In addition to the per-job impact controls described in the previous blog article, additional impact management is also provided by the notion of job exclusion sets. For multiple concurrent job execution, exclusion sets, or classes of similar jobs, determine which jobs can run simultaneously. A job is not required to be part of any exclusion set, and jobs may also belong to multiple exclusion sets. Currently, there are two exclusion sets that jobs can be part of:
- Restriping
- Marking.
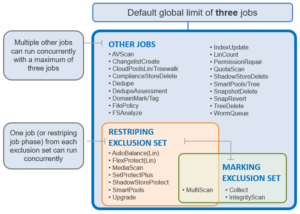
The fundamental responsibility of the jobs within the Job Engine Restripe exclusion set is to ensure that the data on /ifs is:
- Protected at the desired level.
- Balanced across nodes.
- Properly accounted for.
OneFS does this by running various file system maintenance jobs either manually, via a predefined schedule, or based on a cluster event, like a group change. These jobs include:
The FlexProtect job is responsible for maintaining the appropriate protection level of data across the cluster. For example, it ensures that a file which is supposed to be protected at +2, is actually protected at that level.
Run automatically after a drive or node removal or failure, FlexProtect locates any unprotected files on the cluster, and repairs them as quickly as possible. The FlexProtect job includes the following distinct phases:
- Drive Scan. FlexProtect scans the cluster’s drives, looking for files and inodes in need of repair. When one is found, the job opens the LIN and repairs it and the corresponding data blocks using the restripe process.
- LIN Verification. Once the drive scan is complete, the LIN verification phase scans the inode (LIN) tree and verifies, re-verifies and resolves any outstanding re-protection tasks.
- Device Removal. In this final phase, FlexProtect removes the successfully repaired drives(s) or node(s) from the cluster.
In addition to FlexProtect, there is also a FlexProtectLin job. FlexProtectLin is run by default when there is a copy of file system metadata available on solid state drive (SSD) storage. FlexProtectLin typically offers significant runtime improvements over its conventional disk-based counterpart.
Unlike previous releases, in OneFS 8.2 and later FlexProtect does not pause when there is only one temporarily unavailable device in a disk pool, when a device is smartfailed, or for dead devices.
The MultiScan job, which combines the functionality of AutoBalance and Collect, is automatically run after a group change which adds a device to the cluster. AutoBalance(Lin) and/or Collect are only run manually if MultiScan has been disabled.
Scalability enhancements in OneFS 8.2 and later mean that fewer group change notifications are received. This results in MultiScan being triggered less frequently. To compensate for this, MultiScan is now started when:
- Data is unbalanced within one or more disk pools, which triggers MultiScan to start the AutoBalance phase only.
- When drives have been unavailable for long enough to warrant a Collect job, which triggers MultiScan to start both its AutoBalance and Collect phases.
The goal of the AutoBalance job is to ensure that each node has the same amount of data on it, in order to balance data evenly across the cluster. AutoBalance, along with the Collect job, is run after any cluster group change, unless there are any storage nodes in a “down” state.
Upon visiting each file, AutoBalance performs the following two operations:
- File level rebalancing
- Full array rebalancing
For file level rebalancing, AutoBalance evenly spreads data across the cluster’s nodes in order to achieve balance within a particular file. And with full array rebalancing, AutoBalance moves data between nodes to achieve an overall cluster balance within a 5% delta across nodes.
There is also an AutoBalanceLin job available, which is automatically run in place of AutoBalance when the cluster has a metadata copy available on SSD. AutoBalanceLin provides an expedited job runtime.
The Collect job is responsible for locating unused inodes and data blocks across the file system. Collect runs by default after a cluster group change, in conjunction with AutoBalance, as part of the MultiScan job.
In its first phase, Collect performs a marking job, scanning all the inodes (LINs) and identifying their associated blocks. Collect marks all the blocks which are currently allocated and in use, and any unmarked blocks are identified as candidates to be freed for reuse, so that the disk space they occupy can be reclaimed and re-allocated. All metadata must be read in this phase in order to mark every reference, and must be done completely, to avoid sweeping in-use blocks and introducing allocation corruption.
Collect’s second phase scans all the cluster’s drives and performs the freeing up, or sweeping, of any unmarked blocks so that they can be reused.
MediaScan’s role within the file system protection framework is to periodically check for and resolve drive bit errors across the cluster. This proactive data integrity approach helps guard against a phenomenon known as ‘bit rot’, and the resulting specter of hardware induced silent data corruption.
MediaScan is run as a low-impact, low-priority background process, based on a predefined schedule (monthly, by default).
First, MediaScan’s search and repair phase checks the disk sectors across all the drives in a cluster and, where necessary, utilizes OneFS’ dynamic sector repair (DSR) process to resolve any ECC sector errors that it encounters. For any ECC errors which can’t immediately be repaired, MediaScan will first try to read the disk sector again several times in the hopes that the issue is transient, and the drive can recover. Failing that, MediaScan will attempt to restripe files away from irreparable ECCs. Finally, the MediaScan summary phase generates a report of the ECC errors found and corrected.
The IntegrityScan job is responsible for examining the entire live file system for inconsistencies. It does this by systematically reading every block and verifying its associated checksum. Unlike traditional ‘fsck’ style file system integrity checking tools, IntegrityScan is designed to run while the cluster is fully operational, thereby removing the need for any downtime. In the event that IntegrityScan detects a checksum mismatch, it generates and alert, logs the error to the IDI logs and provides a full report upon job completion.
IntegrityScan is typically run manually if the integrity of the file system is ever in doubt. Although the job itself may take several days or more to complete, the file system is online and completely available during this time. Additionally, like all phases of the OneFS job engine, IntegrityScan can be prioritized, paused or stopped, depending on the impact to cluster operations.
The Job Engine includes a number of feature support jobs are related to and supporting of the operation of OneFS data and storage management modules, including SmartQuotas, SnapshotIQ, SmartPools, SmartDedupe, etc. Each of these modules requires a cluster-wide license to run. In the event that a feature has not been licensed, attempts to start the associated supporting job will fail with the following warning.
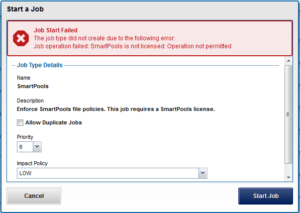
If the SmartPools data tiering product is unlicensed on a cluster, the SetProtectPlus job will run instead, to apply the default file policy. SetProtectPlus is then automatically disabled if SmartPools is activated on the cluster.
Another principle consumer of the SmartPools job and filepool policies is OneFS Small File Storage Efficiency (SFSE). This feature maximizes the space utilization of a cluster by decreasing the amount of physical storage required to house the small files that comprise a typical medical dataset. Efficiency is achieved by scanning the on-disk data for small files, which are protected by full copy mirrors, and packing them in shadow stores. These shadow stores are then parity protected, rather than mirrored, and typically provide storage efficiency of 80% or greater.
If both SmartPools and CloudPools are licensed and both have policies configured, the scheduled SmartPools job will also trigger a CloudPools job when it’s executed. Only the SmartPools job will be visible from the Job Engine WebUI, but the following command can be used to view and control the associated CloudPools jobs:
# isi cloud job <action> <subcommand>
In addition to the standard CloudPools archive, recall, and restore jobs, there are typically four CloudPools jobs involved with cache management and garbage collection, of which the first three are continuously running:
- Cache-writeback
- Cache-invalidation
- Cloud-garbage-collection
- Local-garbage-collection
Similarly, the SmartDedupe data efficiency product has two jobs associated with it. The first, DedupeAssessment, is an unlicensed job that can be run to determine the space savings available across a dataset. And secondly, the SmartDedupe job, which actually performs the data deduplication, and which requires a valid product license key in order to run.