In the final article in this caching series we’ll take a look at some of the L3 cache’s performance benefits and attributes – plus how to size the cache and other considerations and good practices.
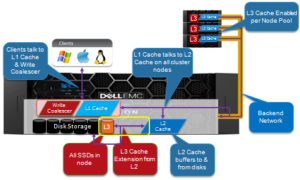
One of the goals of L3 is to deliver solid benefits right out of the box for a wide variety of workloads. However, L3 cache usually provides more benefit for random and aggregated workloads than for sequential and optimized workflows – typically delivering similar IOPS as SmartPools metadata-read strategy, for user data retrieval (reads).
Although the benefit of L3 caching is highly workflow dependent, the following general rules can be assumed:
- During data prefetch operations, streaming requests are intentionally sent directly to the spinning disks (HDDs), while utilizing the L3 cache SSDs for random IO.
- SmartPools metadata-write strategy may be the better choice for metadata write and/or overwrite heavy workloads, for example EDA and certain HPC workloads.
- L3 cache can deliver considerable latency improvements for repeated random read workflows over both non-L3 nodepools and SmartPools metadata-read configured nodepools.
- L3 can also provide improvements for parallel workflows, by reducing the impact to streaming throughput from random reads (streaming meta-data).
- The performance of OneFS job engine jobs can also be increased by L3 cache
L3 cache is enabled by default for Isilon A200, A200 and the older Gen5 NL and HD nodes that contain SSDs, and cannot be disabled. On these platforms, L3 cache runs in a metadata only mode. By storing just metadata blocks, L3 cache optimizes the performance of operations such as system protection and maintenance jobs, in addition to metadata intensive workloads.
Figuring out the size of the active data, or working set, for your environment is the first step in an L3 cache SSD sizing exercise.
L3 cache utilizes all available SSD space over time. As a rule, L3 cache benefits more with more available SSD space. However, sometimes losing spindle count hurts more than adding cache helps a workflow. If possible add a larger capacity SSD rather than multiple smaller SSDs.
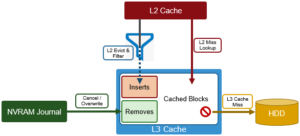
L3 cache sizing involves calculating the correct amount of SSD space to fit the working data set. This can be done by using the isi_cache_stats command to periodically capture L2 cache statistics on an existing cluster.
Run the following commands based on the workload activity cycle, at job start and job end. Initially run isi_cache_stats –c in order to reset, or zero out, the counters. Then run isi_cache_stats –v at workload activity completion and save the output. This will help determine an accurate indication of the size of the working data set, by looking at the L2 cache miss rates for both data and metadata on a single node.
These cache miss counters are displayed as 8KB blocks. So an L2_data_read.miss value of 1024 blocks represents 8 MB of actual missed data.
The formula for calculating the working set size is:
(L2_data_read.miss + L2_meta_read.miss) = working_set size
Once the working set size has been calculated, a good rule of thumb is to size L3 SSD capacity per node according to the following formula:
L2 capacity + L3 capacity >= 150% of working set size.
There are diminishing returns for L3 cache after a certain point. With too high an SSD to working set size ratio, the cache hits decrease and fail to add greater benefit. Conversely, when compared to SmartPools SSD strategies, another benefit of using SSDs for L3 cache is that performance will degrade much more gracefully if metadata does happen to exceed the SSD capacity available.
Repeated random read workloads will typically benefit most from L3 cache via latency improvements. When sizing L3 SSD capacity, the recommendation is to use a small number (ideally no more than two) of large capacity SSDs rather than multiple small SSDs to achieve the appropriate capacity of SSD(s) that will fit your working data set.
When it comes to replacing failed L3 cache SSDs, the same procedure should be employed as for replacing other storage drives. However, L3 cache SSDs do not require FlexProtect or AutoBalance to run post replacement, so it’s typically a much faster process.
For a legacy node pool using a SmartPools metadata-write strategy, the conventional wisdom is to avoid converting it to L3 cache unless:
- The SSDs are seriously underutilized.
- The overall I/O mix has changed and represents a significant drop in metadata write percentage.
- The SSDs in the pool are oversubscribed and spilling over to hard disk.
- Your primary concern is SSD longevity.