OneFS 9.11 sees the addition of a Software journal mirroring capability, which adds critical file system support to meet the reliability requirements for platforms with high capacity drives.
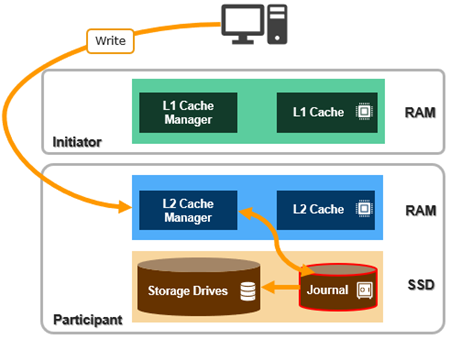
But first, a quick journal refresher… OneFS uses journaling to ensure consistency across both disks locally within a node and disks across nodes. As such, the journal is among the most critical components of a PowerScale node. When OneFS writes to a drive, the data goes straight to the journal, allowing for a fast reply.
Block writes go to the journal first, and a transaction must be marked as ‘committed’ in the journal before a ‘success’ status is returned to the file system operation.
Once a transaction is committed the change is guaranteed to be stable. If the node crashes or loses power, changes can still be applied from the journal at mount time via a ‘replay’ process. The journal uses a battery-backed persistent storage medium in order to be available after a catastrophic node event, and must also be:
| Journal Performance Characteristic | Description |
| High throughput | All blocks (and therefore all data) pass through the journal, so it must never become a bottleneck. |
| Low latency | Since transaction state changes are often in the latency path multiple times for a single operation, particularly for distributed transactions. |
The OneFS journal mostly operates at the physical level, storing changes to physical blocks on the local node. This is necessary because all initiators in OneFS have a physical view of the file system – and therefore issue physical read and write requests to remote nodes. The OneFS journal supports both 512byte and 8KiB block sizes of 512 bytes for storing written inodes and blocks respectively.
By design, the contents of a node’s journal are only needed in a catastrophe, such as when memory state is lost. For fast access during normal operation, the journal is mirrored in RAM. Thus, any reads come from RAM and the physical journal itself is write-only in normal operation. The journal contents are read at mount time for replay. In addition to providing fast stable writes, the journal also improves performance by serving as a write-back cache for disks. When a transaction is committed, the blocks are not immediately written to disk. Instead, it is delayed until the space is needed. This allows the I/O scheduler to perform write optimizations such as reordering and clustering blocks. This also allows some writes to be elided when another write to the same block occurs quickly, or the write is otherwise unnecessary, such as when the block is freed.
So the OneFS journal provides the initial stable storage for all writes and does not release a block until it is guaranteed to be stable on a drive. This process involves multiple steps and spans both the file system and operating system. The high-level flow is as follows:

| Step | Operation | Description |
| 1 | Transaction prep | A block is written on a transaction, for example a write_block message is received by a node. An asynchronous write is started to the journal. The transaction preparation step will wait until all writes on the transaction complete. |
| 2 | Journal delayed write | The transaction is committed. Now the journal issues a delayed write. This simply marks the buffer as dirty. |
| 3 | Buffer monitoring | A daemon monitors the number of dirty buffers and issues the write to the drive upon reach its threshold. |
| 4 | Write completion notification | The journal receives an upcall indicating that the write is complete. |
| 5 | Threshold reached | Once journal space runs low or an idle timeout expires, the journal issues a cache flush to the drive to ensure the write is stable. |
| 6 | Flush to disk | When cache flush completes, all writes completed before the cache flush are known stable. The journal frees the space. |
The PowerScale F-series platforms use Dell’s VOSS M.2 SSD drive as the non-volatile device for their software-defined persistent memory (SDPM) journal vault. The SDPM itself comprises two main elements:
| Component | Description |
| BBU | The BBU pack (battery backup unit) supplies temporary power to the CPUs and memory allowing them to perform a backup in the event of a power loss. |
| Vault | A 32GB M.2 NVMe to which the system memory is vaulted. |
While the BBU is self-contained, the M.2 NVMe vault is housed within a VOSS module, and both components are easily replaced if necessary.
The current focus of software journal mirroring (SJM) are the all-flash F710 and F910 nodes that contain either the 61 TB QLC SSDs, or the soon to be available 122TB drives. In these cases, SJM dramatically improves the reliability of these dense drive platforms. But first, some context regarding journal failure and it’s relation to node rebuild times, durability, and the protection overhead.
Typically, a node needs to be rebuilt when its journal fails, for example if it loses its data, or if the journal device develops a fault and needs to be replaced. To accomplish this, the OneFS SmartFail operation has historically been the tool of choice, to restripe the data away from the node. But the time to completion for this operation depends on the restripe rate and amount of the storage. And the gist is that the denser the drives, the more storage is on the node, and the more work SmartFail has to perform.
And if restriping takes longer, the window during which the data is under-protected also increases. This directly affects reliability, by reducing the mean time to data loss, or MTTDL. PowerScale has an MTTDL target of 5,000 years for any given size of a cluster. The 61TB QLC SSDs represent an inflection point for OneFS restriping, where, due to their lengthy rebuild times, reliability, and specifically MTTDL, become significantly impacted.
So the options in a nutshell for these dense drive nodes, are either to:
- Increase the protection overhead, or:
- Improve a node’s resilience and, by virtue, reduce its failure rate.
Increasing the protection level is clearly undesirable, because the additional overhead reduces usable capacity and hence the storage efficiency – thereby increasing the per-terabyte cost, as well as reducing rack density and energy efficiency.
Which leaves option 2: Reducing the node failure rate itself, which the new SJM functionality in 9.11 achieves by adding journal redundancy.
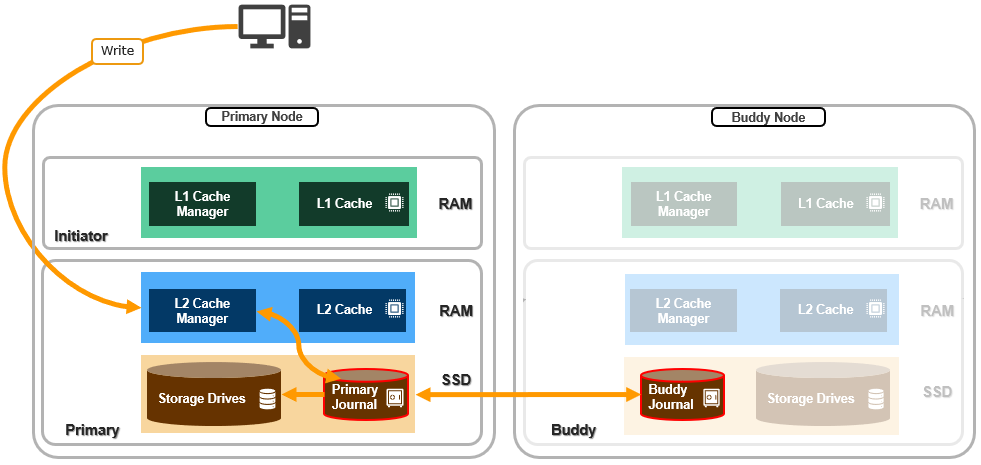
So, by keeping a synchronized and consistent copy of the journal on another node, and automatically recovering the journal from it upon failure, enabling SJM can reduce the node failure rate by around three orders of magnitude – while removing the need for a punitively high protection level on platforms with large-capacity drives.
SJM is enabled by default for the applicable platforms on new clusters. So for clusters including F710 or F910 nodes with large QLC drives that ship with 9.11 installed, SJM will be automatically activated.
SJM adds a mirroring scheme, which provides the redundancy for the journal’s contents. This is where /ifs updates are sent to a node’s local, or primary, journal as usual. But they’re also synchronously replicated, or mirrored, to another node’s journal, too – referred to as the ‘buddy’.
This is somewhat analogous to how the PowerScale H and A-series chassis-based node paring operates, albeit in software and over the backend network this time, and with no fixed buddy assignment, rather than over a dedicated PCIe non-transparent bridge link to a dedicated partner node, as in the case of the chassis-based platforms.
Every node in an SJM-enabled pool is dynamically assigned a buddy node. And similarly, if a new SJM-capable node is added to the cluster, it’s automatically paired up with a buddy. These buddies are unique for every node in the cluster.
SJM’s automatic recovery scheme can use a buddy journal’s contents to re-form the primary node’s journal. And this recovery mechanism can also be applied manually if a journal device needs to be physically replaced.
A node’s primary journal lives within that node, next to its storage drives. In contrast, the buddy journal lives on a remote node and stores sufficient information about transactions on the primary, to allow it to restore the contents of a primary node’s journal in the event of its failure.
SyncForward is the process that enables a stale Buddy journal to reconcile with the Primary and any transactions that it might have missed. Whereas SyncBack, or restore, allows a blown Primary journal to be reconstructed from the mirroring information stored in its Buddy journal.
The next blog article in this series will dig into SJM’s architecture and management in a bit more depth.