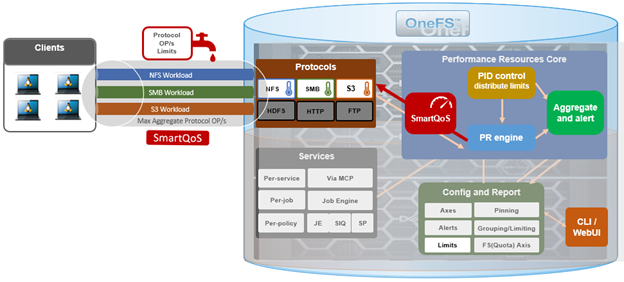
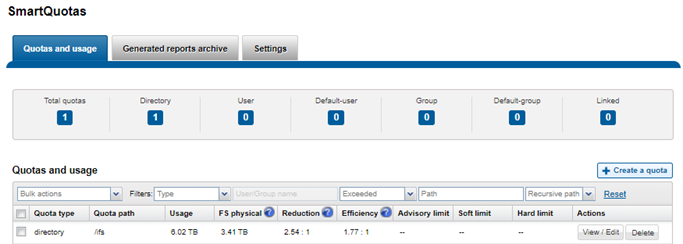
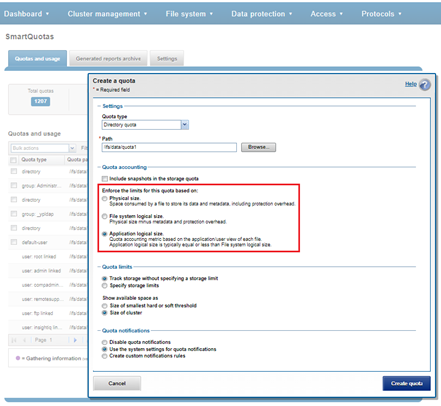
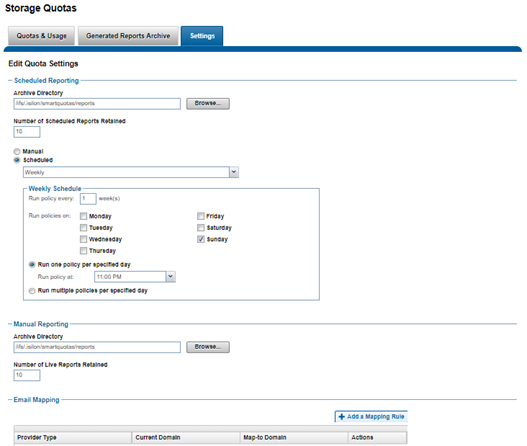
The SmartQoS Protocol Ops limits architecture, introduced in OneFS 9.5, involves three primary capabilities:
- Resource tracking
- Resource limit distribution
- Throttling
Under the hood, the OneFS protocol heads (NFS, SMB and S3) identify and track how many protocol operations are being processed through a specific export or share. The existing partitioned performance (PP) reporting infrastructure is leveraged for cluster wide resource usage collection, limit calculation and distribution, along with new OneFS 9.5 functionality to support pinned workload protocol Ops limits.
The protocol scheduling module (LwSched) has an inbuilt throttling capability that allows the execution of individual operations to be delayed by temporarily pausing them, or ‘sleeping’. Additionally, in OneFS 9.5, the partitioned performance kernel modules have also been enhanced to calculate ‘sleep time’ based on operation count resource information (requested, average usage etc.) – both within the current throttling window, and for a specific workload.
The fundamental SmartQoS workflow can be characterized as follows:
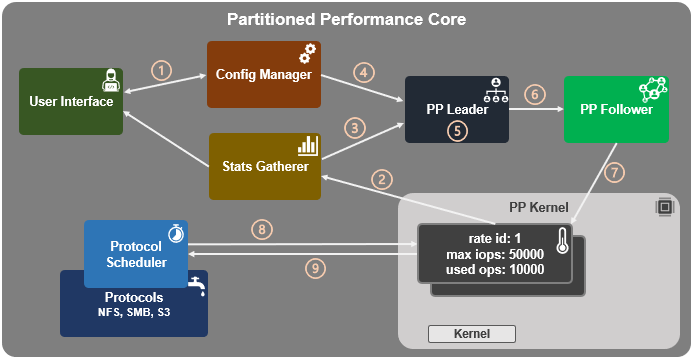
- Configuration via CLI, pAPI, or WebUI.
- Statistics gatherer obtains Op/s data from the partitioned performance (PP) kernel.
- Stats gatherer communicates Op/s data to PP leader service.
- Leader queries config manager for per-cluster rate limit.
- Leader calculates per-node limit.
- PP follower service is notified of per-node Op/s limit.
- Kernel is informed of new per-node limit.
- Work is scheduled with rate-limited resource.
- Kernel returns sleep time, if needed.
When an admin configures a per-cluster protocol Ops limit, the statistics gathering service, isi_stats_d, begins collecting workload resource information every 30 seconds by default from the partitioned performance (PP) kernel on each node in the cluster and notifies the isi_pp_d leader service of this resource info. Next, the leader gets the per-cluster protocol Ops limit plus additional resource consumption metrics from the isi_acct_cpp service via isi_tardis_d, the OneFS cluster configuration service and calculates the protocol Ops limit of each node for the next throttling window. It then instructs the isi_pp_d follower service on each node to update the kernel with the newly calculated protocol Ops limit, plus a request to reset throttling window.
Upon receipt of a scheduling request for a work item from the protocol scheduler (LwSched), the kernel calculates the required ‘sleep time’ value, based on the current node protocol Ops limit and resource usage in the current throttling window. If insufficient resources are available, the thread for work item execution thread is put to sleep for a specific interval returned from PP kernel. If resources are available, or the thread is reactivated from sleeping, it executes the work item and reports the resource usages statistics back to PP, releasing any scheduling resources it may own.
SmartQoS can be configured through either the CLI, platform API, or WebUI, and OneFS 9.5 introduces a new SmartQoS WebUI page to support this. Note that SmartQoS is only available once an upgrade to OneFS 9.5 has been committed, and any attempt to configure or run the feature prior to upgrade commit will fail with the following message:
# isi performance workloads modify DS1 -w WS1 --limits protocol_ops:50000 Setting of protocol ops limits not available until upgrade has been committed
Once a cluster is running OneFS 9.5 and the release is committed, the SmartQoS feature is enabled by default. This, and the current configuration, can be confirmed using the following CLI command:
# isi performance settings view Top N Collections: 1024 Time In Queue Threshold (ms): 10.0 Target read latency in microseconds: 12000.0 Target write latency in microseconds: 12000.0 Protocol Ops Limit Enabled: Yes
In OneFS 9.5, the ‘isi performance settings modify’ CLI command now includes a ‘protocol-ops-limit-enabled’ parameter to allow the feature to be easily disabled (or re-enabled) across the cluster. For example:
# isi performance settings modify --protocol-ops-limit-enabled false protocol_ops_limit_enabled: True -> False
Similarly, the ‘isi performance settings view’ CLI command has been extended to report the protocol OPs limit state:
# isi performance settings view * Top N Collections: 1024 Protocol Ops Limit Enabled: Yes
In order to set a protocol OPs limit on workload from the CLI, the ‘isi performance workload pin’ and ‘isi performance workload modify’ commands now accept an optional ‘–limits’ parameter. For example, to create a pinned workload with the ‘protocol_ops’ limit set to 10000:
# isi performance workload pin test protocol:nfs3 --limits protocol_ops:10000
Similarly, to modify an existing workload’s ‘protocol_ops’ limit to 20000:
# isi performance workload modify test 101 --limits protocol_ops:20000 protocol_ops: 10000 -> 20000
When configuring SmartQoS, always be cognizant of the fact that it is a powerful throttling tool which can be applied to significant areas of a cluster’s data and userbase. For example, protocol OPs limits can be configured for metrics such as ‘path:/ifs’, which would affect the entire /ifs filesystem, or ‘zone_name:System’ which would limit the System access zone and all users within it.
While such configurations are entirely valid, they would have a significant, system-wide impact. As such, caution should be exercised when configuring SmartQoS to avoid any inadvertent, unintended or unexpected performance constraints.
To clear a protocol Ops limit on workload, the ‘isi performance workload’ modify CLI command has been extended to accept an optional ‘–noprotocol-ops-limit’ argument. For example:
# isi performance workload modify test 101 --no-protocol-ops-limit protocol_ops: 20000 -> 18446744073709551615
Note that the value of ‘18446744073709551615’ in the command output above represents ‘NO_LIMIT’ set.
A workload’s protocol Ops limit can be viewed using the ‘isi performance workload list’ and ‘isi performance workload view’ CLI commands, which have been modified in OneFS 9.5 to display the limits appropriately. For example:
# isi performance workload list test ID Name Metric Values Creation Time Impact Limits --------------------------------------------------------------------- 101 - protocol:nfs3 2023-02-02T22:35:02 - protocol_ops:20000 --------------------------------------------------------------------- # isi performance workload view test 101 ID: 101 Name: - Metric Values: protocol:nfs3 Creation Time: 2023-02-02T22:35:02 Impact: - Limits: protocol_ops:20000
In the next article in this series, we’ll step through an example SmartQoS configuration and verification from both the CLI and WebUI.