Exploring the Data Lakehouse and PaaS Data Warehouse
This marks the last article in a series where we’ve delved into the world of the data lakehouse, examining it independently and as a potential substitute for the data warehouse. In case you missed the first article, you can find it here.
In our previous discussions, we often portrayed the data warehouse as a bit of a strawman. We mainly compared the data lakehouse with traditional data warehouse setups, almost as if the concepts of the cloud-native approach hadn’t been applied to data warehouses. It’s like imagining data warehouse architecture is frozen in time.
However, I haven’t really touched on the platform-as-a-service (PaaS) or query-as-a-service (QaaS) data warehouse so far. I haven’t explored these approaches as innovative setups comparable in capabilities and cloud-friendly nature to the equally novel data lakehouse.
Although not explicitly discussed before, this idea has lingered in the background. In a previous article, I highlighted that data warehouse architecture is more of a technical guideline than a strict technology rulebook. Instead of specifying how to build a data warehouse, it outlines what the system should do and how it should behave, detailing the necessary features and capabilities.
This implies that there are multiple ways to implement a data warehouse, and the requirements of data warehouse architecture don’t necessarily clash with those of cloud-native design. Moreover, the cloud-native data warehouse shares quite a few commonalities with the data lakehouse, even as it diverges in crucial aspects.
With this foundation, let’s now shift our focus to the ultimate questions of this series: What similarities exist between the data lakehouse and the PaaS data warehouse, and where do they differ?
PaaS Data Warehouse: A Lot Like Data Lakehouse
The PaaS data warehouse and the data lakehouse share many similarities. Just like the data lakehouse, the PaaS data warehouse:
- Resides in the cloud.
- Separates its computing, storage, and other resources.
- Can adjust its size based on demand spikes, seasonal use, or specific events.
- Responds to events by provisioning or removing compute and storage resources.
- Locates itself close to other cloud services, including the data lake.
- Writes and reads data from cost-effective cloud object storage, similar to the data lake/house.
- Can query and provide access to data in various zones of the data lake.
- Doesn’t necessarily need complex data modeling, opting for flat or OBT schemas.
- Handles semi- and multi-structured data, managing and performing operations on them.
- Executes queries across diverse data models like time-series, document, graph, and text.
- Presents denormalized views (models) for specific use cases and applications.
- Offers various RESTful endpoints, not just SQL.
- Supports GraphQL, Python, R, Java, and more through distinct APIs or language-specific SDKs.
Tighter Connections in PaaS Data Warehouse
When we look at the cloud-native data warehouse compared to the data lakehouse, it appears more tightly connected. This means the cloud-native warehouse has better control over various tasks like reading, writing, scheduling, distributing, and performing operations on data. It can also handle dependencies between these operations and ensure consistency, uniformity, and replicability safeguards. In simpler terms, it can enforce strict ACID safeguards.
On the other hand, the “ideal” data lakehouse is constructed from separate, purpose-specific services. For instance, this ideal implementation includes a SQL query service on top of a data lake service, which sits on a cloud object storage service. This design trend breaks down large programs into smaller, function-specific services that interact with minimal knowledge about each other. While this approach offers benefits, especially in terms of design flexibility, it also introduces challenges in managing concurrent computing, as discussed in the third article of this series.
Solving this problem in an ideal data lakehouse implementation is not straightforward. Databricks takes a different approach by coupling the data lake and data lakehouse into a single platform. This way, the data lakehouse can potentially enforce ACID-like safeguards. However, this also means tightly coupling the data lakehouse and the data lake, creating a dependence on a single software platform and provider.
Comparing Data Warehouse and Data Lakehouse: A Closer Look
Now, let’s explore a thought-provoking question: Can the PaaS data warehouse perform all the functions of the data lakehouse? It’s a possibility. Consider this: What sets apart a SQL query service that interacts with data in the curated zone of a data lake from a PaaS data warehouse in the same cloud environment, with access to the same underlying cloud object storage service, and the ability to perform similar tasks? What distinguishes a SQL query service offering access to data in the lake’s archival, staging, and other zones from a PaaS data warehouse capable of the same?
Over time, it seems like the data lake and the data warehouse have been moving closer together. On one side, the lakehouse appears to exemplify convergence from lake to warehouse. On the flip side, the warehouse’s support for various data models and its integration with data federation and multi-structured query capabilities—meaning the capability to query files, objects, or diverse data structures—are examples of a trend moving from warehouse to lake.
Let’s delve into some supposed differences between the data lakehouse and the data warehouse and examine if convergence has rendered these differences obsolete. Here are a few notable ones to consider:
Comparing Data Warehouse and Data Lakehouse Features: A Simplified View
- Enforcing Safeguards:
- Original: Has the ability to enforce safeguards to ensure the uniformity and replicability of results.
- Simplified: The PaaS data warehouse easily ensures consistent and replicable results.
- Performing Core Workloads:
- Original: Has the ability to perform core data warehousing workloads.
- Simplified: The PaaS data warehouse excels at essential data processing tasks, making it faster than a SQL query service.
- Data Modeling Requirement:
- Original: Eliminates the requirement to model and engineer data structures prior to storage.
- Simplified: Both PaaS data warehouse and data lakehouse benefit from basic data modeling for clarity, governance, and reuse.
- Protection Against Lock-In:
- Original: Protects against cloud-service-provider lock-in.
- Simplified: While the data lakehouse aims for flexibility, switching services may involve challenges like transferring modeling logic and data movement.
- Diverse Practices and Consumers:
- Original: Has the ability to support a diversity of practices, use cases, and consumers.
- Simplified: The data lake offers more flexibility and convenience for experimenting with data, giving it an advantage over the data warehouse.
- Querying Across Data Models:
- Original: Has the ability to query against/across multiple data models.
- Simplified: Both data lakehouse and PaaS data warehouse can query diverse data models, but challenges exist in linking information across models.
In summary, while the PaaS data warehouse and data lakehouse share some capabilities, they also have unique strengths and challenges in areas like flexibility, data modeling, and querying across different data models.
Final Thoughts on the Complementary Data Lakehouse
Let’s not underestimate the value of the data lakehouse—it’s a useful innovation. The compelling use cases we discussed earlier in this series are hard to dispute. Using the data lakehouse can be easier for time-sensitive, unpredictable, or one-off tasks, as it allows for quick action without being hindered by internal constraints.
Unlike the data warehouse, which is a strictly governed system with a slow turnaround, the data lakehouse has its advantages. It offers a less strictly governed, more agile alternative. In simpler terms, the lakehouse is not here to replace the warehouse but to complement it.
The challenges discussed in this article and its counterparts arise when trying to replace the data warehouse with the data lakehouse. In this particular aspect, the data lakehouse falls short. It’s tough, if not impossible, to find a perfect solution that aligns the design requirements of an ideal data lakehouse with the technical needs of data warehouse architecture.
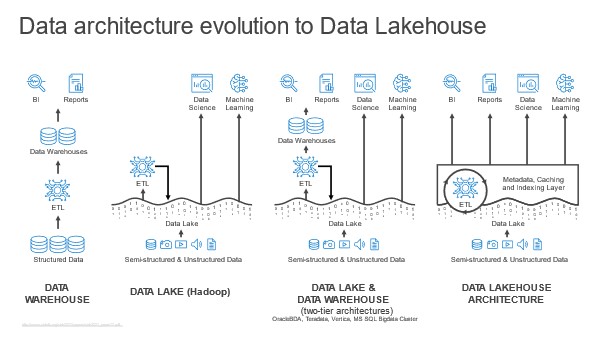
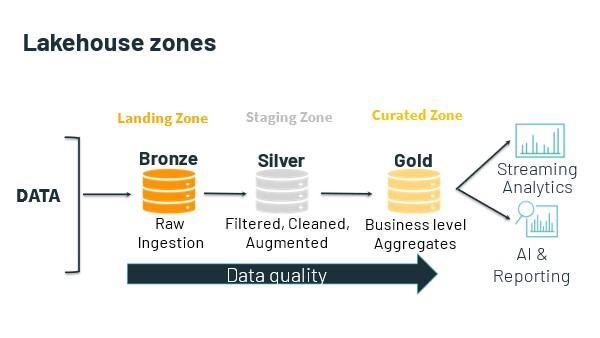 Usually, the data lake is home to all an organization’s useful data. This data is already there. So, the data lakehouse begins with query against this data where it lives.
Usually, the data lake is home to all an organization’s useful data. This data is already there. So, the data lakehouse begins with query against this data where it lives.