administrators realize how simple and versatile their clustered storage environment is, more applications and workflows are migrated to OneFS. This kind of haphazard growth, such as morphing from a low-powered, near-line platform into something larger and more performant, can lead to all manner of scaling challenges. However, compromises, living with things, or fixing issues that could have been avoided can usually be mitigated by starting out with a scalable architecture, workflow and expansion plan.
Beginning the process with a defined architecture, sizing and expansion plan is key. What do you anticipate the cluster, workloads, and client access levels will look like in six months, one year, three years, or five years? How will you accommodate the following as the cluster scales?
- Contiguous rack space for expansion
- Sufficient power & Cooling
- Network infrastructure
- Backend switch capacity
- Availability SLAs
- Serviceability and spares plan
- Backup and DR plans
- Mixed protocols
- Security, access control, authentication services, and audit
- Regulatory compliance and security mandates
- Multi-tenancy and separation
- Bandwidth segregation – client I/O, replication, etc.
- Application and workflow expansion
There are really two distinct paths to pursue when initially designing an OneFS clustered storage architecture for a large and/or rapidly growing environment – particularly one that includes a performance workload element to it. These are:
- Single Large Cluster
- Storage Pod Architecture
A single large, or extra-large, cluster is often deployed to support a wide variety of workloads and their requisite protocols and performance profiles – from primary to archive – within a single, scalable volume and namespace. This approach, referred to as a ‘data lake architecture’, usually involves more than one style of node.
OneFS can support up to fifty separate tenants in a single cluster, each with their own subnet, routing, DNS, and security infrastructure. OneFS’ provides the ability to separate data layout with SmartPools, export and share level segregation, granular authentication and access control with multi-tenant access zones, and network partitioning with SmartConnect, subnets, and VLANs.
Furthermore, analytics workloads can easily be run against the datasets in a single location and without the need for additional storage and data replication and migration.
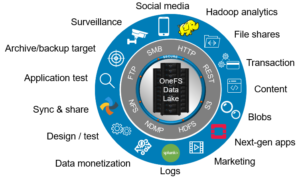
For the right combination of workloads, the data lake architecture has many favorable efficiencies of scale and centralized administration.
Another use case for large clusters is in a single workflow deployment, for example as the content repository for the asset management layer of a content delivery workflow. This is a considerably more predictable, and hence simpler to architect, environment that the data lake.
Often, as in the case of a MAM for streaming playout for example, a single node type is deployed. The I/O profile is typically heavily biased towards streaming reads and metadata reads, with a smaller portion of writes for ingest.
There are trade-offs to be aware of as cluster size increases into the extra-large cluster scale. The larger the node count, the more components are involved, which increases the likelihood of a hardware failure. When the infrastructure becomes large and complex enough, there’s more often than not a drive failing or a node in an otherwise degraded state. At this point, the cluster can be in a state of flux such that composition, or group, changes and drive rebuilds/data re-protects will occur frequently enough that they can start to significantly impact the workflow.
Higher levels of protection are required for large clusters, which has a direct impact on capacity utilization. Also, cluster maintenance becomes harder to schedule since many workflows, often with varying availability SLAs, need to be accommodated.
Additional administrative shortcomings that also need to be considered when planning on an extra-large cluster include that InsightIQ only supports monitoring clusters of up to eighty nodes and the OneFS Cluster Event Log (CELOG) and some of the cluster WebUI and CLI tools can prove challenging at an extra-large cluster scale.
That said, there can be wisdom in architecting a clustered NAS environment into smaller buckets and thereby managing risk for the business vs putting the ‘all eggs in one basket’. When contemplating the merits of an extra-large cluster, also consider:
- Performance management,
- Risk management
- Accurate workflow sizing
- Complexity management.
A more practical approach for more demanding, HPC, and high-IOPS workloads often lies with the Storage Pod architecture. Here, design considerations for new clusters revolve around multiple (typically up to 40 node) homogenous clusters, with each cluster itself acting as a fault domain – in contrast to the monolithic extra-large cluster described above.
Pod clusters can easily be tailored to the individual demands of workloads as necessary. Optimizations per storage pod can include size of SSDs, drive protection levels, data services, availability SLAs, etc. In addition, smaller clusters greatly reduce the frequency and impact of drive failures and their subsequent rebuild operations. This, coupled with the ability to more easily schedule maintenance, manage smaller datasets, simplify DR processes, etc, can all help alleviate the administrative overhead for a cluster.
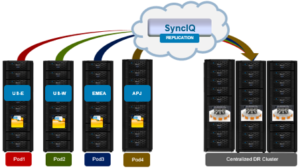
A Pod infrastructure can be architected per application, workload, similar I/O type (ie. streaming reads), project, tenant (ie. business unit), availability SLA, etc. This pod approach has been successfully adopted by a number of large PowerScale customers in industries such as semiconductor, automotive, life sciences, and others with demanding performance workloads.
This Pod architecture model can also fit well for global organizations, where a cluster is deployed per region or availability zone. An extra-large cluster architecture can be usefully deployed in conjunction with Pod clusters to act as a centralized disaster recovery target, utilizing a hub and spoke replication topology. Since the centralized DR cluster will be handling only predictable levels of replication traffic, it can be architected using capacity-biased nodes.
Before embarking upon either a data lake or Pod architectural design, it is important to undertake a thorough analysis of the workloads and applications that the cluster(s) will be supporting.
Despite the flexibility offered by the data lake concept, not all unstructured data workloads or applications are suitable for a large PowerScale cluster. Each application or workload that is under consideration for deployment or migration to a cluster should be evaluated carefully. Workload analysis involves reviewing the ecosystem of an application for its suitability. This requires an understanding of the configuration and limitations of the infrastructure, how clients see it, where data lives within it, and the application or use cases in order to determine:
- How the application works?
- How users interact with the application?
- What is the network topology?
- What are the workload-specific metrics for networking protocols, drive I/O, and CPU & memory usage?