As we’ve seen previously, OneFS utilizes file system scans to perform such tasks as detecting and repairing drive errors, reclaiming freed blocks, etc. These scans are typically complex sequences of operations, so they are implemented via syscalls and coordinated by the Job Engine. These jobs are generally intended to run as minimally disruptive background tasks in the cluster, using spare or reserved capacity.
The file system maintenance jobs which are critical to the function of OneFS are:
| FS Maintenance Job | Description |
| AutoBalance | Restores node and drive free space balance |
| Collect | Reclaims leaked blocks |
| FlexProtect | Replaces the traditional RAID rebuild process |
| MediaScan | Scrub disks for media-level errors |
| MultiScan | Run AutoBalance and Collect jobs concurrently |
MediaScan’s role within the file system protection framework is to periodically check for and resolve drive bit errors across the cluster. This proactive data integrity approach helps guard against a phenomenon known as ‘bit rot’, and the resulting specter of hardware induced silent data corruption.
The MediaScan job reads all of OneFS’ allocated blocks in order to trigger any latent drive sector errors in a process known as ‘disk scrubbing’. Drive sectors errors may occur due physical effects which, over time, could negatively affect the protection of the file system. Periodic disk scrubbing helps ensure that sector errors do not accumulate and lead to data integrity issues.
Sector errors are a relatively common drive fault. They are sometimes referred to as ‘ECCs’ since drives have internal error correcting codes associated with sectors. A failure of these codes to correct the contents of the sector generates an error on a read of the sector.
ECCs have a wide variety of causes. There may be a permanent problem such as physical damage to platter, or a more transient problem such as the head not being located properly when the sector was read. For transient problems, the drive has the ability to retry automatically. However, such retries can be time consuming and prevent further processing.
OneFS typically has the redundancy available to overwrite the bad sector with the proper contents. This is called Dynamic Sector Repair (DSR). It is preferable for the file system to perform DSR than to wait for the drive to retry and possibly disrupt other operations. When supported by the particular drive model, a retry time threshold is also set so that disruption is minimized and the file system can attempt to use its redundancy.
In addition, MediaScan maintains a list of sectors to avoid after an error has been detected. Sectors are added to the list upon the first error. Subsequent I/Os consult this list and, if a match is found, immediately return an error without actually sending the request to the drive, minimizing further issues.
If the file system can successfully write over a sector, it is removed from the list. The assumption is that the drive will reallocate the sector on write. If the file system can’t reconstruct the block, it may be necessary to retry the I/O since there is no other way to access the data. The kernel’s ECC list must be cleared. This is done at the end of the MediaScan job run, but occasionally must also be done manually to access a particular block.
The drive’s own error-correction mechanism can handle some bit rot. When it fails, the error is reported to the MediaScan job. In order for the file system to repair the sector, the owner must be located. The owning structure in the file system has the redundancy that can be used to write over the bad sector, for example an alternate mirror of a block.
Most of the logic in MediaScan handles searching for the owner of the bad sector; the process can be very different depending on the type of structure, but is usually quite expensive. As such, it is often referred to as the ‘haystack’ search, since nearly every inode may be inspected to find the owner. MediaScan works by directly accessing the underlying cylinder groups and disk blocks via a linear drive scan and has more job phases than most job engine jobs for two main reasons:
- First, significant effort is made to avoid the expense of the haystack search.
- Second, every effort is made to try all means possible before alerting the administrator.
Here are the eight phases of MediaScan:
| Phase # | Phase Name | Description |
| 1 | Drive Scan | Scans each drive using the ifs_find_ecc() system call, which issues I/O for all allocated blocks and inodes. |
| 2 | Random Drive Scan | Find additional “marginal” ECCs that would not have been detected by the previous phase. |
| 3 | Inode Scan | Inode ECCs can be located more quickly from the LIN tree, so this phase scans the LIN tree to determine the (LIN, snapshot ID) referencing any inode ECCs. |
| 4 | Inode Repair | Repairs inode ECCs with known (LIN, snapshot ID) owners, plus any LIN tree block ECCs where the owner is the LIN tree itself. |
| 5 | Inode Verify | Verifies that any ECCs not fixed in the previous phase still exist. First, it checks whether the block has been freed. Then it clears the ECC list and retries the I/O to verify that the sector is still failing. |
| 6 | Block Repair | Drives are scanned and compared against the list of ECCs. When ECCs are found, the (LIN, snapshot ID) is returned and the restripe repairs ECCs in those files. This phase is often referred to as the “haystack search”. |
| 7 | Block Verify | Once all file system repair attempts have completed, ECCs are again verified by clearing the ECC list and reissuing I/O. |
| 8 | Alert | Any remaining ECCs after repair and verify represent a danger of data loss. This phase logs the errors at the syslog ERR level. |
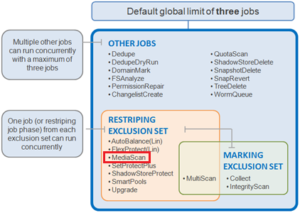
MediaScan falls within the job engine’s restriping exclusion set, and is run as a low-impact, low-priority background process. It is executed automatically by default at 12am on the first Saturday of each month, although this can be reconfigured if desired.
In addition to scheduled job execution, MediaScan can also be initiated on demand. The following CLI syntax will kick off a manual job run:
# isi job jobs start mediascan Started job [251] # isi job jobs list ID Type State Impact Pri Phase Running Time -------------------------------------------------------- 251 MediaScan Running Low 8 1/8 1s -------------------------------------------------------- Total: 1
The MediaScan job’s progress can be tracked via a CLI command as follows:
# isi job jobs view 251 ID: 251 Type: MediaScan State: Running Impact: Low Policy: LOW Pri: 8 Phase: 1/8 Start Time: 2020-11-23T22:16:23 Running Time: 1m 30s Participants: 1, 2, 3 Progress: Found 0 ECCs on 2 drives; last completed: 2:0; 0 errors Waiting on job ID: - Description:
A job’s resource usage can be traced from the CLI as such:
# isi job statistics view Job ID: 251 Phase: 1 CPU Avg.: 0.21% Memory Avg. Virtual: 318.41M Physical: 28.92M I/O Ops: 391 Bytes: 3.05M
Finally, upon completion, the MediaScan job report, detailing all eight stages, can be viewed by using the following CLI command with the job ID as the argument:
# isi job reports view 251