Amongst the bevy of new functionality introduced in OneFS 9.4 is SmartSync v1, and we’ll be taking a look at this new replication product over the course of the next couple of blog articles.
So, the new SmartSync Datamover enables flexible data movement and copying, incremental resyncs, and push and pull data transfer of file data between PowerScale clusters. Additionally, SmartSync CloudCopy also enables the copying of file-to-object data from a source cluster to a cloud object storage target. Cloud object targets include AWS S3 and Microsoft Azure, as well as Dell ECS.
Having a variety of target destination options allows multiple copies of a dataset to be stored across locations and regions, both on and off-prem, providing increased data resilience and the ability to rapidly recover from catastrophic events.
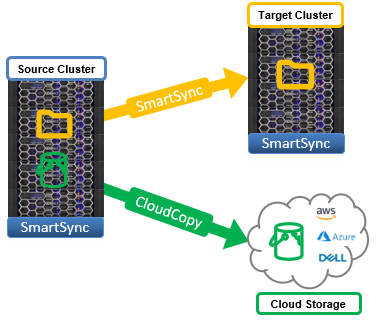
CloudCopy uses HTTP as the data replication transport layer to cloud storage, while cluster to cluster SmartSync leverages a proprietary RCP-based messaging system. In addition to the replication of the actual data, SmartSync also preserves the common file attributes including Windows ACLs, POSIX permissions and attributes, creation times, extended attributes, alternate data streams, etc.
In order to use SmartSync, SyncIQ must be licensed and active across all nodes in the cluster. Additionally, a cluster account with the ISI_PRIV_DATAMOVER privilege is needed in order to configure and run SmartSync data mover policies. While file-to-file replication requires SmartSync to be running on both source and target clusters, for OneFS Cloud Copy to transfer to/from cloud storage, only the OneFS 9.4 cluster requires the SmartSync data mover. No data mover needed on the cloud systems. Be aware that the inbound TCP 7722 IP port must be open across any intermediate gateways and firewalls to allow SmartSync replication to occur.
Under the hood, replication is handled by the ‘isi_dm_d’ service, which is disabled by default, and needs to be enabled prior to configuring and using SmartSync. SmartSync uses TLS (transport layer security, or SSL) and, as such, requires trust to be established between the source and target clusters. In addition to a Certificate Authority (CA) and Certificate Identity (CI) for authorization and authentication, both clusters also require encryption to be enabled in order for the isi_dm_d service to run. The best practice is to use a local CA to sign each cluster’s CI, but self-signed certificates can be used instead in the absence of a suitable CA.
The SmartSync Datamover has a purpose-build, integrated job execution engine, and Datamovers are executed on each cluster node in cooperative mode.
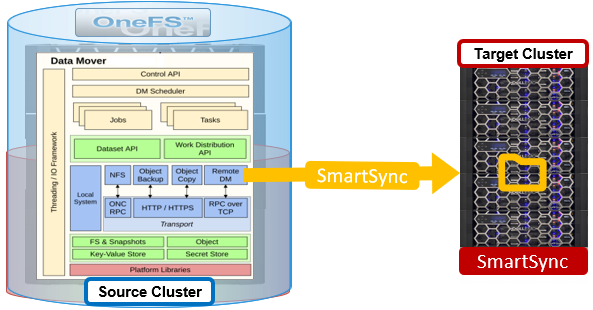
Shared Key-Value Stores (KVS) are used for jobs/tasks distribution, and extra indexing is implemented for quick lookups by task state, task type, and alive time. There are no dependencies or communication between tasks, and job cancellation and pausing is handled by posting a ‘request’ into a job record (request polling).
Within the SmartSync hierarchy, accounts define the connections to remote systems, policies define the replication configurations, and jobs perform the work:
| Component | Details |
| Accounts | Datamover accounts:
– URI, eg. dm://remotenas.isln.com:7722 – Local and remote network pools defining nodes/interfaces to use for data transfer – Client and server certificates to enable TLS CloudCopy accounts: – Account type (AWS S3, ECS S3, Azure) – URI, eg. https://cloudcluster.isln.com:9002/cloudbucket – Credentials |
| Policies | – Dataset creation policy
– Dataset copy policy – Dataset repeat copy policy – Dataset expiration policy |
| Jobs | Runtime entities created based on policies schedules. There are two major types of data transfer jobs:
– Baseline jobs for initial transfers and – Incremental jobs for subsequent transfers between FILE Datamover systems. |
| Tasks | Spawned by jobs and are the individual chunks of work that a job must perform. No 1-to-1 relationship to their associated files. |
SmartSync Datasets are self-contained, independent entities. Once created, they’re assigned globally-unique IDs, and backed by file system snapshots on PowerScale. Parent-child relationships are used for incremental transfers, and a handshake determines the exact changeset to be transferred.
As demand for replication on a source cluster increases, the additional compute and network load needs to be considered. Multiple targets can generate a significant demand on the source cluster, with replication traffic contending with client workloads as data is pushed to the target. Fortunately, SmartSync allows a target cluster to pull the dataset, thereby minimizing the resource impacts on the source.
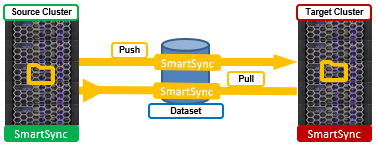
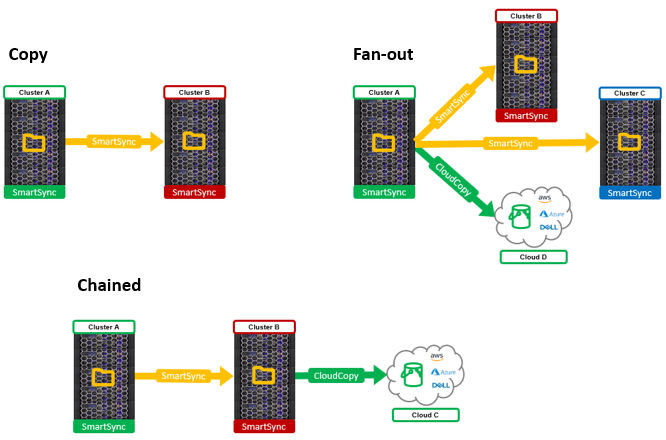
For single-source dataset environments with numerous targets, push replication can be incredibly useful, allowing the source cluster’s resources to be focused on client IO. In addition to both push and pull replication, SmartSync also supports a variety of topologies, such as fan-out, chaining, etc.
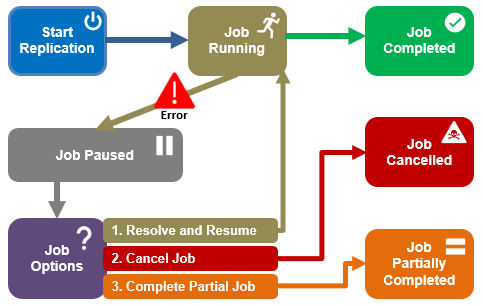
SmartSync provides enhanced replication failure resilience, minimizing replication times even when a job runs into an error. Rather than failing an entire replication job if an error is encountered, requiring a manual restart, SmartSync instead places the job into a paused state, and presents three options:
- Cancel the job altogether.
- Resolve the errors and resume the job.
- Complete a partial replication.
With option 3, the portion of the dataset already transferred is retained, thereby decreasing the subsequent job’s work and execution time.
The SmartSync architecture intentionally decouples source cluster snapshot creation (dataset creation) from the actual data replication transfer to the target, allowing each to run independently via separate configured policies configured for each. This helps mitigate the disruptive chain effect of a failure during the snapshot process early in the process. Additionally, SmartSync offers parent-child policies which launch a replication job only after successful snapshot creation, providing an alternative to recurrence in situations where it’s unclear how long a previous policy may take to complete.
With SmartSync, ‘re-baselining’ (full-resync) is not required for source-target clusters which already contain an earlier version of a dataset. For example, in the following three-cluster DR topology, cluster A replicates to B, and B replicates to C:
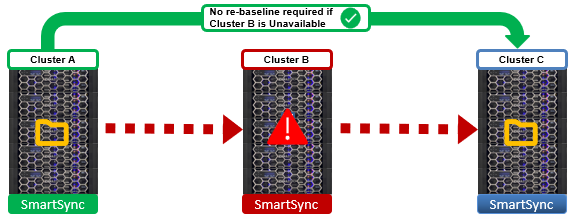
A parent-child relationship means that, if cluster B becomes unavailable, the cluster A to C policy would not require a new baseline. Instead, clusters A and C’s datasets are compared via a handshake, enabling only the changed data blocks to be transferred, thereby minimizing replication overhead. This is particularly beneficial for environments with large datasets, significantly shrinking RPO and RTO times and increasing DR readiness.
When setting up a SmartSync 3-way relationship, be sure to use a single dataset creation policy when configuring datasets on the same path. If there are separate dataset creation policies for each relationship, B and C will have different datasets (snapshots) with different dataset IDs. In this case, if A dies it would be impossible to establish an incremental sync relationship between B on C on those datasets, since the incremental transfer won’t be able to ‘connect’ the dataset IDs between B and C.
SmartSync allows subsequent incremental data movement by managing and re-transferring failed file transfers. Similarly, Dataset reconnect enables systems with common base datasets to establish instant incremental syncs. SmartSync also proactively locks the SnapshotIQ snapshots it generates, providing better protection and separation between Datamover and other cluster snapshots.
Other SmartSync features and functionality includes:
| Feature | Details |
| Bandwidth throttling | Set of netmask rules. Limits are per-node. |
| CPU throttling | Allowed and Backoff CPU percentages. |
| Base policies | Template providing common values to groups of related policies (schedule, source base path, enable/disable, etc). Ie. Disabling base policy affects all linked concrete policies. |
| Concrete policy | Predefined set of fields from the base policy |
| Incremental reconnect | Ability to run incrementals between systems with common base datasets but no prior replication relationship |
| Unconnected nodes (NANON) | Active accounts are monitored by each node. No work allocation to nodes without network access. |
| Snapshot locking | Avoids accidental snapshot deletion, with subsequent re-base-lining. |
SmartSync allows subsequent incremental data movement by managing and re-transferring failed file transfers. Similarly, Dataset reconnect enables systems with common base datasets to establish instant incremental syncs. SmartSync also proactively locks the SnapshotIQ snapshots it uses, providing better separation between Datamover and other snapshots.
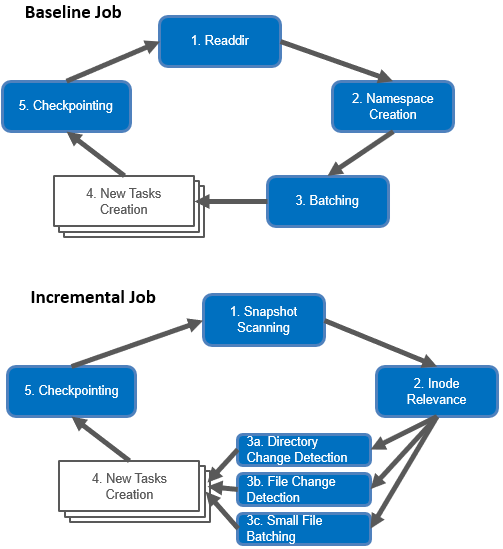
Performance-wise, SmartSync is powered by a scalable run-time engine, spanning the cluster, and which spins up threads (fibers) on demand and uses asynchronous IO to process replication tasks (chunks). Batch operations are used for efficient small file, attribute, and data block transfer. Namespace contention avoidance, efficient snapshot utilization, and separation of dataset creation from transfer are salient design features of the both the baseline and incremental sync algorithms. Plus, the availability of a pull transfer model can significantly reduce the impact on a source cluster, if needed.
The streamlined baseline and incremental file transfer jobs operates as follows:
On the CloudCopy side, the SmartSync copy format provides both regular file representation, browsability and usability of file system data in the cloud. That said, as compared to the file-to-file Datamover, there are certain CloudCopy considerations and limitations to be aware of, such as no incremental copy. These also include:
| CloudCopy Caveats | Details |
| ADS files | Skipped when encountered. |
| Hardlinks | An object will be created for each link (ie. links are not preserved). |
| Symlinks | Skipped when encountered. |
| Directories | An object is created for each directory. |
| Special files | Skipped when encountered. |
| Metadata | Only POSIX mode bits, UID, GID, atime, mtime, ctime are preserved. |
| Filename encodings | Converted to UTF-8. |
| Path | Path relative to root copy directory is used as object key. |
| Large files | An error is returned for files larger than the cloud providers maximum object size. |
| Long filenames | File names exceeding 256 bytes are compressed. |
| Long paths | Junction points are created when paths exceed 1024 bytes to redirect where objects are being stored |
| Sparse files | Sparse sections are not preserved and are written out fully as zeros. |
As mentioned earlier, there are also some prerequisites to address before running SmartSync. First, the source and target(s) must be running OneFS 9.4 and with SyncIQ licensed across the cluster. Additionally, the identity certificates and a shared CA must be present to communicate with a peer Datamover.
In the next article in this series, we’ll turn our attention to the configuration and use of SmartSync.