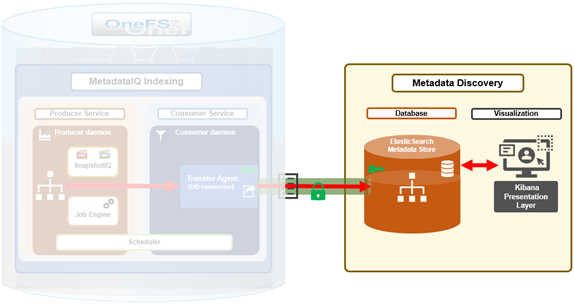
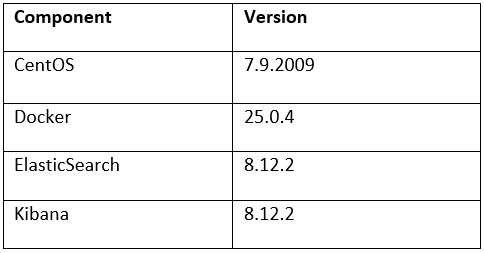
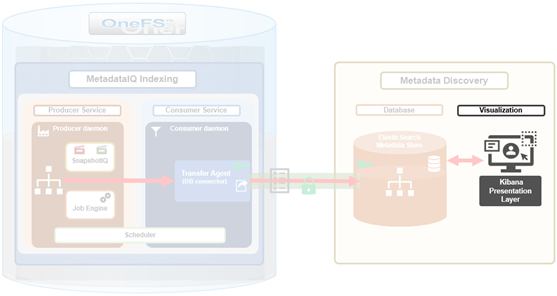
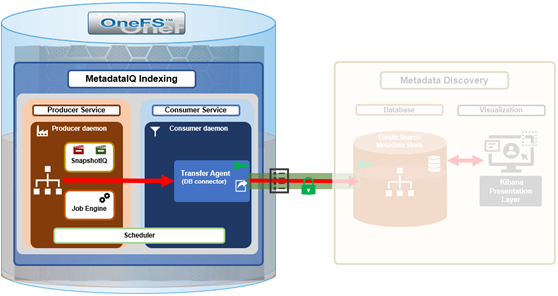
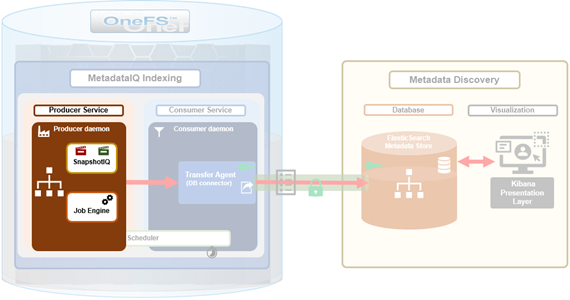
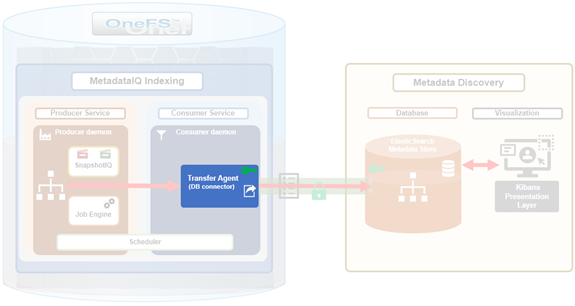
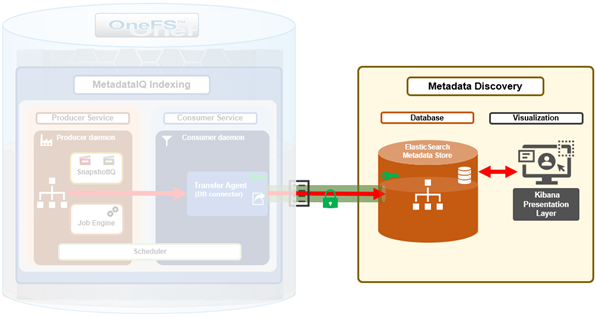
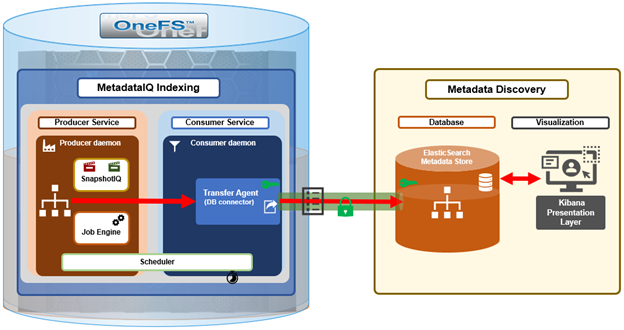
The previous article in this series focused on provisioning and configuring MetadataIQ. Now, in this final article in this series, we turn our attention to the tools and utilities that are helpful in monitoring and troubleshooting MetadataIQ.
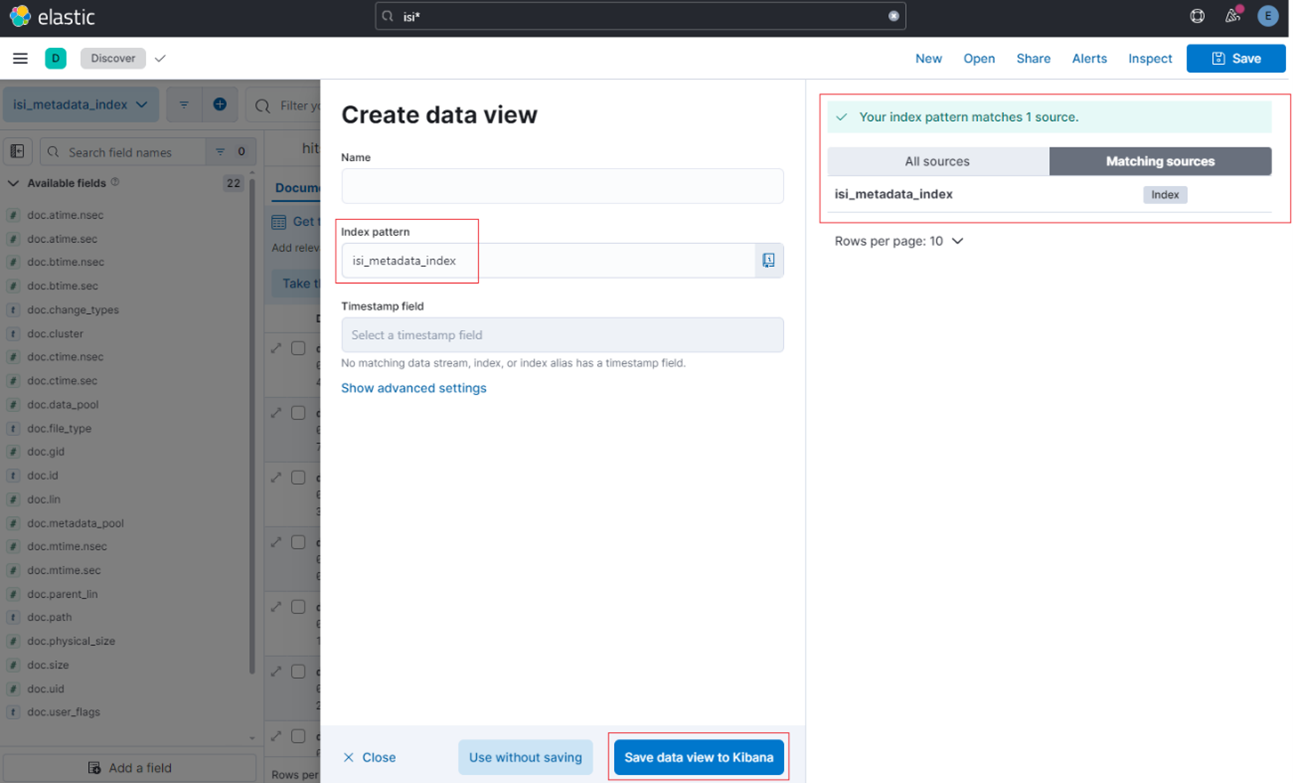
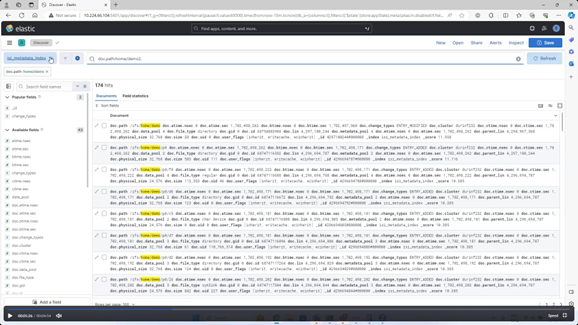
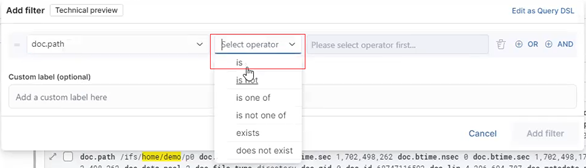
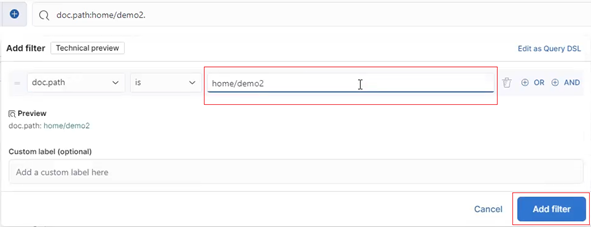
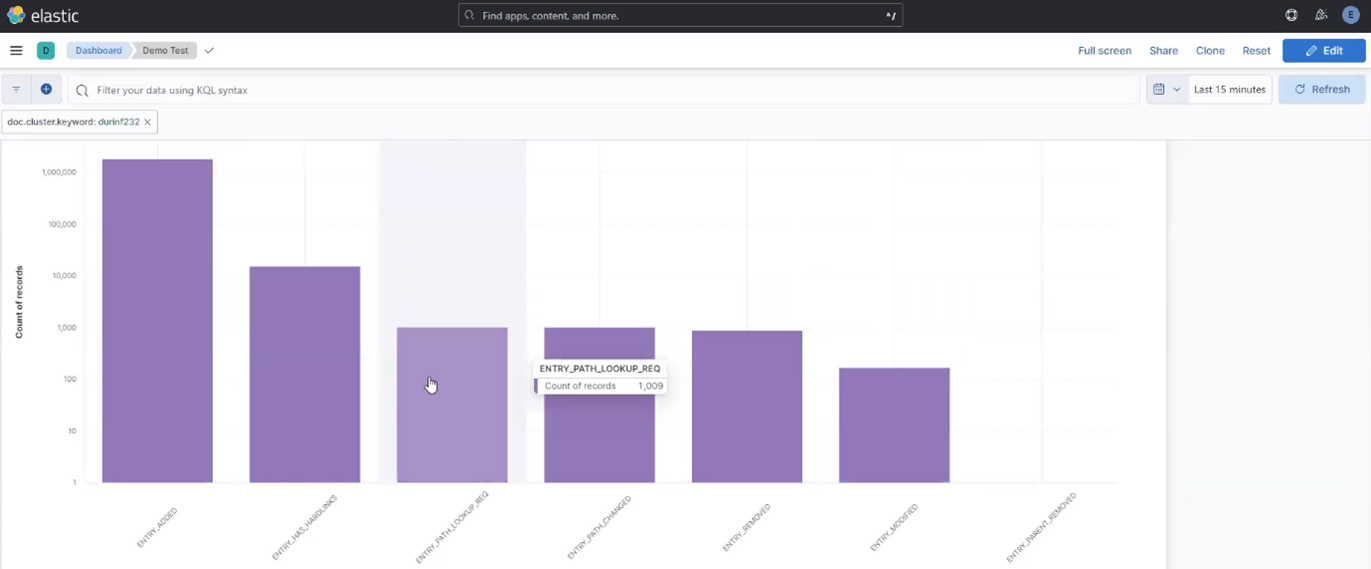
The actual metadata that MetadataIQ provides to the ElasticSearch database can be queried from the cluster CLI with the following command syntax:
# isi_metadataiq_transfer --show-mappings
MetadataIQ uses the Job Engine’s ChangelistCreate job and checkpoint (CCP) files to both track work progress and recover from unexpected termination. The ChangelistCreate job is run with its default impact and priority settings, and job progress can be monitored via the ‘isi job jobs view’ CLI command. Additionally, the job can also be modified, paused, and resumed. Once complete or terminated, a report of the job’s execution and progress can be accessed with the ‘isi job reports’ CLI syntax.
If needed, a ChangelistCreate job instance that is found to be in a paused or indeterminate state can be cancelled as follows. In this example, the culprit is job ID 51:
# isi job list ID Type State Impact Policy Pri Phase Running Time --------------------------------------------------------------------------- 51 ChangelistCreate User Paused Low LOW 10 4/4 2s --------------------------------------------------------------------------- Total: 1 # isi job cancel 51
Another useful MetadataIQ management lever is the ability to constrain MetadataIQ to a subset of cluster resources, along with the associated impact control ramifications. The ‘excluded_lnns’ option allows cluster admins to explicitly define which nodes MetadataIQ can run on. For example, the following CLI command will configure a MetadataIQ exclusion on the nodes with LNNs 3 and 5:
# isi metadataiq settings modify --excluded-lnns 3,5 # isi metadataiq settings view | grep -i lnn Excluded Lnns: 3, 5
On excluded nodes, the MetadataIQ producer log will typically contain entries of the form:
2024-09-29T18:39:15.109639+00:00 <3.3> TME-1(id1) isi_metadataiq_consumer_d[72402]: isi_metadataiq_consumer_d daemon is not allowed to run on current node, exiting..
Note that, in a PowerScale cluster, a node’s LNN (logical node number) is not always the same as its node ID, as reported by utilities like ‘isi status’. The ‘isi_nodes %{id} , %{lnn}’ CLI command can be used to correlate the two node numbering schemes
For a cluster where not all the nodes are connected to the front-end network (NANON), MetadataIQ automatically bypasses the unconnected node(s), so an LNN exclusion does not need to be manually configured in this case.
The ‘isi metadataiq’ CLI command also provides a ‘reset’ option, which can be used to remove any existing configuration settings, including the platform API parameters:
# isi metadataiq reset
The following configuration and log files can be helpful when investigating MetadataIQ issues:

While MetadataIQ is running, the following actions can be performed periodically to confirm proper operation or troubleshoot an issue:
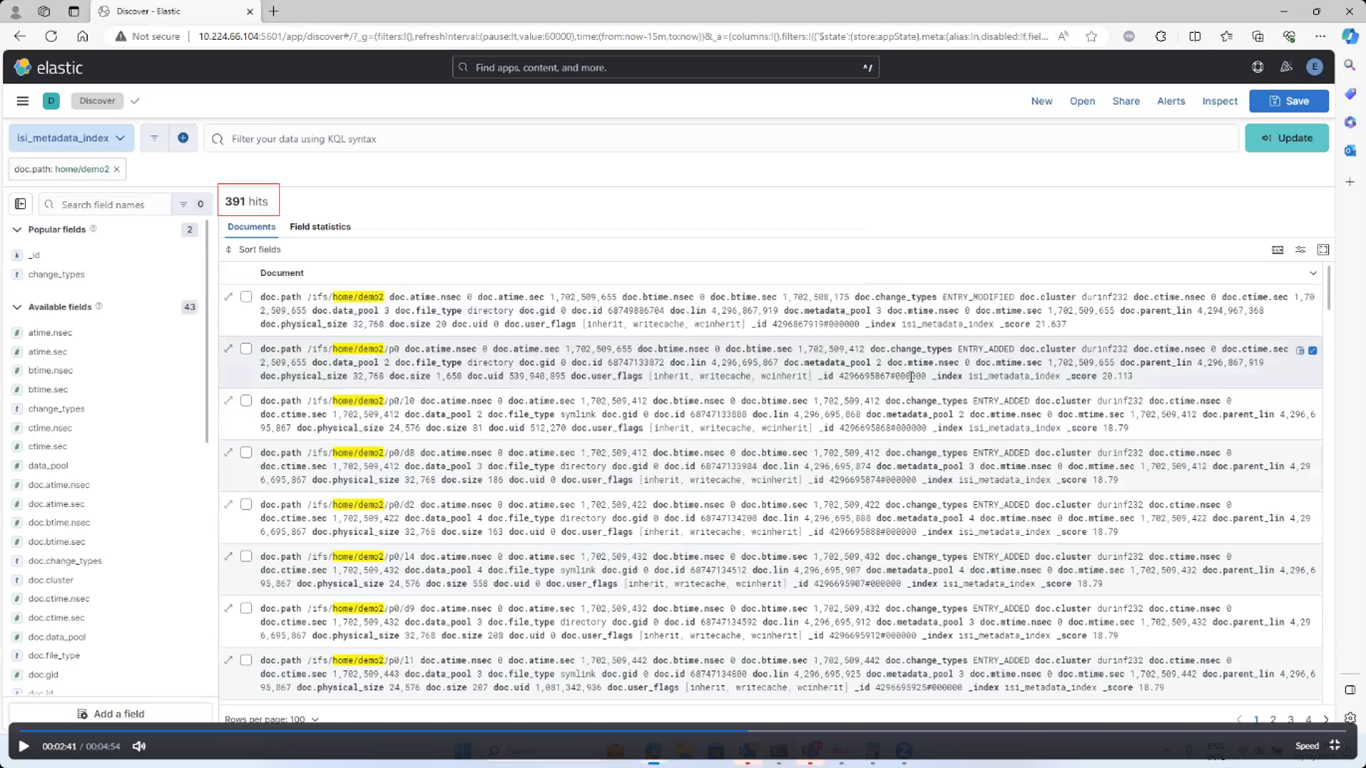
- Regularly monitor the ElasticSearch database with queries, ensuring the number of entries are in line with expectations.
- Check the health of the ChangelistCreate job(s).
# isi job jobs list | grep -i ChangelistCreate ID Type State Impact Pri Phase Running Time ----------------------------------------------------------------- 3 ChangelistCreate Running Low 5 2/4 9s -----------------------------------------------------------------
- Monitor SnapshotIQ to ensure that there’s no buildup of MetadataIQ snapshots.
# isi snapshot snapshots list | grep -i metadataiq 3278 MetadataIQ_1730914225 /ifs/data 3290 MetadataIQ_1730915287 /ifs/data ...
Note that, in a healthy environment, if there are more than two MetadataIQ snapshots, the inactive snapshot(s) should automatically be removed during the next producer cycle
- Optionally, dump the checkpoint file:
# cat /ifs/.ifsvar/isi_metadata_index/checkpoint.json
The ChangelistCreate job report can be a particularly useful place to investigate. For example:
# isi job jobs list | grep 110 110 ChangelistCreate Waiting Low LOW 5 2/4 3h 35m # isi job reports view 110 ChangelistCreate[110] phase 1 (2024-09-30T00:29:16) --------------------------------------------------- Elapsed time 7384 seconds (2H3m4s) Working time 187 seconds (3m7s) Errors 0 Older snapid 152 Newer snapid 336 Mode 1 Entries found 2258681 Entries added 489031 ChangelistCreate[110] phase 2 (2024-10-01T19:24:04) --------------------------------------------------- Elapsed time 154487 seconds (1D18H54m47s) Working time 12729 seconds (3H32m9s) Errors 0 Older snapid 152 Newer snapid 336 Mode 1 Entries found 0 Entries added 8716044 ChangelistCreate[110] Job Summary --------------------------------- Final Job State System Cancelled Phase Executed 2
Similarly, a ChangeListCreate job’s status (in this case job ID 110 above) is also reported in the MetadataIQ producer Log, in the form of:
2024-10-01T18:48:45.933223+00:00 <3.7> TME-1 (id1) isi_metadataiq_producer_d[83055]: Job id: 110, status : 200, body { "jobs" : [ { "control_state" : "paused_priority", "create_time" : 1727648385, "current_phase" : 2, "description" : "", "human_desc" : "", "id" : 110, "impact" : "Low", "participants" : [ 1, 2, 3, 4 ], "policy" : "LOW", "priority" : 5, "progress" : "Task results: found 0, added 8716044, 0 errors", "retries_remaining" : 0, "running_time" : 12916, "start_time" : 1727648770, "state" : "paused_priority", "total_phases" : 4, "type" : "ChangelistCreate" } ] }
2024-10-01T18:48:45.933317+00:00 <3.7> TME-1(id1) isi_metadataiq_producer_d[83055]: Job 110 state Waiting
The changelist that is created by the producer daemon should automatically be cleaned up after the subsequent metadata transfer cycle completes. The following CLI command can be used to report a cluster’s changelists:
# isi_changelist_mod -l
If a number of changelists are reported, the consumer daemon may be unable to transfer fully or otherwise keep up with changelist generation. Alternatively, some other cluster process may also be generating changelists.
If, for some reason, a MetadataIQ cycle fails in its entirety, an error of the following form will be reported:
Too many errors (...) encountered in this cycle. Failing this cycle and waiting for the next scheduled run
As described, no administrative intervention is required and MetadataIQ will automatically resume during its next scheduled run.
Similarly, Job Engine issues will typically result in the ChangelistCreate job being retried four times by default. After four failures, the following error is reported and job execution withheld until the next scheduled MetadataIQ cycle run.
ChangelistCreate job failed 4 times; giving up until next cycle
Note that the preferred job retry threshold can be specified with the ‘isi metadataiq settings modify –changelist-job-retries <integer>’ CLI syntax
For ElasticSearch server issues, such as the [500 document(s) failed to index] error, the following OneFS CLI utility can be used to verify the configuration and connectivity:
# isi_metadataiq_transfer –check
If for some reason a cluster’s /ifs file system has been placed into read-only mode, MetadataIQ will be unable to function and the following error message will be reported:
Error: Failed to open leader lock file (...): Read-only file system
If necessary, the MetadataIQ configuration can easily be completely removed. This can be required in the unlikely event that the following error message is reported:
In unrecoverable state. Please restart the MetadataIQ service or run a reset/resync
To start from scratch, first run a reset. For example:
# isi metadataiq reset
Once reset, the desired MetadataIQ configuration settings can be (re)applied via the ‘modify’ option:
# isi metadataiq settings modify --verify-certificate <boolean> --ca-certificate-path <string> --api-key <string> --hostname <string> --host-port <integer> --path <string> --schedule <string>