File Pools is the SmartPools logic layer, where user-configurable policies govern where data is placed, protected, accessed, and how it moves among the Node Pools and Tiers.
File Pools allow data to be automatically moved from one type of storage to another within a single cluster to meet performance, space, cost or other requirements, while retaining its data protection settings. For example a File Pool policy may dictate anything written to path /ifs/data/hpc/ lands on an F600 node pool, then moves to an A200 node pool when it becomes older than four weeks.
To simplify management, there are defaults in place for Node Pool and File Pool settings which handle basic data placement, movement, protection and performance. Also provided are customizable template policies which are optimized for archiving, extra protection, performance, etc.
When a SmartPools job runs, the data may be moved, undergo a protection or layout change, etc. Within a File Pool, SSD Strategies can be configured to place either one copy or all of that pool’s metadata – or even some of its data – on SSDs in that pool. Alternatively, a pool’s SSDs can be turned over for use by L3 cache instead.
Overall system performance impact can be configured to suit the peaks and lulls of an environment’s workload. Change the time or frequency of any SmartPools job and the amount of resources allocated to SmartPools. For extremely high-utilization environments, a sample File Pool policy template can be used to match SmartPools run times to non-peak computing hours.
File pool policies can be used to broadly control the three principal attributes of a file, namely:
- Where a file resides.
- Tier
- Node Pool
- The file performance profile (I/O optimization setting).
- Sequential
- Concurrent
- Random
- SmartCache write caching
- The protection level of a file.
- Parity protected (+1n to +4n, +2d:1n, etc)
- Mirrored (2x – 8x)
A file pool policy is built on a file attribute the policy can match on. The attributes a file Pool policy can use are any of: File Name, Path, File Type, File Size, Modified Time, Create Time, Metadata Change Time, Access Time or User Attributes.
Once the file attribute is set to select the appropriate files, the action to be taken on those files can be added – for example: if the attribute is File Size, additional settings are available to dictate thresholds (all files bigger than… smaller than…). Next, actions are applied: move to Node Pool ‘x’, set to protection level ‘y’, and lay out for access setting ‘z’.
| File Attribute | Description |
| File Name | Specifies file criteria based on the file name |
| Path | Specifies file criteria based on where the file is stored |
| File Type | Specifies file criteria based on the file-system object type |
| File Size | Specifies file criteria based on the file size |
| Modified Time | Specifies file criteria based on when the file was last modified |
| Create Time | Specifies file criteria based on when the file was created |
| Metadata Change Time | Specifies file criteria based on when the file metadata was last modified |
| Access Time | Specifies file criteria based on when the file was last accessed |
| User Attributes | Specifies file criteria based on custom attributes – see below |
‘And’ and ‘Or’ operators allow for the combination of criteria within a single policy for extremely granular data manipulation.
File Pool Policies that dictate placement of data based on its path force data to the correct disk on write directly to that Node Pool without a SmartPools job running. File Pool Policies that dictate placement of data on other attributes besides path name get written to Disk Pool with the highest available capacity and then moved, if necessary to match a File Pool policy, when the next SmartPools job runs. This ensures that write performance is not sacrificed for initial data placement.
Any data not covered by a File Pool policy is moved to a tier that can be selected as a default for exactly this purpose. If no pool has been selected for this purpose, SmartPools will default to the Node Pool with the most available capacity.
When a SmartPools job runs, it runs all the policies in order. If a file matches multiple policies, SmartPools will apply only the first rule it fits. So, for example if there is a rule that moves all jpg files to a nearline Node Pool, and another that moves all files under 2 MB to a performance tier, if the jpg rule appears first in the list, then jpg files under 2 MB will go to nearline, NOT the performance tier. As mentioned above, criteria can be combined within a single policy using ‘And’ or ‘Or’ so that data can be classified very granularly. Using this example, if the desired behavior is to have all jpg files over 2 MB to be moved to nearline, the File Pool policy can be simply constructed with an ‘And’ operator to cover precisely that condition.
Policy order, and policies themselves, can be easily changed at any time. Specifically, policies can be added, deleted, edited, copied and re-ordered.
Say, for example, an organization wants their active data on performance nodes in Tier_1, and to move any data unchanged for 6 months to Tier_2. So as not to contend with production workloads, the SmartPools job needs to be scheduled to run daily during off-hours (12am – 6pm).
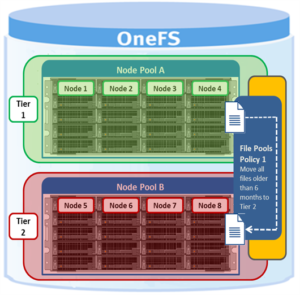
The following CLI syntax will create a file pool policy ‘archive_old’, which finds any files that haven’t been change for six months or more, and moves them to the ‘Archive_1’ tier:
# isi filepool policies create archive_old --data-storage-target Tier_2 --data-ssd-strategy avoid --begin-filter --file-type=file --and --changed-time=6M --operator=lt --end-filter
Or from the WebUI:
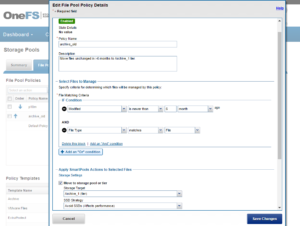
The ‘archive_old’ policy is shown in the file pool policies list as enabled:

The SmartPools job that executes the policy can be scheduled from the WebUI as follows – in this case to run during the workflow quiet hours of 12am to 6am each day:
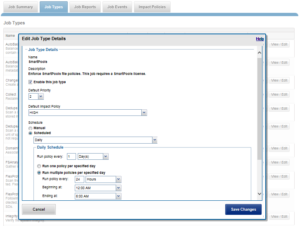
Note: The default schedule for the SmartPools job is every day at 10pm, and with a low impact policy.
File Pool policies can be created, copied, modified, prioritized or removed at any time. Sample policy templates are also provided that can be used as is or as templates for customization. These include:
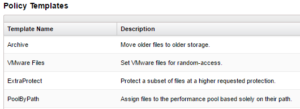
SmartPools currently supports up to 128 file pool policies, and as this list of policies grows, it becomes less practical to manually walk through all of them to see how a file will behave when policies are applied.
When the SmartPools file pool policy engine finds a match between a file and a policy, it stops processing policies for that file, since the first policy match determines what will happen to that file. Next, SmartPools checks the file’s current settings against those the policy would assign to identify those which do not match. Once SmartPools has the complete list of settings that need to apply to that file, it sets them all simultaneously, and moves to restripe that file to reflect any and all changes to Node Pool, protection, SmartCache use, layout, etc.