Received a couple of recent enquires about the role and effects of cluster quorum in OneFS. So thought it might be useful to revisit this, and associated concepts, in an article.
The premise was this:
A 3 node cluster at +2d:1n or +1n protection can run fine in a degraded mode with only two active nodes and one failed node:
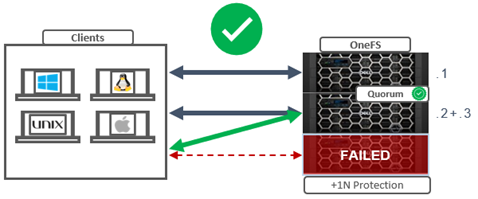
Given the above, shouldn’t a 4 node cluster at +2n also be able to sustain a two node failure and run fine in degraded state with two active nodes?
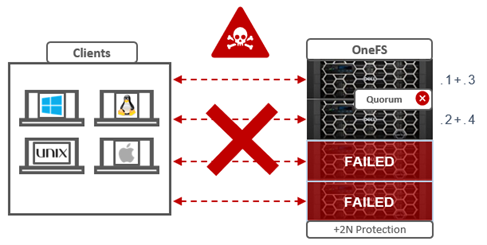
Spoiler alert: The answer is no, and the reason is the OneFS cluster quorum requirement.
So what’s going on here?
In order for a cluster to properly function and accept data writes, a quorum of nodes must be active and responding. A quorum is defined as a simple majority: a cluster with N nodes must have ⌊N/2⌋+1 nodes online in order to allow writes. For example, in a seven-node cluster, four nodes would be required for a quorum. If a node or group of nodes is up and responsive, but is not a member of a quorum, it runs in a read-only state.
OneFS uses a quorum to prevent ‘split-brain’ conditions that can be introduced if the cluster should temporarily divide into two clusters. By following the quorum rule, the architecture guarantees that regardless of how many nodes fail or come back online, if a write takes place, it can be made consistent with any previous writes that have ever taken place. The quorum also dictates the number of nodes required in order to move to a given data protection level. For an erasure-code-based protection-level of 𝑁+𝑀, the cluster must contain at least 2𝑀+1 nodes. For example, a minimum of five nodes is required for a +2n configuration:
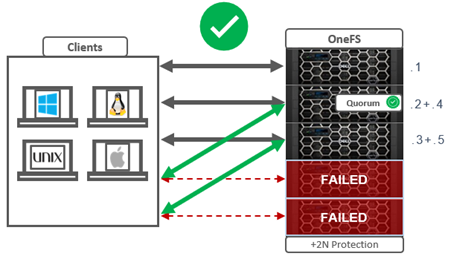
This allows for a simultaneous loss of two nodes while still maintaining a quorum of three nodes for the cluster to remain fully operational.
If a cluster does drop below quorum, the file system will automatically be placed into a protected, read-only state, denying writes, but still allowing read access to the available data.
Within OneFS, quorum is a property of the group management protocol (GMP) group which helps enforce consistency across node disconnects. It is very similar to the common definition of quorum in distributed systems. It can be shown that requiring ⌊𝑁/2⌋+ 1 replicas to be available can guarantee that no updates are lost. Quorum performs this specific purpose within OneFS.
Since both nodes and drives in OneFS may be readable, but not writable, OneFS actually has two quorum properties:
| Type | Description |
| Read quorum | Read quorum is defined as having ⌊𝑁/2⌋ + 1 nodes readable. |
| Write quorum | Write quorum is defined as having at least ⌊𝑁/2⌋ + 1 nodes writable. |
Under the hood, OneFS read quorum is represented by the sysctl ‘efs.gmp.has_quorum’, and write quorum by ‘efs.gmp.has_super_block_quorum’. For example:
# sysctl efs.gmp.has_quorum efs.gmp.has_quorum: 1 # sysctl efs.gmp.has_super_block_quorum efs.gmp.has_super_block_quorum: 1
In the above example, the value of ‘1’ for each confirms that the cluster currently has both read and write quorum respectively.
Note that any nodes that are not in a cluster’s main quorum group form multiple groups. A group of nodes with quorum is referred to as the ‘majority side’. Similarly, any node group without quorum is termed a ‘minority side’. By definition, there can only be one majority group, but there may be multiple minority groups. A group which has one or more components in a failed state is called ‘degraded’. The degraded property is frequently used as an optimization to avoid checking the capabilities of each component. The term ‘degraded’ is also used to refer to components without their maximum capabilities.
For example, consider the earlier 4-node cluster example with a protection level of +2n and two nodes down. Even though the protection level can theoretically sustain two node failures, the minimum cluster size has been violated, hence the cluster cannot write due to lack of quorum. The following table lists various OneFS protection levels and their associated minimum cluster or pool sizes and quorum counts:
| FEC Protection level | Failure Tolerance | Minimum Cluster/Pool Size | Minimum Quorum Size |
| +1 | Tolerate failure of 1 drive OR 1 node | 3 nodes | 2 nodes |
| +2 | Tolerate failure of 2 drives OR 2 nodes | 5 nodes | 3 nodes |
| +3 | Tolerate failure of 3 drives or 3 nodes | 7 nodes | 4 nodes |
| +4 | Tolerate failure of 4 nodes | 9 nodes | 5 nodes |
The OneFS Job Engine also includes a process called Collect, which acts as an orphaned block collector. If a cluster splits during a write operation, some blocks that were allocated for the file may need to be re-allocated on the quorum side. This will ‘orphan’ allocated blocks on the non-quorum side. When the cluster re-merges, the job engine’s Collect job locates these orphaned blocks through a parallelized mark-and-sweep scan and reclaims them as free space for the cluster.
File system operations typically query a GMP group several times before completing. A group may change over the course of an operation, but the operation needs a consistent view. This is provided by the group info, which is the primary interface modules use to query group state.
The efs.gmp.group sysctl can be queried to determine the current group state of a cluster. For example:
# sysctl efs.gmp.group
efs.gmp.group: <8f8f4b> (92) :{ 1-14:0-14, 15:0-13, 16-19:0-14, 20:0-13, 21-33:0-14, 34:0-4,6-10,12-14, 35-36:0-14, 37-48:0-19, 49-60:0-14, 61-62:0-13, 63-81:0-14, 82:0-7,9-14, 83-87:0-14, 88:0-13, 89-91:0-14, 92:0-1,3-14, smb: 1-92, nfs: 1-92, swift: 1-92, all_enabled_protocols: 1-92, isi_cbind_d: 1-92, lsass: 1-92, s3: 1-92, external_connectivity: 1-92 }
As shown in this large cluster example above, the output includes the GMP’s group state, but also information about services provided by nodes in the cluster. This allows nodes in the cluster to discover when services change state on other nodes and take the appropriate action when this happens. An example is SMB lock expiry, which uses GMP service information to clean up locks held by other nodes when the service owning the lock goes down.
Additional detailed current GMP state information can be gleaned from the output of the following sysctl:
# sysctl efs.gmp.current_info
Processes change the service state in GMP by opening and closing service devices. A particular service will transition from down to up in the GMP group when it opens the file descriptor for a device. Closing the service file descriptor will trigger a group change that reports the service as down. A process can explicitly close the file descriptor if it chooses, but most often the file descriptor will remain open for the duration of the process and closed automatically by the kernel when it terminates.
OneFS depends on a consistent view of a cluster’s group state. For example, in addition to read and write quorum, other decisions, such as choosing lock coordinators, are made assuming all nodes have the same coherent notion of the cluster.
As such, an understanding of OneFS quorum, groups, and their related group change messages allows you to determine the current health of a cluster – as well as reconstruct the cluster’s history when troubleshooting issues that involve cluster stability, network health, and data integrity.
Group changes originate from multiple sources, depending on the particular state. Drive group changes are initiated by the drv module. Service group changes are initiated by processes opening and closing service devices. Each group change creates a new group ID, comprising a node ID and a group serial number. This group ID can be used to quickly determine whether a cluster’s group has changed, and is invaluable for troubleshooting cluster issues, by identifying the history of group changes across the nodes’ log files.
GMP provides coherent cluster state transitions using a process similar to two-phase commit, with the up and down states for nodes being directly managed by the GMP. The Remote Block Manager (RBM) provides the communication channel that connect devices in the OneFS. When a node mounts /ifs it initializes the RBM in order to connect to the other nodes in the cluster, and uses it to exchange GMP Info, negotiate locks, and access data on the other nodes.
Before /ifs is mounted, a ‘cluster’ is just a list of MAC and IP addresses in array.xml, managed by ibootd when nodes join or leave the cluster. When mount_efs is called, it must first determine what it‘s contributing to the file system, based on the information in drives.xml. After a cluster (re)boot, the first node to mount /ifs is immediately placed into a group on its own, with all other nodes marked down. As the Remote Block Manager (RBM) forms connections, the GMP merges the connected nodes, enlarging the group until the full cluster is represented. Group transactions where nodes transition to UP are called a ‘merge’, whereas a node transitioning to down is called a split.